
이번에 리뷰할 논문은 또랜스포머입니다. 요새 Self-supervised monocular depth 논문들이 잘 나오지도 않고 ICCV2021에 트랜스포머 관련된 논문들이 많이 나온 것 같아 당분간 Transformer 관련해서 리뷰를 작성하지 않을까 싶네요.
일단 해당 논문은 제목만 봐도 딱 아시겠지만 Pyramid 형식 즉 계층적 구조로 이루어진 Vision Transformer입니다. 어 이거 지난번 저가 리뷰한 Swin과 CSwin과 네트워크 구조가 딱 유사해보이네요. 물론 네트워크 구조는 유사하지만 제안하는 방법론과 세부 디테일들은 명확히 다르기 때문에 ICCV2021에 나란히 accept된게 아닐까 싶네요. (참고로 같은 ICCV2021이어도 해당 논문은 Oral Paper이니 Swin보다 더 좋지 않을까라는 기대감이…?)
그럼 시작합니다.
Introduction
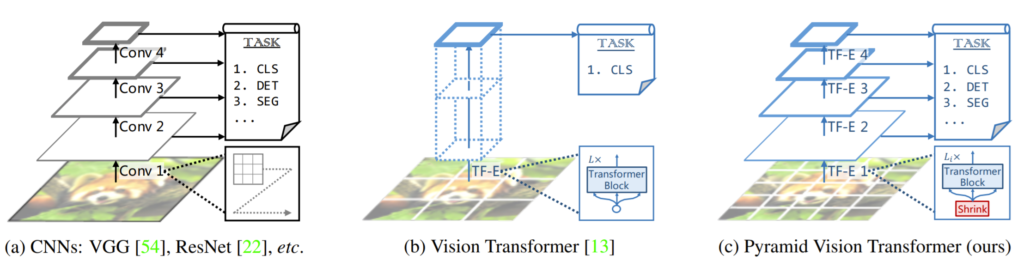
서론 설명은 사실 딱히 할만한게 없습니다. 그 이유는 Transformer를 Pyramid와 같은 계층적 구조를 했음으로 얻을 수 있는 이점들에 대해서 열심히 설명하는데 이것이 Swin이나 CSwin과 크게 다르지 않기 때문이죠.
그래서 Pyramid Vision Transformer(PVT)의 장점에 대하여 다음과 같이 요약하겠습니다.
- 기존의 ViT와 달리 PVT는 점진적으로 feature map이 down sampling되는 계층적 구조로 이루어져있기에 고해상도 영상을 입력으로 사용해도 연산량이 상대적으로 적으며, 이를 통해 다양한 Dense prediction task를 수행할 수 있다.
- Spatial-Reduction Attention(SRA) Layer를 통해 고해상도 feature map을 학습할 때 리소스 사용량을 더 줄일 수 있다.
1번은 계층적 구조를 사용하였을 때 얻는 이점으로 지난번 리뷰한 CSwin, Swin과 동일한 장점이라고 볼 수 있습니다. 조금 더 추가적인 설명을 하자면, 기존의 ViT는 입력 영상을 16×16 또는 32×32 패치로 쪼개서 이를 임베딩 벡터로 만든 후 Transformer block의 입력으로 넣었습니다.
하지만 Dense level prediction을 수행하기 위해서는 픽셀 하나하나의 정보들이 잘 살아있는 것이 중요하기 때문에, Patch의 크기를 16×16으로 하기에는 아쉬움이 존재합니다. 그러면 4×4같은 작은 패치 단위로 입력을 넣으면 되지 않을까요?
아쉽지만 Original ViT는 거의 불가능한 것이, 그림1 (b)와 같이 Transformer block을 통과한 output feature map이 일반적인 CNN 네트워크처럼 2배씩 down sampling이 되는 것이 아니기 때문에 패치를 4×4같은 작은 값들로 쪼개게 되면 Self-attention을 수행해야할 연산량이 너무 많아지게돼서 연산 복잡도가 크게 늘어나게 됩니다.
이와 비슷한 맥락으로 16×16 패치를 사용한다 하더라도 입력 영상이 고해상도일 경우에 역시 Attention을 수행해야할 패치들이 늘어나는 효과를 가지게 되므로 연산량이 크게 늘어나죠.
그래서 고해상도 영상을 입력으로 넣기에도 힘들뿐더러, 패치 크기를 크게 키우다보니 생성되는 Transformer block을 통과하고 나온 feature map의 크기도 16배로 줄어드는 등 여러 이유로 Object detection, Segmentation과 같은 Dense level prediction을 수행하기가 어려웠습니다.
아무튼 이러한 이유들로 계층적 구조가 얻는 이점이 1번에 해당하게 되는 것이고, 2번의 경우(SRA) 저자가 새로 제안한 Attention Layer로 보이는데 이는 Method에서 다시 설명드리겠습니다.
Overall Architecture
먼저 모델의 Pipeline부터 살펴보겠습니다.
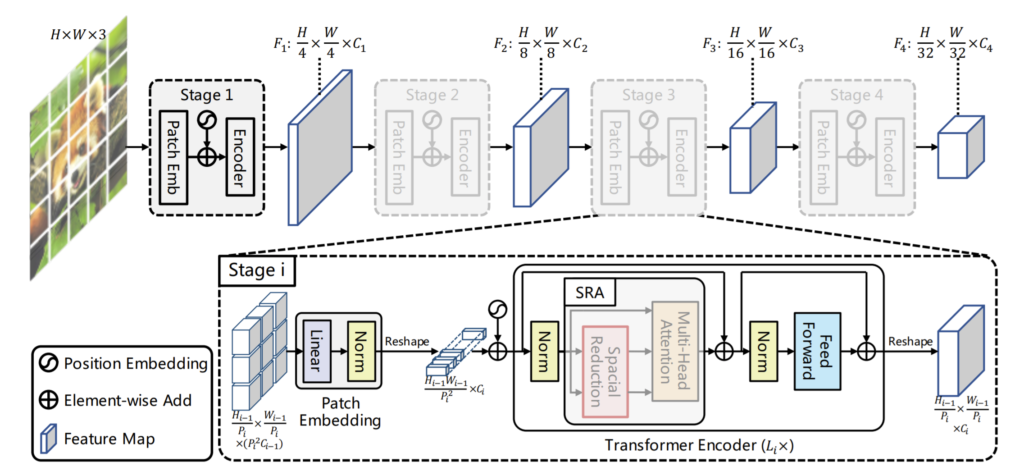
PVT는 일반적인 CNN 네트워크와 Swin과 같이 4개의 Stage로 구성되어 있습니다. 각 스테이지에 대해서 가볍게 살펴보시죠. 먼저 입력 영상을 4×4 패치로 쪼갠 다음 flatten하여 Linear projection을 수행합니다. 그리고 Positional Encoding도 같이 진행해준 다음에 Transformer Block을 들어가게 됩니다.
Transformer Block 내부 구조는 그림2에서 살펴보실 수 있는데 Positional encoding까지 처리된 feature map이 입력으로 들어오면 Layer normalization을 수행한 후 논문에서 제안하는 SRA 모듈을 통과하게 됩니다.
SRA 모듈이란 논문에서 새롭게 제안한 것으로 사실 기존의 Multi-Head Attention(MHA) 모듈과 크게 다를건 없습니다. MHA와 동일하게 Key, Query, Value 값들을 이용해서 Attention 연산을 수행하게 되는데, 이때 다른 점은 그림3과 같이 Attention Operation을 수행하기 전에 Key와 Value의 스케일을 줄이는 작업이 수행됩니다.
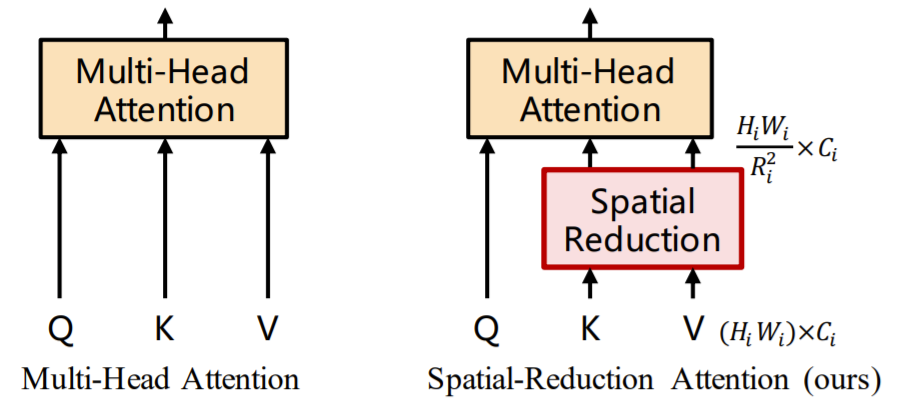
Spatial Reduction을 수행하는 이유는, 기존 ViT와 달리 입력 영상을 4×4 패치로 잘랐기 때문에 들어오는 데이터가 상대적으로 고해상도에 해당합니다.
이때 Swin의 경우 Shifted Window를 통해 Global Attention이 아닌, Local Attention 연산을 수행하여 연산량을 줄였지만, 해당 방법론은 동일하게 Global Attention을 수행하므로 Key와 Value 벡터의 스케일을 줄이는 방법을 택한 것입니다.
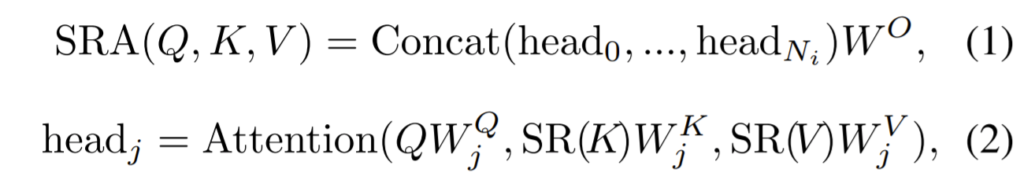
각 단계별 디테일은 위의 수식과 같습니다. 먼저 W^{Q}, W^{K}, W^{V} W^{O}는 linear projection을 수행하는 weight 값이라고 보시면 됩니다. Multi Head Attention을 수행하기에 각각에 head들이 Concat을 하여서 W^{O}를 통해 어떠한 임베딩 공간으로 투영되는 것이 수식 1번입니다.
그리고 수식 2번은 단일 헤드에 대하여 Attention이 수행되는 과정을 묘사한 것인데, 이때 Key와 Value가 논문에서 제안하는 SR모듈을 한번 거쳐 scale이 줄어들게 됩니다.
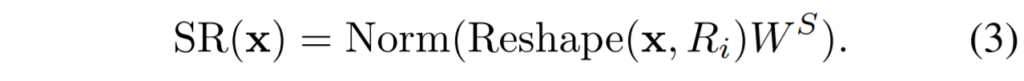
SR은 위의 수식과 같이 표현할 수 있는데, Reshape(x, R_{i}는 기존 shape x를 (H_{i}W_{i} / R^{2}_{i}) \times (R^{2}_{i}C_{i}) 크기로 reshape하는 것을 의미합니다. 그리고 W^{S}는 Linear projection을 수행하는 레이어로 Reshape을 통해 변경된 차원 R^{2}_{i}C_{i}를 C_{i}로 줄여버리는 역할을 수행합니다.
그 다음에 Attention 연산을 수행하는데 이는 기존 ViT와 동일하게 동작합니다.
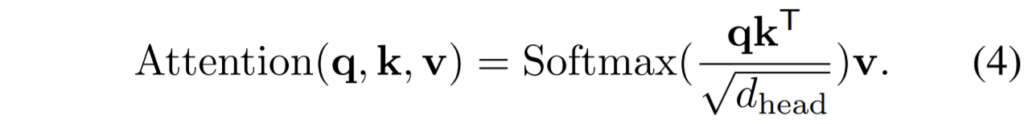
이러한 연산을 통해, Attention 연산을 수행하는데 있어 기존 ViT 대비 R^{2}배 더 적은 메모리와 연산량이 필요하게 됩니다.
Model Information
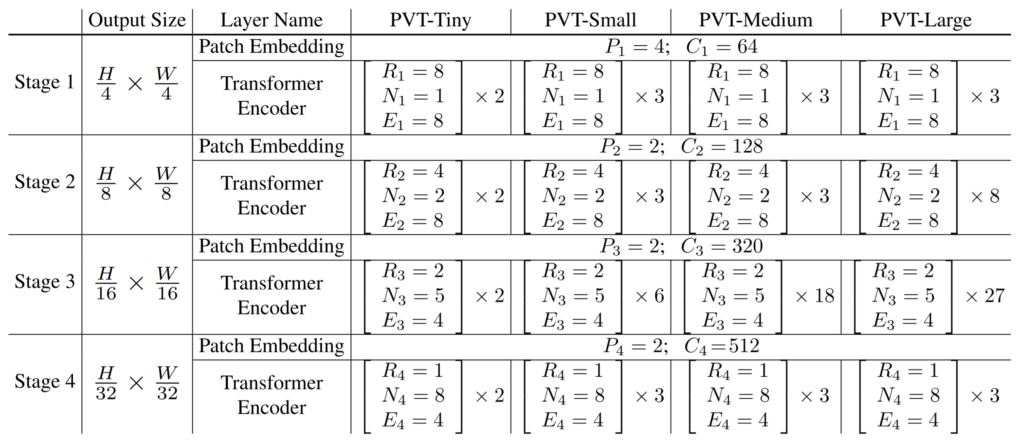
위에 표는 PVT의 세부 정보들을 나타낸 표입니다. 각 스테이지 별로 output feature의 해상도는 어떻게 되는지, 모델의 크기(Tiny, Small, Medium(Base), Large)에 임베딩 벡터의 차원 및 Attention이 몇번 수행되는지 등을 확인할 수 있습니다.
여기서 꽤나 매력적인 점은 Swin의 경우 Tiny가 Resnet-50과 유사한 크기를 가졌는데, PVT의 경우 Tiny~ Large 순서대로 Resnet 18, 50, 101, 152의 크기와 유사하다고 합니다. Pyramid Transformer를 먼저 봤었더라면 Depth Estimation할 때 PVT-Tiny를 사용해봤을지도 몰랐겠네요.
Experiments
실험은 Swin과 동일하게 Classification, Object Detection, Segmentation을 진행하였습니다. 먼저 ImageNet 1K부터 살펴보시죠.
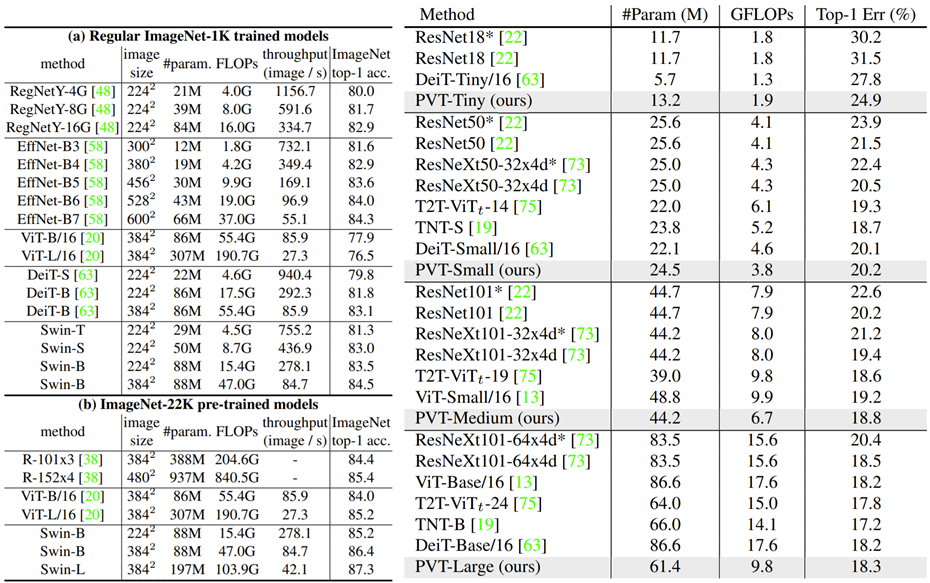
좌측은 Swin Transformer 논문에서 리포팅한 Swin과 다른 방법론들의 정성적 결과이며 우측이 PVT 논문에서 리포팅한 ImageNet 결과입니다. Swin의 경우 input resolution이 224, 384 나눠서 리포팅을 하고 있으며 PVT는 224×224에 대해서만 리포팅하였습니다.
일단 PVT의 파라미터 수가 Swin과 비교하였을 때 상당히 차이나는 것을 볼 수 있었는데, PVT-Large가 Swin-B보다 더 적은 파라미터를 가지고 있었네요?(61.4 vs 88 M) 물론 성능의 차이는 Swin-B가 83.5%이고 PVT-L이 81.2%로 차이가 적잖이 나는 모습이지만, 파라미터 수와 비교하면 Swin-S 보다도 작으니 꽤 준수한 모습을 보이고 있습니다.(근데 PVT-L이 Swin-T보다는 파라미터 수가 많은데 성능은 Swin-T가 더 좋은 모습이…?)
그래도 유사한 크기를 가지는 CNN 모델들과 비교해보면 우수한 성능을 보여주고 있다는 점에서 매우 만족스럽습니다.
다음은 Object Detection 결과입니다. 데이터 셋은 COCO val2017을 사용하였으며, ResNet및 ResNeXt 모델들과 결과를 비교하고 있는 모습입니다.
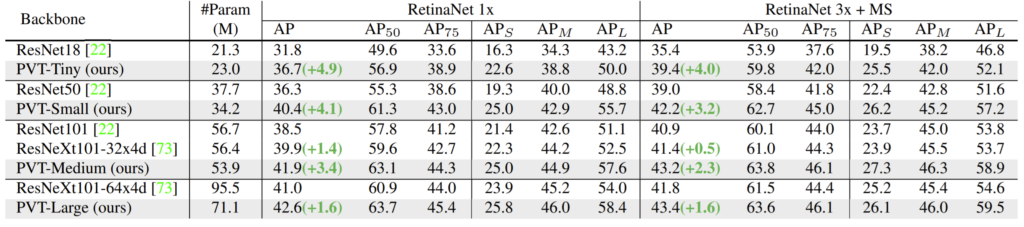
위에 표 중 RetinaNet 1x와 3x가 존재하는데, 1x와 3x는 각각 12 or 36 epoch를 학습한 것을 의미하며 MS의 경우 multi-scale training을 한 것이라고 합니다.
저자가 말하기를 자신들의 모델이 1x training 방식에서는 ResNet18보다 4.9점이나 더 높은 점을 어필하고 있으며 3x training의 경우 ResNeXt 101보다 모델 파라미터 수는 30%더 적은 반면에 성능은 더 좋게 나온 것을 강조하고 있습니다. 전반적인 결과를 보면 Tiny와 Small과 같은 작은 모델에서 좋은 성능을 보이는 것이 매우 매력적으로 다가오네요.
마지막으로 Segmentation 결과입니다.
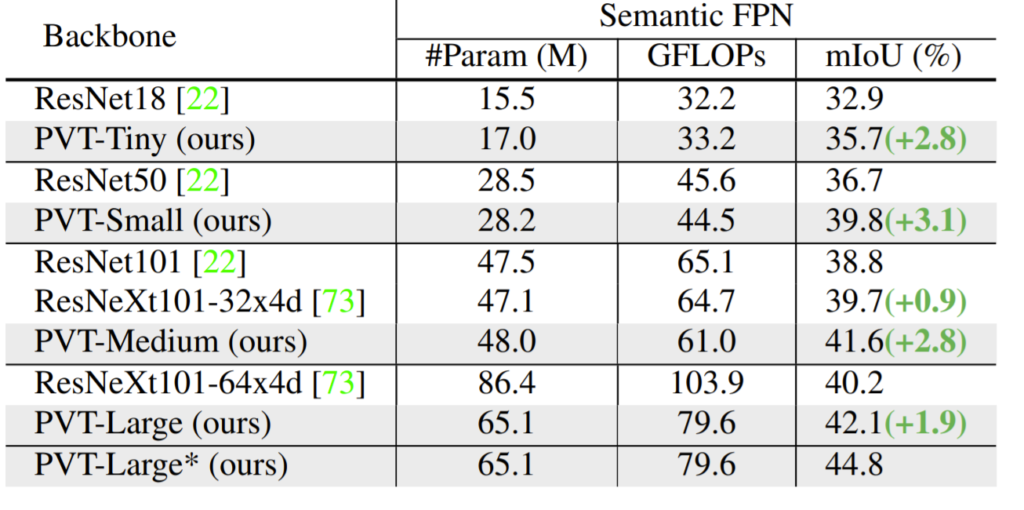
Object Detection때와 유사하게 Tiny, Small과 같은 작은 모델의 크기들이 유사한 크기의 CNN 모델들과 비교하였을 때 더 큰 성능 향상을 보이고 있으며 추가로 Medium 크기에서도 큰 성능 향상폭을 가지고 있습니다.
결론
해당 논문은 Swin과 유사하게 original ViT의 단점을 해결하고 Vision 도메인 그 중에서도 Dense level Prediction에 초점을 맞춰서 설계된 Transformer를 제안했습니다. ViT는 상당히 무겁고 연산량이 많다는 느낌을 많이 받았었는데, 해당 논문은 이러한 문제점을 잘 해결함과 동시에 CNN 모델과 비교하였을 때 의미있는 성능 향상 폭을 보였다는 점에서 꽤나 매력적인 논문이라고 생각됩니다.
또한 왜 Swin과 달리 Oral Paper를 받았는지에 대해서 살펴보니, Ablation study가 상당히 정리가 잘 되어있더군요. 시간이 생긴다면 해당 리뷰에 추가로 Ablation study를 담도록 하겠습니다.
… Segmentation은 Swin과 동일한 datatset을 안썼나요 혹쉬..? 같은 거 썼으면 어떤게 dense prediction에서 더욱 좋은지가 살짝쿵 궁금하네요
Segmentation 실험 역시 Swin과 동일하게 COCO와 ADE20K 데이터 셋을 사용했습니다. Segmentation 성능을 따로 리포팅안한 것은 둘 다 백본만 제안한 모델이기 때문에 Decoder 부분은 서로 다른 방법론들을 가져다가 사용한 것이라 Decoder에 따른 성능 차이가 발생하지 않을까 싶어 안가져왔습니다.(Swin은 upperNet 사용, PVT는 Semantic FPN 사용)
그래도 일단 답변을 드리자면 Segmentation에서는 PVT-L와 Swin-T가 유사한 파라미터를 가지고 있는데(Swin-T는 60M, PVT-L는 65.1M) 성능은 Swin-T가 46.1, PVT-L이 44.8로 Swin-T가 더 좋은 모습을 보이고 있습니다.