또 다시 돌아온 그녀석 ㅎ 이번엔 따끈따끈한 신작 ICCV2021 입니다. Self-supervised 에 대한 분석 논문이라고 할 수 있겠는데요. 저희 논문에 실릴 수 있는 분석이 있을까 싶어서 읽어보게 되었습니다. Monodepth2 가 나온 후 논문들이 굉장히 중구난방식으로 나오고 pair comparison을 위해서 모든 backbone을 resnet18로 고정함에 따라서 CNN의 potential을 아직 다 보지 못하는 등 현재 Self-supervised monocular depth estimation의 문제점을 다시 보며 그걸 고려해서 기존의 문제점을 고쳤을때 성능 향상을 보였다고 합니다. 좀 더 자세히 논문 리뷰시작하도록 하겠습니다.
이 논문에서 현재 Self-supervised monocular depth estimation(Self-MDE) 연구들의 문제라고 꼽은 것은 두가지 입니다. 1) 현재 나온 각각의 연구 노력은 별개의 작업이며 이들 간의 상호 의존성은 떨어지며. 이는 결과적으로 Self-MDE에 대한 연구는 제안된 방법 간의 잠재적인 시너지 효과를 아직 완전히 달성하지 못했습니다. 2) 일반적으로 기존 연구는 제안된 학습 방법의 공정한 비교를 위해 동일한 CNN 아키텍처를 채택했습니다. 결과적으로 아키텍처 요인의 영향을 조사하고 아키텍처 이점을 얻을 필요성이 남아 있습니다.
위의 두가지를 해결하기 위해서 이 논문은 Self-MDE를 총 네가지(depth representation, illumination variation, occlusion and dynamic objects)로 분류해 분석을 하고 CNN architecture에 따른 성능을 분석했다고 합니다.
이 논문에서 분석한 것을 크게 요약하면 다음과 같습니다.
- 올바른 깊이 표현을 선택하면 성능향상이 있음.
- 모든 방식이 동일한 학습 방식을 따르는 것이아닌 각각에 따라서 다름
- auto-masking과 motion map의 dynamic object 제거의 영향력은 실로 엄청나다.
- CNN의 변할때마다 성능 향상이 뚜렷함
- depth consistency와 성능은 trade-off 관계에 있다.
위 분석을 도출해 최종적으로 기존 Model 들보다 좋은 SoTA를 달성했다고 합니다.
- Methodology
위에서 말했듯이 이 논문에서는 Self-MDE의 문제를 정의하고 각 문제들을 비교하며 최적의 조합을 찾는것을 목표로 합니다. 그래서 먼저 각 문제들에 대해 현재 연구 방법론들은 어떻게 되는지 설명을 해주며 method 에서 설명한 것들을 이용해 실험에서 ablation study를 진행합니다.
1.1 Depth Representation
실제 깊이 값을 그대로 딥러닝 네트워크가 예측하기에는 스케일이 너무 크기 때문에 안정적으로 학습하기 위해서는 깊이 표현을 잘 선택해야 합니다. 그럼 현재 제안된 깊이 표현 방법론이 어떤 것이 있는지는 아래와 같습니다.
- disparity는 가장 간단한 inverse depth 형태입니다. 깊의의 반전된 값으로 인해서 멀리있는 물체는 안정적으로 표현하지만 가까운 물체에 대해서는 불안정한 표현을 합니다. 식은 아래와 같습니다.
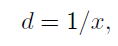
- 다음은 monodepth2가 제안한 scaled disparity입니다. 예측된 깊이를 고정된 scale로 변환한 후 inverse하는 형태이며 식은 아래와 같습니다.
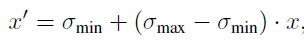
- 마지막으로 softplus로0값이 예측되는 것을 막을 수 있으며 CNNs가 보다 균일한 예측을 하도록 도와주며 식은 아래와 같습니다.
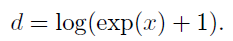
1.2 Illumination Variation
Self-supervised 는 synthesized image를 생성해 target image 와 비교해서 학습하는 방식으로 두 영상을 어떻게 비교하는지가 학습의 방향성을 결정하게 됩니다. 이때 비교방식으로 제안된 방법론은 다음과 같습니다.
- 먼저 brightness transformation으로 단순히 두 영상의 변한 관계의 파라미터를 학습하는 것으로 보다 향상된 결과를 얻을 수 있었다하며 두 영상을 정의 하는 방식은 아래 식과 같습니다.
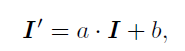
- SSIM 입니다. 영상 비교하는 방법론에서는 정말 많이 사용하는 방법론으로 두영상의 구조, 명암, 밝기 전부 지역적으로 비교할 수 있어서 많이 사용합니다.
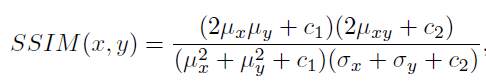
- Depth error weighted SSIM으로 예측된 Depth 와 source 영상의 depth를 warping해서 비교하는 방식으로 예측된 depth를 이용하기 때문에 보다 정확한 학습이된다고합니다.
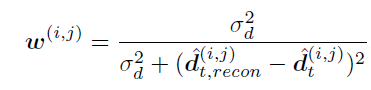
1.3 Occlusion
Occulusion으로 인해서 두 영상의 pixel 비교가 무의미해지고 오히려 학습이 안되는 문제가 발생하기 때문에 어떻게 하면 occluded pixel을 찾아 낼까가 중요한 학습 방식입니다.
- Minimum projection (MR) : monodepth2 에서 제안된 것으로 source 영상들에서 구한 loss들중 min loss를 backward 해서 최대한 occluded pixel을 막아보는 방식이며 식은 아래와 같다.
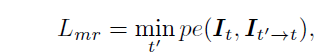
- Depth consistency: Depth in the wild 논문은 intricsic parameter와 extrinsic parameter를 모두 구해서 생성된 영상을 reprojection을 시킬 수 있으며 이를 통해서 reprojection 시킨 pixel의 값이 너무 다르면 occluded pixel이라 판단하는 것이다.
Experiments
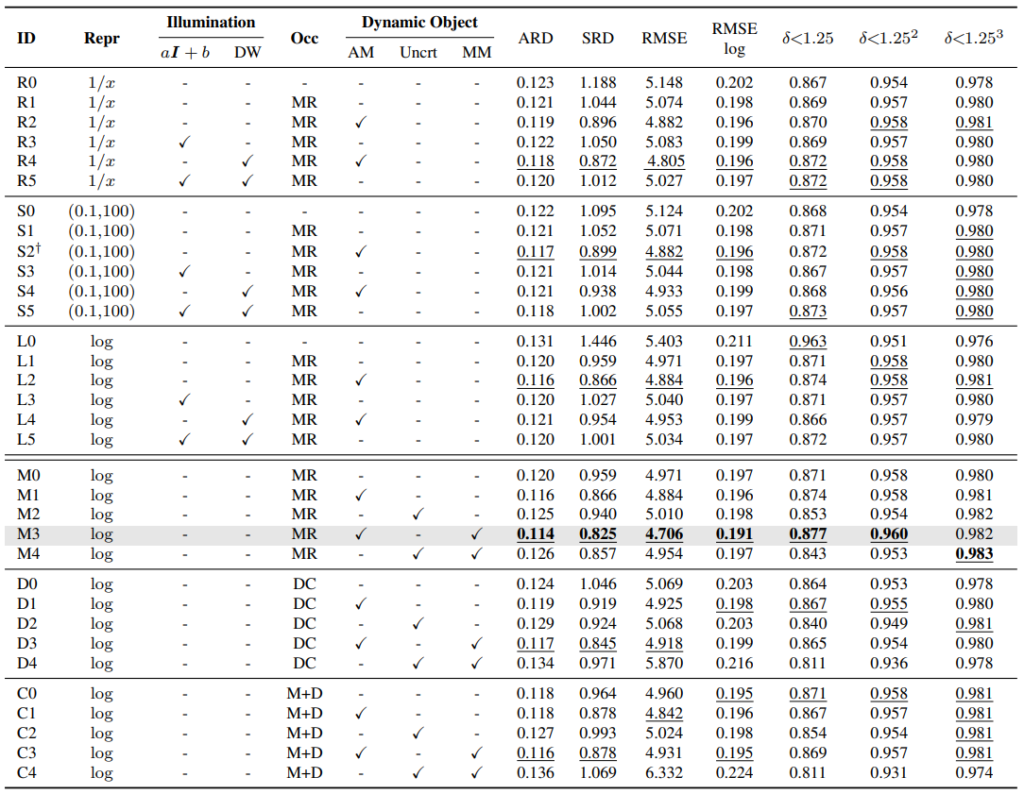
ablation study를 통해서 각각 방법론의 어떤 조합이 가장 좋은 지 평가글 해본 것이다. 단순한 depth representation에선는 log 방식이 가장 좋으며 그걸 고정시킨 후 보았을때 MR 방식을 쓴 것이 가장 좋은 성능을 보입니다.
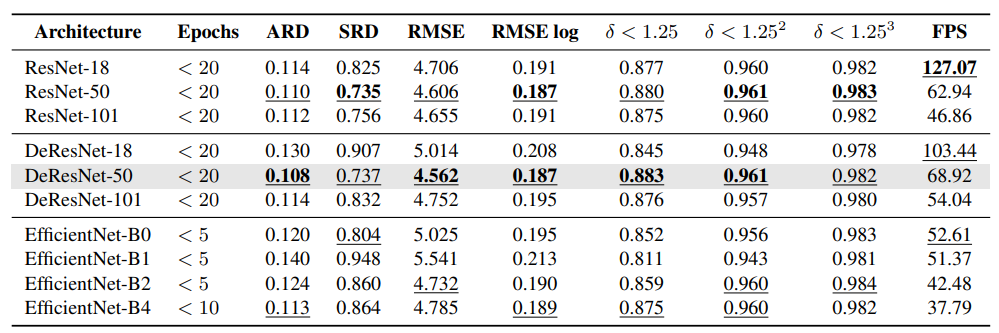
사실 저는 이 표가 가장 궁금했는데요. 과연 backbone이 무거워지면 질 수록 성능이 좋아 질 것인가에 대해서 보면, 무겁다고 좋지만은 않다가 맞습니다. resnet 계열에서는 101 보다 50 이 더욱 좋은 양상을 보이는 것으로 보아 무거운게 좋은 것 만은 아니다라는 것을 알 수있습니다. efficientnet은 epoch 수가 왜저럴까 했는데, 학습이 저 epoch 뒤로는 안되서 가장 좋은 성능을 리포팅한 것이라합니다. 저자가 말하길 아마 network에 맞는 hyparameter를 못 찾은 것 같다고 그럽니다.
Resnet 이 무겁다고 좋지만은 않다…. 굉장히 좋은 결과 인 것 같습니다.(물론 저의 논문에…)