이번 리뷰는 중기청 과제에 참고했던 베이스 방법론에 해당 합니다. 예전에 arXiv에 등재된 해당 논문을 알고 계시던 분들이 있을거라고 생각합니다. 확인하고 재밌는 논문이라고 생각만 했지 CVPR에 붙을 거라고는 생각 못했는데 참 신기하네요. 사설은 여기서 줄이고 논문에 대해 간략하게 요약하자면 아래와 같습니다.
간단한 데이터 증강만으로 COCO dataset-Instance Segmentation에서 SOTA를 달성하였습니다. 또한 대부분의 방법론에서 성능 개선을 보여줌으로써, 한 모델에 특정된 방법론이 아닌 범용적 사용이 가능함을 증명합니다.
Intro
Instance segmentation은 실제 어플이케이션에서 활용 가능한 컴퓨터 비전 중 중요한 한 분야입니다. 현재는 CNN이 대세를 이뤄 방법론을 이끌고 있지만 CNN은 데이터의 질, 양, 정보에 따라 성능이 좌지우지 되기 때문에 항상 데이터에 고파 있습니다. 하지만 만족할만한 큰 데이터 셋을 만들기는 매우 어렵습니다. 대표적인 예시로 Instance segmentation 중 유명한 데이터 셋인 COCO dataset의 1000개의 instance mask를 만드는데 22시간이 소요 되었다고 합니다. 이러한 한계로 대부분의 모델들은 강제로 데이터 효율을 고려하여 모델을 설계할 수 밖에 없습니다.
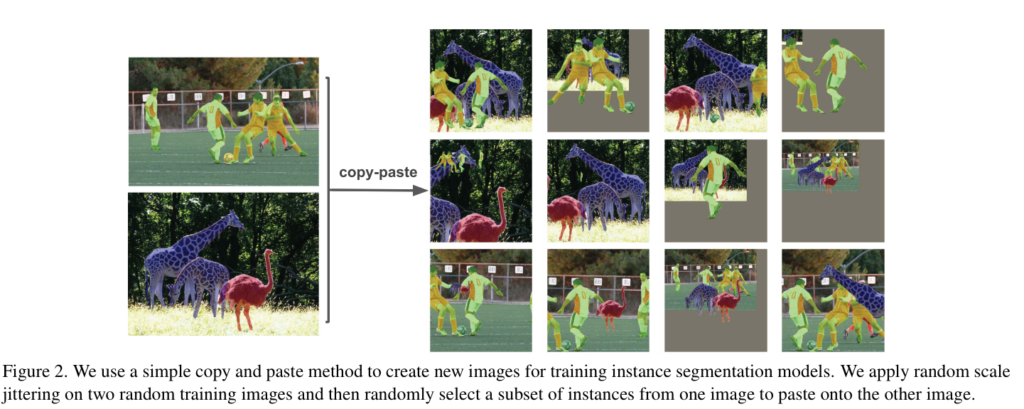
저자는 이러한 장점에 대응할 수 있는 간단한 방법을 CopyPaste라고 소개합니다. CopyPaste의 적용 방법은 아래와 같습니다.
1) 두 쌍의 영상을 선정합니다.
2) 소스 영상으로부터 복사할 객체 인스턴스를 선택합니다.
3) 복사한 인스턴스를 타켓 이미지에 붙여넣은 위치를 선택하여 붙여넣습니다.
더 자세한 예시는 Fig 2에서 확인 가능하며, 보이는 바와 같이 단어 그대로 객체를 가져다가 붙이는 방법을 사용합니다.
저자가 제안하는 Simple CopyPaste는 붙여 넣을 때, 랜덤한 위치에 붙여 넣으며 또한 scale에 강인성을 데이터에 부여하기 위해 소스 영상의 크기를 조절하는 Large Scale Jitter(LSJ)라는 방법을 추가합니다.(Fig 2의 영상 크기 다른 이유가 LSJ 때문입니다. 걍 resize crop 한거 라고 보시면 편합니다. + random horizontal flip)
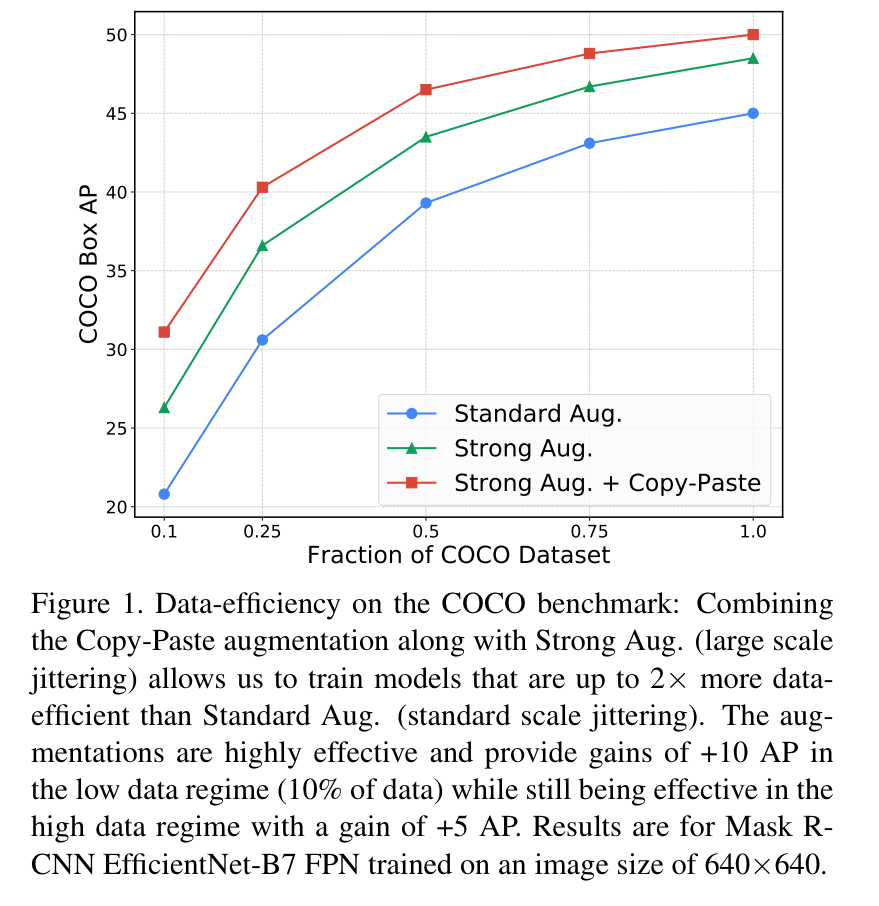
해당 방법은 Fig 1과 같이 데이터 수(x 축)에 상관 없이 대략 +10 Box AP 정도의 성능 개선이 이뤄진 것을 볼 수 있습니다. 이 실험 결과를 토대로 해당 방법론이 데이터 셋에 대한 효율성을 향상 시켜준다는 것을 증명합니다. 또한 영상 크기, 모델의 변경 실험에서도 성능 향상을 보이며, SOTA 방법론에서도 성능 개선을 가져왔습니다. (해당 논문을 알고 있는 이유도 Paper with Code에 해당 방법론을 이름으로 한 팀이 1등을 꽤나 오래 유지하고 있었습니다.)
Method
아마 이 글을 읽으시는 분들 중, 고작 저걸로 CVPR로 붙었다고? 그럴리가… 뭔가 더 있겠지… 이런 생각을 하시는 분들이 있을거라고 예상합니다. 결론만 말씀드리면 적용한 방법은 위에서 설명드린 방법(fig 2)만 사용한 것이 맞습니다.
또한 저 CopyPaste는 이미 제안된 방법이며, instance segmentation에 적용한 방법들도 존재합니다. 출판된 곳 또한 ICCV, ECCV, CVPR 등 매우 훌륭한 출판지에 붙었습니다. 처음 제안한 방법도 아닌데 왜 해당 논문이 붙은 걸까요?
그 이유에 대해 설명하기 위해 먼저 이전 방법론(CopyPaste)과 차별점에 대해 먼저 다뤄야합니다. 처음으로 CopyPaste를 적용하여 큰 효과를 선보인 방법은 Mixup과 CutMix가 있습니다. 두 방법은 다른 클래스를 가진 객체를 블렌딩하거나 bounding box를 기준으로 영상을 붙임으로써 “분류 모델”에서 획기적인 효과를 선보였습니다. “객체 검출 방법”에 적용한 Cut-Paste-and-Learn는 객체들을 “수동”으로 그럴싸한 위치에 붙여 넣는 방법을 사용합니다. 또한 붙여진 경계에 여러 블렌딩을 적용하여 보다 자연스러운 영상을 생성합니다. Instance Segmentation에서 제안된 Contextual CutPaste와 InstaBoost는 데이터로부터 객체 마스크들을 생성하고 ”객체 마스크별로 문맥적으로 어울리는 곳”을 지정하여 붙여넣는 방법을 사용합니다. 더 나아가 InstaBoost는 다른 영상이 아닌 자신의 영상에서의 객체만 이용합니다.
하지만 저자는 주장합니다. 붙일 곳을 모델을 고려하거나 사람이 직접 붙이거나 경계를 블렌딩하는 방법 등 복잡한 방법을 사용하지 않고 그냥 랜덤하게 아무 곳에나 붙이는 Simple CutPaste를 사용만 사용해도 충분한 효과를 보인다고 주장합니다.
그리고 가장 큰 이유는 SOTA를 달성한 부분이 크게 작용한 부분이 있다고 봅니다.
Large Scale Jittering
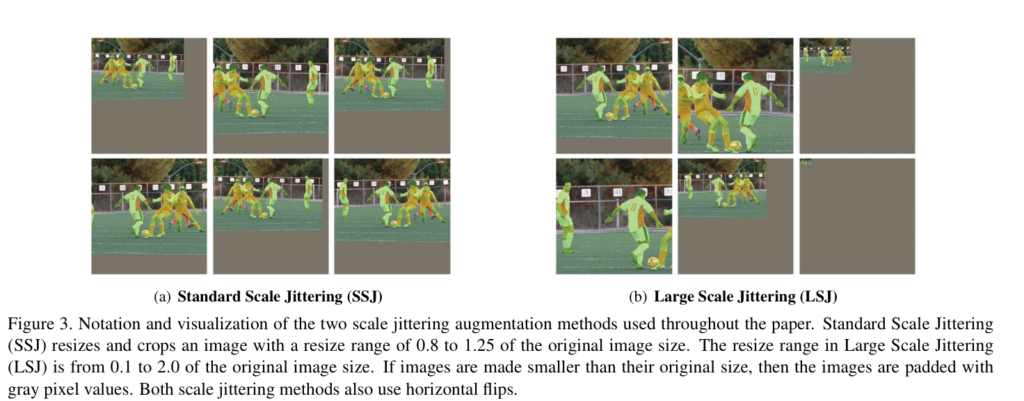
저자는 scale에 대한 강인성을 주기 위해 Scale Jitter를 적용합니다. 어떤 값을 이용하는 것이 좋은지 보이기 위해 이전 연구에서 흔히 사용되는 영상 비율을 0.8-1.25 변화하는 Standard Scale Jittering(SSJ)과 제안하는 0.1-2.0의 변화를 주는 Large Scale Jittering을 소개합니다. 성능면에서 LSJ라 더 좋다는 것을 실험적 결과로 보입니다.
Self-training CopyPaste
여기서 붙이는 영상들은 라벨링이 진행되지 않은 영상들을 모델을 통해 추론하여 pseudo-label을 진행합니다. 추론된 영상과 마스크를 붙이는 방법을 self-training copypaste라고 이야기 합니다.
Experiment
Architecture & Datasets
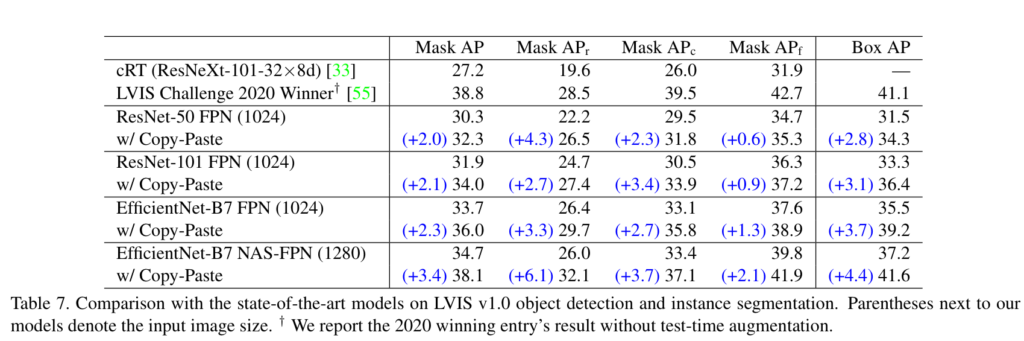
Mask-RCNN(ResNet or EfficientNet)과 Cascade Mask-RCNN(EfficentNet-B7)+NAS-FPN에서 Ablation Study와 SOTA를 달성함을 보입니다. 또한 여러 데이터 셋에서 SOTA를 달성한 결과를 보여줍니다.
Robustness to Backbone initilization
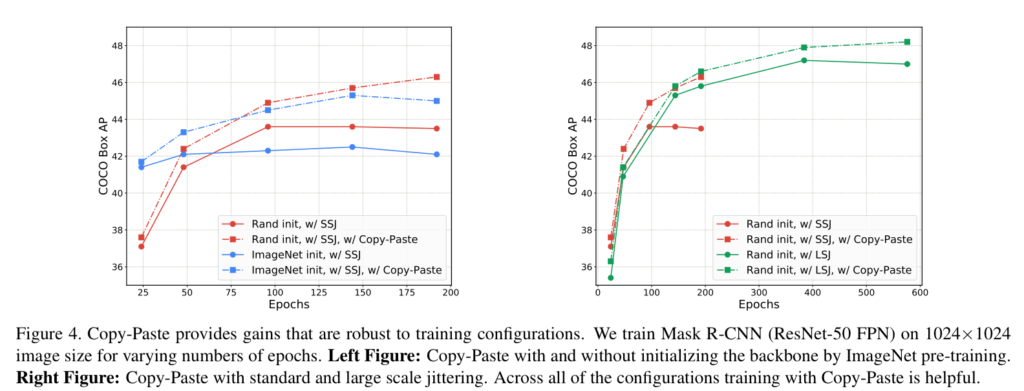
Mask-RCNN의 backbone을 Random init 하는 경우와 ImageNet으로 초기화하여 진행하는 경우에 대한 실험을 진행한 결과 어느 초기화 값에서도 좋은 성능 개선을 보여주는 결과(Fig 4)를 볼 수 있다.
Robustness to training schedules
이전 연구에서 COCO에서 학습 기간이 길어질수록 성능이 향상된다는 연구 결과가 있었다. Fig 4에서 보이는 바와 같이 같은 epoch 동일한 성능으로 시작했지만 epoch이 지날수록 제안한 기법이 적용되지 않은 모델보다 성능이 향상되는 것을 볼 수 있다. 이를 통해 학습 기간에 영향이 덜하도록 만드는 매우 실용적인 데이터 증강 기법이라는 것을 증명한다고 주장한다.
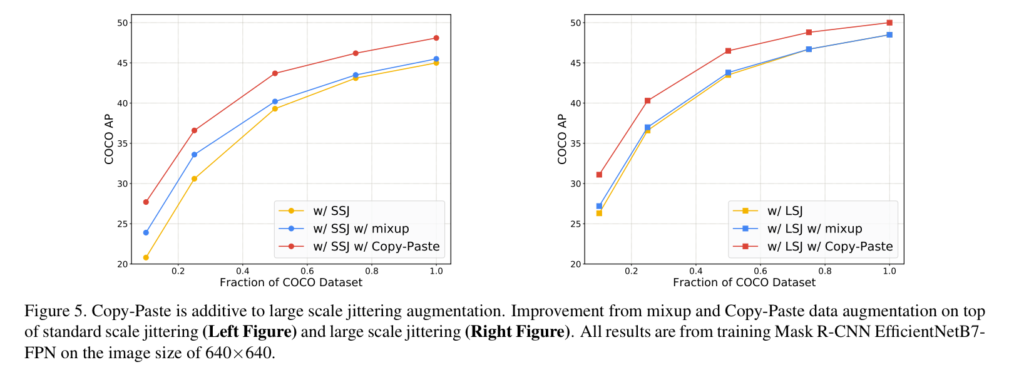
또한 SSJ와 LSJ에서의 비교 실험(Fig 4, 왼쪽 오른쪽 그림)을 통해 LSJ에서 보다 나은 결과를 보인다. 하지만 mixup에서는 낮은 결과를 보여준다.
Copy-Paste works across backbone architectures and image sizes
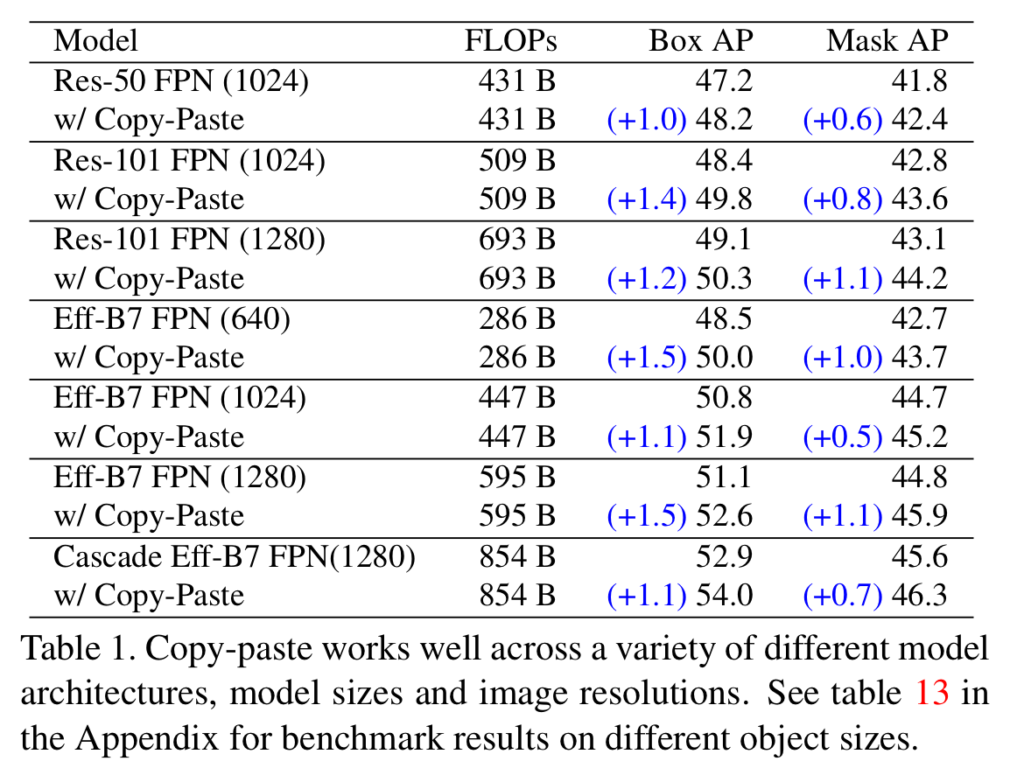
해당 실험에서는 모델별 성능 향상과 입력 이미지 변화를 주며 제안한 데이터 증강 기법을 적용할 경우에도 성능 향상이 있음을 보여준다.
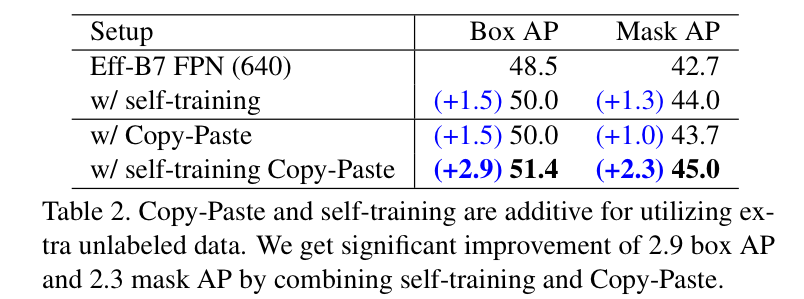
CopyPaste and Self-trainning are additive
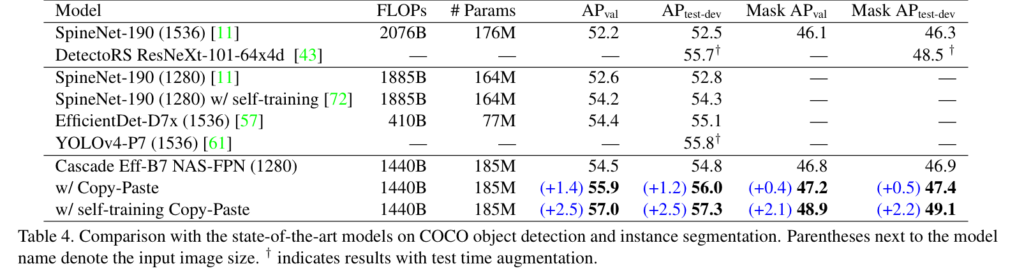
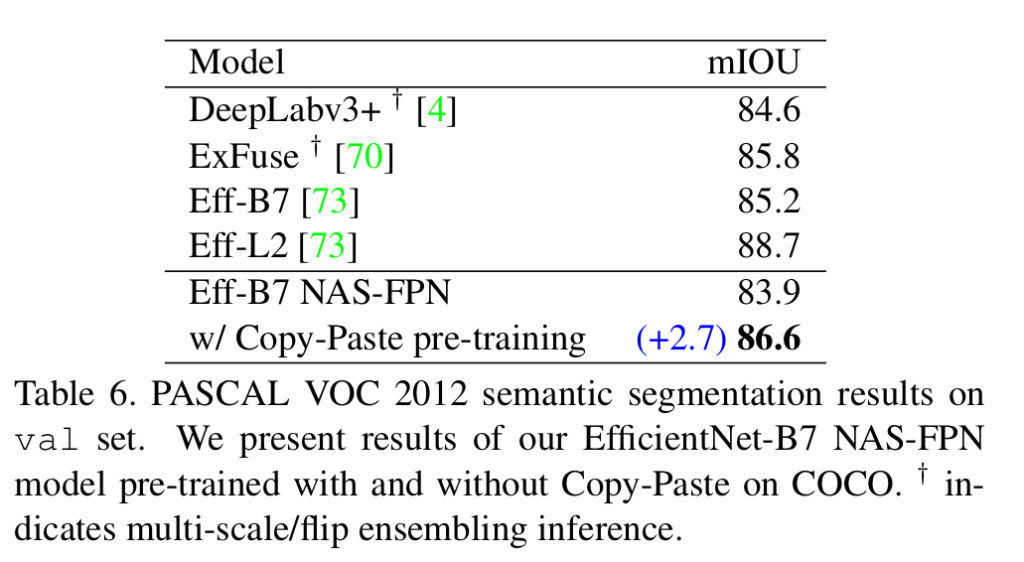
Copy-Paste improves state-of-the-art

Blending
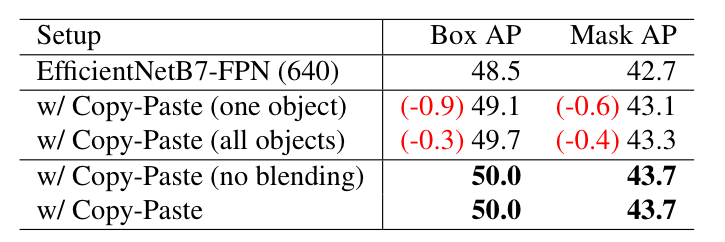
해당 실험에서는 붙인 객체의 경계에 블렌딩 여부에 따른 실험 결과 입니다. 실험 결과, 블렌딩의 중요성을 강조한 방법론과는 대조적으로 동일한 성능을 보여줍니다. 또한 랜덤한 객체를 뽑아 붙이는 것이 아닌 하나의 객체만 붙이거나 모든 객체를 붙일 경우에 따른 실험 결과 입니다. 실험적 결과, 랜덤하게 다양한 케이스를 붙이는 것이 효과적임을 보입니다.
================================================================
Cutpaste 기법을 사용한 방법이 많이 존재함으로 어떤 차별성을 두었을까 많은 기대를 하고 보았습니다. 음… 개인적인 의견으로는 애매한 차별점을 가졌다고 생각하며, CVPR에 붙을 만큼 novelty는 없다고 생각합니다. 하지만 연구의 효과만 놓고 본다면 큰 영향력을 보이는 방법이기는 합니다. 이러한 점을 다양한 데이터 셋에서 SOTA를 달성하고 범용적으로 적용이 가능하다는 점에서 인정을 받았다고 추측합니다.
jitter하고 cut-mix는 제가 최근에 돌리던 코드에서도 채택하는 방법이라 낯이 익네요. Augmentation 방법만으로도 CVPR이 되다니 그에따른 논리적이 글과 뒷받침 하는 실험들이 강했기 때문이겠지요? 혹시 멀티스펙트럴 object detection에서 해당방법 data augmentation 방법의 활용은 어떻게 보시나요? 물론 두개의 모달리티에 동시에 적용하여 pair를 깨트리지 않는다는 전제하에요.
멀티스펙트럴에서도 성능 향상을 보일 것이라고 예상합니다. 글을 읽으면서 저자가 주장하고 싶은 바는 ‘해당 기법 사용하면 데이터 늘리는 것과 동일하다’ 라는 내용이라고 생각합니다. 그러한 측면에서라면 멀티스펙트럴에 적용해도 동일하게 적용된다고 생각합니다.
“랜덤하게 아무 곳에나 붙이는” 까지는 컨셉을 이해하겠는데, 혹시 붙이는 객체의 숫자에 관련한 내용은 없나요? 적당한 숫자의 객체를 골고루 붙이지 않으면 성능에 악영향이 갈 것 같은데, 관련 내용이 있다면 알고 싶습니다!
흠… 질문 감사드립니다. 제가 글을 잘못 작성한 것 같습니다… 저자는 적당한 숫자와 적당한 위치에 골고루 붙이지 않고, 랜덤하게 붙여도 좋은 성능을 보인다는 것이 이전 연구들과의 차별점이라고 주장하였습니다.
말씀하신 적당한 양과 적당한 위치에 붙이는 방법에 대한 실험과 영향력이 궁금하시다면 이전 연구 중 IntraBoost와 Contextual CutPaste 논문을 참고하시면 좋을 것 같습니다.
리뷰 잘 읽었습니다.
혹시 Contextual CutPaste와 InstaBoost 등의 방식과의 성능 비교는 없었는 지 궁긍합니다.
아쉽게도 cutmix를 제외하고는 다른 데이터 증강 기법과 비교하지 않았습니다. 말씀하신 방법론들이 데이터 셋에 대한 특수성을 고려해야한다는 문제가 있어 때문에 적용하지 않아도 넘어가지 않았을까 합니다.