Facial Landmark Detection 방법론의 서베이 논문입니다. 그동안 해당 분야의 논문을 너무 얇게만 훑어보는 것 같아 흐름을 파악하고자 읽어보았습니다.
Facial Landmark Detection Problem
Facial Landmark Detection 은 얼굴의 랜드마크(상징물, eg. 눈, 코, 입, 눈썹, 턱 등)의 위치를 탐지하는 방법론입니다. 아래 그림이 바로 대표적인 Facial Landmark Detection의 결과입니다.

다시 말해, Facial Landmark Detection은 입력 이미지 I 로부터 랜드마크의 위치 벡터인 L 을 예측하기 위한 function Φ: I → L 을 찾는 문제입니다. 여기서 랜드마크의 개수(쉽게 말해, 상단 그림에서 노란색 점의 개수)는 데이터 혹은 target task 마다 상이합니다.
Metric
Facial Landmark Detection에서 성능을 평가하기 위한 메트릭은 크게 아래 세 가지가 있습니다.
- Normalized Mean Error (NME, %)
쉽게 말해, 이 방법은 예측값과 GT 사이 N_L 개의 랜드마크 점끼리의 거리를 Normalized 한 Mean Error 입니다. 당연히 작을수록 좋은 성능이라고 할 수 있겠죠. 가장 간단한 평가 메트릭이면서도 가장 흔하게 쓰이는 메트릭이라고 생각할 수 있을 것 같습니다.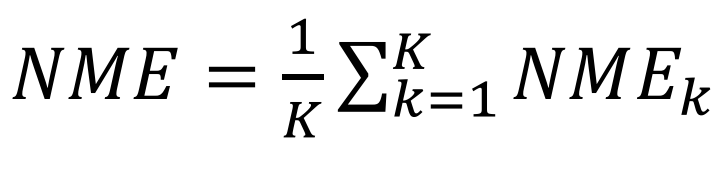
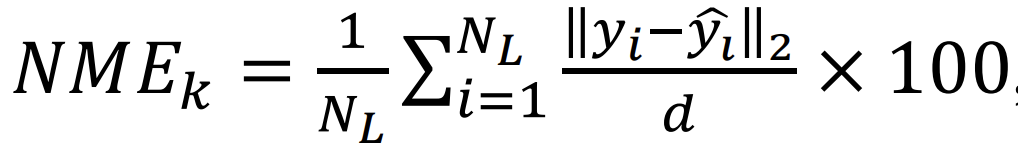
- y : GT
- \hat{y} : prediction
- d : normalization coefficient (데이터셋마다 다름)
- N_L : 랜드마크의 개수
- K : Test 이미지 개수
- Failure Rate (FR, %)
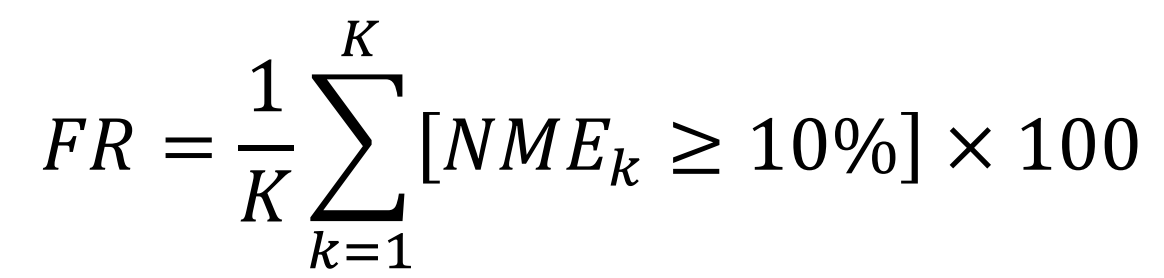
앞서 구한 NME가 10% 이상 차이나는 것을 Failure 로 설정하여, 전체 테스트셋 중 Failure 인 이미지의 비율 즉 Failure Rate을 계산합니다. 이 역시 값이 작을수록 좋은 성능입니다. - Cumulative Error Distribution – Area Under Curve (CED-AUC)
x축은 NME 값을 나타내며, y축은 해당 NME를 threshold로 설정하여 보다 작은 이미지의 개수 (혹은 비율)를 나타냅니다. 이해를 돕고자 CED-AUC 그래프를 첨부하였습니다. threshold 보다 작은 error 를 가지는 이미지의 개수이기 때문에, 당연히 클수록 좋은 성능입니다. 다시 말해 그래프가 전반적으로 우위에 있다면 좋은 성능을 가진다고 해석할 수 있습니다.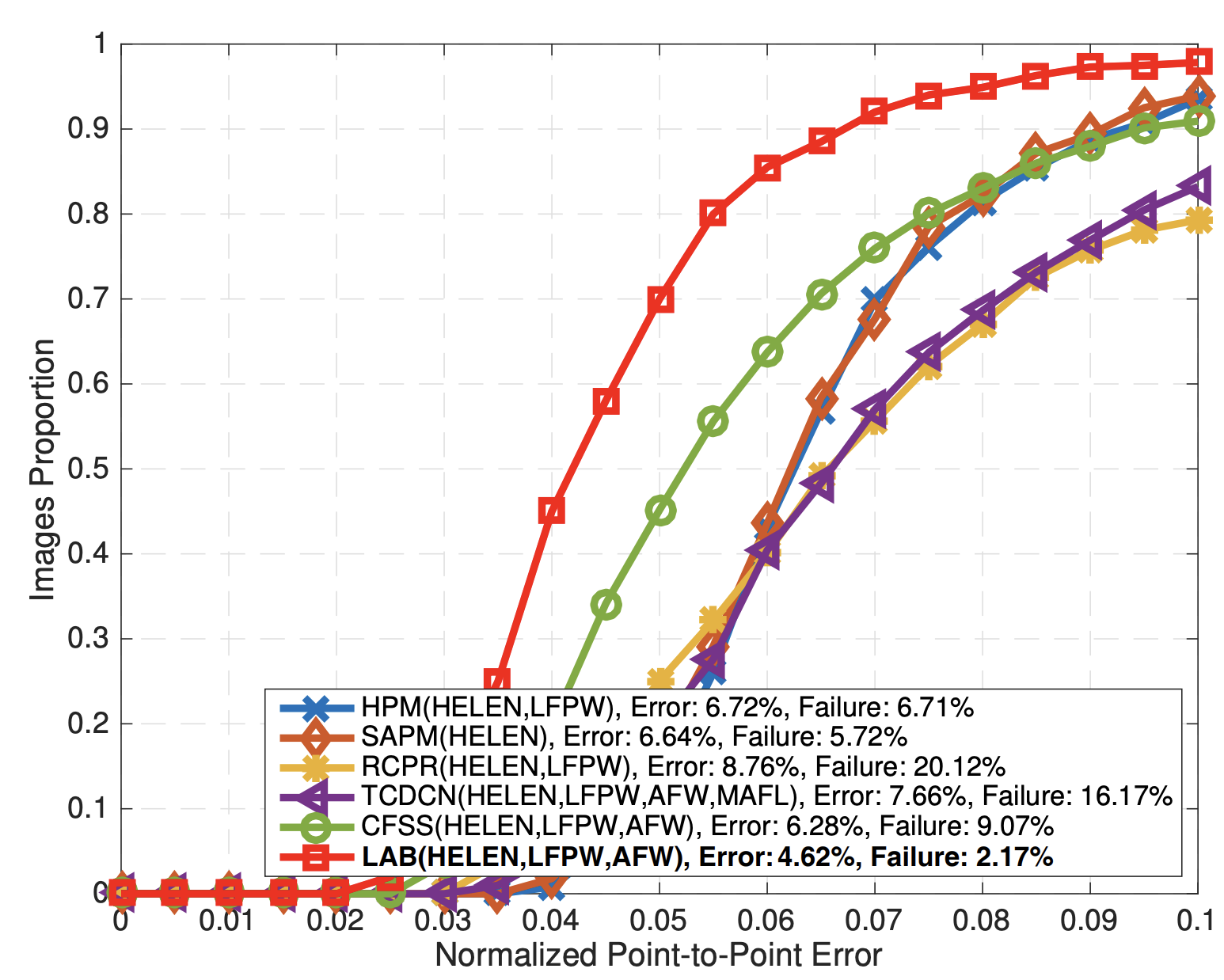
Dataset
이번 절에서는 Facial Landmark Detection 에서의 public dataset에 대해 서술하겠습니다. 아래 테이블은 Facial Landmark Detection 에서 자주 사용되는 데이터셋들을 나열한 것으로, train-test 개수 그리고 annotation된 랜드마크의 개수를 확인할 수 있습니다. 리뷰에서는 모든 데이터셋을 다루다보면 과도하게 길어질 것 같아 가장 많이 사용되는 300W 의 특징에 대해서만 정리하고 넘어가도록 하겠습니다.
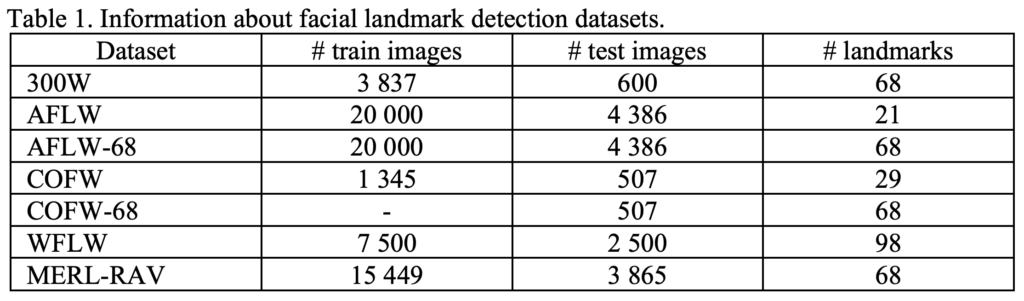
300W
- ICCV 2013 [논문 바로가기] 에 제안된 가장 대표적인 데이터셋
- HELEN, LFPW, AFW, IBUS이라고 불리는 서로 다른 Facial Dataset 의 모음
(그로 인해 다양한 각도, 표정, 촬영 조건을 가지는 데이터) - 68개의 Landmarks
- 얼굴 이미지의 난이도에 따라 3가지 범주 (common / challenge / full)


300W 를 시작으로 점차 많은 데이터들이 공개되었고, 시간이 흐를수록 점점 더 복잡한 데이터셋이 등장하였습니다.
예를 들어, 정면에 치우치지 않은 다양한 pose 를 가지는 얼굴, 다른 물체에 의해 가려진(occluded) 얼굴, 실제 물체들(스마트폰 등)에 의해 가려진 얼굴, 신체 일부(머리카락, 손 등)에 의해 가려진 얼굴, 표정, 조도, 메이크업, 블러 등 다양한 조건에 대해 문제를 해결할 수 있도록 생성이 되었습니다. 뿐만 아니라 랜드마크 개수가 너무 적은 데이터셋을 새로 라벨링하여 데이터로 활용하기도 합니다. (위에 첨부한 테이블에서 데이터셋 이름 뒤 숫자가 붙어있는 데이터셋이 그런 경우입니다 ex.AFLW-68, COFW-68)
다만 여전히 데이터셋에 대한 annotation이 충분하지 않기도 하고 (혹은 랜드마크가 정확하게 annotation 되어 있지 않음), 데이터셋 자체의 부족으로 기존 방법론에서 정확한 성능을 내는 데에는 어려움이 있습니다. 그로 인해 정면 얼굴에 한정된 성능은 우수할 수는 있어도 실제로 촬영된 얼굴 이미지에는 꽤나 좋은 성능을 내지 못한다는 결과로 이어졌습니다.
따라서 이런 환경 속에서 그동안 어떻게 방법론들이 제안되었는지에 대해 뒷 단원에서 서술하겠습니다.
Early Landmark Detection Algorithms
초기 방법론은 변형 가능한 Face Mesh 를 얼굴에 맞추는 방식을 사용했다고 합니다. 대표적으로 Active Shape Model (ASM), Active Appearance Model (AAM), 그리고 Constrained Local Model (CLM) 가 있습니다. 통계적인 수학적 해석을 기반으로 적절한 lighting 과 정면 얼굴에 한정된 데이터셋에서는 유의미한 결과를 보였으나, 실제 적용 시에는 성능이 좋지 않았다고 합니다. 이후 Random Forest 와 Gradient Boosting 을 사용하여 accuracy를 조금 향상시킬 수는 있어도 여전히 실제 적용에는 어려움이 있었다고 합니다.
이 외에도 CNN을 활용하여 Face Detection 뿐만 아니라 Landmark의 위치를 찾는데 높은 정확도와 성능을 보여준 Multi-task Cascaded Convolutional Networks(MTCNN) 이라는 방법론이 있습니다. MTCNN 에서는 얼굴 검출과 동시에 랜드마크의 위치를 찾는다고 하였는데, 68개의 랜드마크 점이 아닌 눈, 코, 입의 양 끝 점 총 5개의 점을 찾는 초기 방법론입니다. 이 방법론은 마치 SSD 와 비슷하다는 느낌을 받았는데요. 3개의 neural network(P-Net, R-Net, O-Net)로 구성되며, 각 네트워크에서 face bbox classification과 bbox regression, 그리고 face landmark localization 과정을 진행합니다. P-Net에서는 여러 해상도의 이미지를 넣어 얼굴 bbox 를 추정하고, 이후 R-Net 에서 P-Net에서 추정한 bbox를 추려낸 후, O-Net 에서 랜드마크의 위치를 찾습니다.
최근에는 Neural Regrssion-Based 방법론을 사용한 연구가 활발히 진행중입니다. 초기 방법론과는 다르게 wide 각도와 high occlusion 환경에서 촬영된 이미지에도 낮은 에러를 가지기 때문입니다. 최근 방법론도 크게 두 가지로 나뉩니다.
- Direct Regression Methods
- 모델이 랜드마크의 좌표를 바로 예측하는 방법
- Heatmap Regression Methods
- 이미지의 특정 위치에서 랜드마크가 있을 확률값인 Heatmap을 통해 랜드마크를 예측하는 방법
- (제가 지금까지 리뷰한 두 개의 Landmark Detection 논문은 여기에 해당됩니다)
초기 방법론들과는 달리 현재에는 어떤 방식으로 연구가 진행되고 있는지는, 바로 앞 단원에서 설명한 데이터셋의 부재로 인한 문제점을 어떻게 해결하였는지로 갈래를 나누어 다음 단원에 작성하도록 하겠습니다.
A Survey of Key Modern Facial Landmark Detection Developments
학습을 위한 데이터셋의 pair (input image- labeled facial landmark) 의 부족함 문제를 크게 3가지로 나누어 문제를 해결하고 있습니다.
1) use of an Auxiliary Representation
얼굴에 대한 구조적인 정보를 담고있는 보조적인 표현을 사용하는 방법입니다. 보조적인 표현으로는 다양한 방법을 사용하는데 그 예는 다음과 같습니다: 3D Facial Landmark Location, Facial Boundary, yaw-pitch-roll rotation angles, landmark visibility, face representation as a graph model.
3D Facial Landmark Location. “DeFA, Dense Face Alignment”
변형 가능한 3D Dense Face Mesh 를 통해 랜드마크를 예측하는 방법입니다. 단일 2D 입력 이미지를 통해 다양한 각도와 표정에서도 mesh를 만들 수 있다는 것이 큰 특징입니다. 뿐만아니라 mesh constraints로서 “hooked” 되기 때문에, 랜드마크의 개수가 다른 데이터셋도 함께 학습이 가능하다는 특징을 가집니다. 즉, 앞서 언급한 데이터의 부족 해결하기 위해 aux. 표현으로 mesh 를 사용하고, 이를 통해 랜드마크 개수가 다른 데이터도 함께 사용하였습니다.
(구체적인 방법은 서베이 논문에 나와 있지는 않아 정확히 mesh constraint 이 무엇인지는 이해할 수 없었으나, 조만간 해당 논문을 읽어 네트워크 구조를 비롯한 디테일에 대하여 리뷰해보도록 하겠습니다)

Facial Boundaries.
“Look at Boundary: A Boundary-Aware Face Alignment Algorithm, LAB”
original input image -> ( 이 사이 중간단계 heatmap 표현인 facial boundary 를 제안) -> Landmark

- boundary module 에서는 hourglasss 네트워크를 통해 boundary heatmap 을 추정한 후,
- 두번째 모듈인 boundary-aware landmark regressor 에서 실제 랜드마크 위치를 추정합니다
1번의 중간단계 표현 덕분에 랜드마크의 정확도도 향상이 되었으며, 뿐만아니라 heatmap을 추정하는 1번 모듈에서는 서로다른 annotation을 가지는 데이터셋도 종합하여 사용할 수 있습니다. (2번 모듈은 불가능합니다. 랜드마크를 추정하는 것이기 때문에 모두 동일한 GT가 있어야 학습이 가능하기 때문입니다)
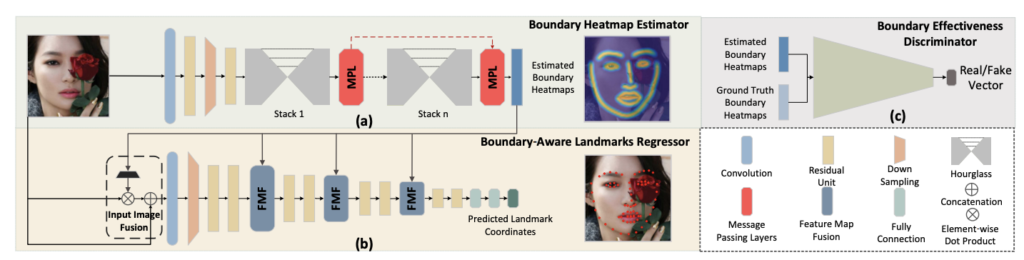
뿐만아니라, 해당 논문에서는 WIDER Face 라는 데이터셋에서 face landmark 를 위한 annotation을 직접 진행한 WFLW 데이터셋을 제안하고 공개하였습니다. 아래 그림과 같이 여러 사람, 다양한 각도, 가려짐, 메이크업, 조도 등 여러 조건이 있는 복잡한 데이터셋입니다. 정리하자면, LAB 에서는 aux. 표현으로 중간 단계 표현인 heatmap을 사용하고, 이 heatmap을 추출하는데에 필요한 학습에는 꼭 동일한 개수의 랜드마크를 가진 데이터가 필요하지 않으므로 개수가 다른 데이터를 함께 사용하였습니다. 그러나 결국 랜드마크 추출 시에는 동일한 개수가 있는 데이터만 사용 가능하기 때문에.. 이를 위해 새로운 데이터셋인 WFLW를 제안한 것은 아닌가 생각이 드네요.

(그런데 여기서 직접 라벨링했다는 WFLW 의 예시는 아래 그림을 통해 확인할 수 있는데요, occlusion 으로 인한 라벨링을 신뢰할 수 있을지에 대한 의문이 생기곤 합니다… LAB이 서베이논문 기준 AFLW 에서는 SOTA 라고 하니 추후에 읽어보고 싶네요 )

2) Redesign Loss Function
outlier들에 의한 large error의 영향을 줄이거나, prediction을 보정하는 것 같이 small-to-medium error의 영향을 증가시키기 위해 새로운 loss 를 제안하거나 사용한 방법들도 있습니다.
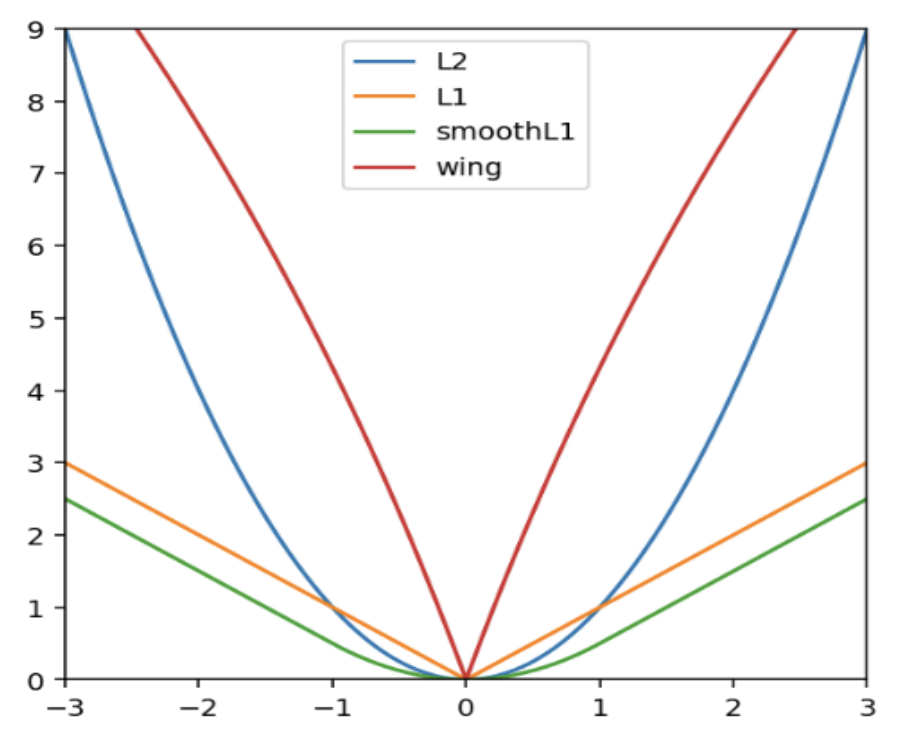
“Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks”
시작에 앞서 저자는 facial landmark prediction 을 위한 loss 함수의 연구가 많이 되지 않다고 하였습니다. 그래서 많이 사용되는 대표적인 loss를 해당 분야에서도 사용하였습니다. 예를 들어, outlier에 민감하다고 알려져있는 Direct Regression Landmark Prediction 에서는 많은 연구자들이 L2 loss를 사용하고 있고 동일한 이유로 이전 연구에서는 smooth L1 loss 가 대신 사용되었습니다. 그래서 본 논문에서는 여러 loss 를 비교하며, 새로운 loss 인 Wing Loss를 제안합니다. 아래 수식에서 ?와 ? 는 하이퍼파라미터입니다.
more attention should be paid to small and medium range errors.
The new loss amplifies the impact of errors from the interval (-w, w) by switching from L1 loss to a modified logarithm function
새로운 loss 함수는 prediction을 보정하는 것 같이 small-to-medium error의 영향을 증가시키기 위해 고안되었습니다. 따라서 L1 Loss 함수를 로그 함수로 전환하여 (-w, w)에서 error 의 영향을 더 크게 만들었습니다.
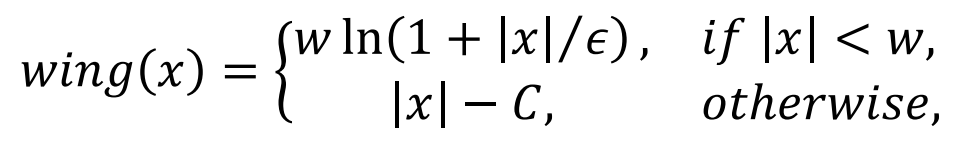
+) GAN or Adversarial Attack Method
CycleGAN (Style Aggregated Network, SAN)
본 논문에서는 데이터셋이 전혀 다른 촬영조건(eg. 조도, 컬러) 를 가지기도 하고, 동일한 이미지여도 style (eg. 조도에 의한 명암 / 흑백-컬러)을 다르게 하였을 때 다른 landmark 가 도출된다는 문제점을 언급하며 이를 해결하기 위해 GAN 을 사용합니다. 아래 이미지가 동일 이미지 다른 랜드마크 추출의 대표적인 예시입니다.
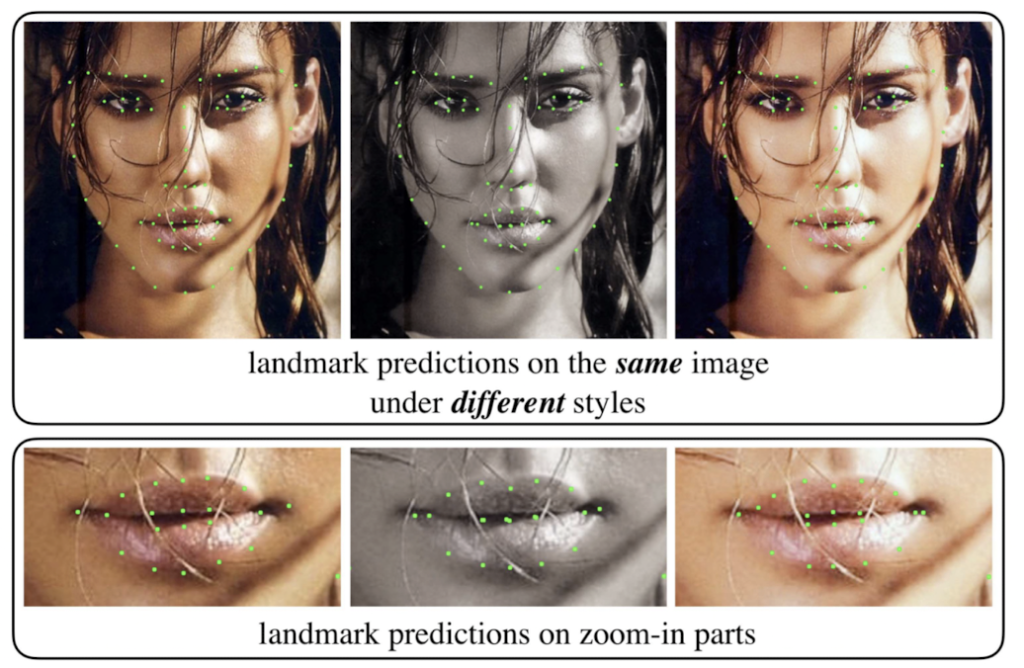
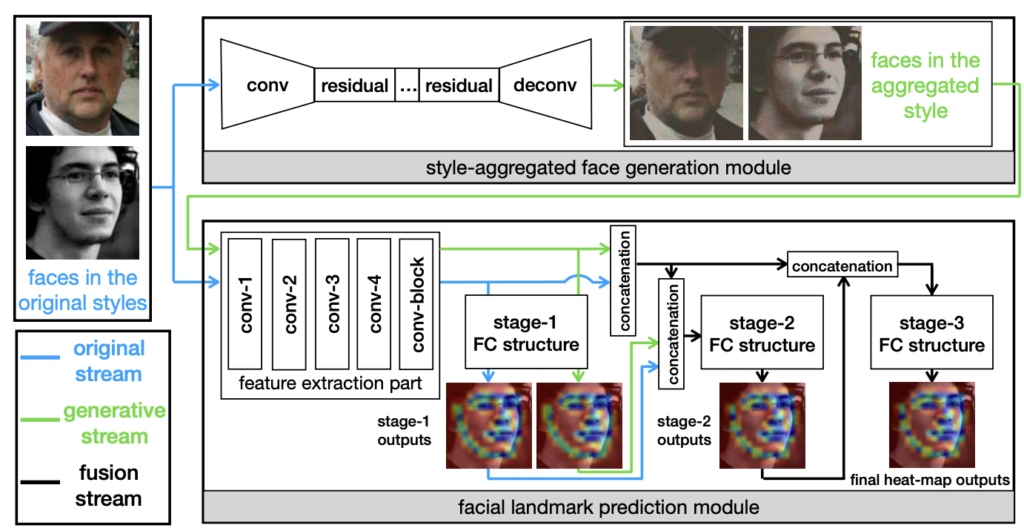
따라서 SAN 에서는 CycleGAN으로 detail 이 부족한 “neural” image를 만들고, original image 와 neural image를 pair로 학습시킵니다. neural 이미지를 만들기 위한 모듈에서 학습에 필요한 pair 이미지는 포토샵으로 만들었다고 합니다. 따라서 정보가 부족한 neural image 에서도 랜드마크를 잘 찾도록 제안한 방법론입니다.
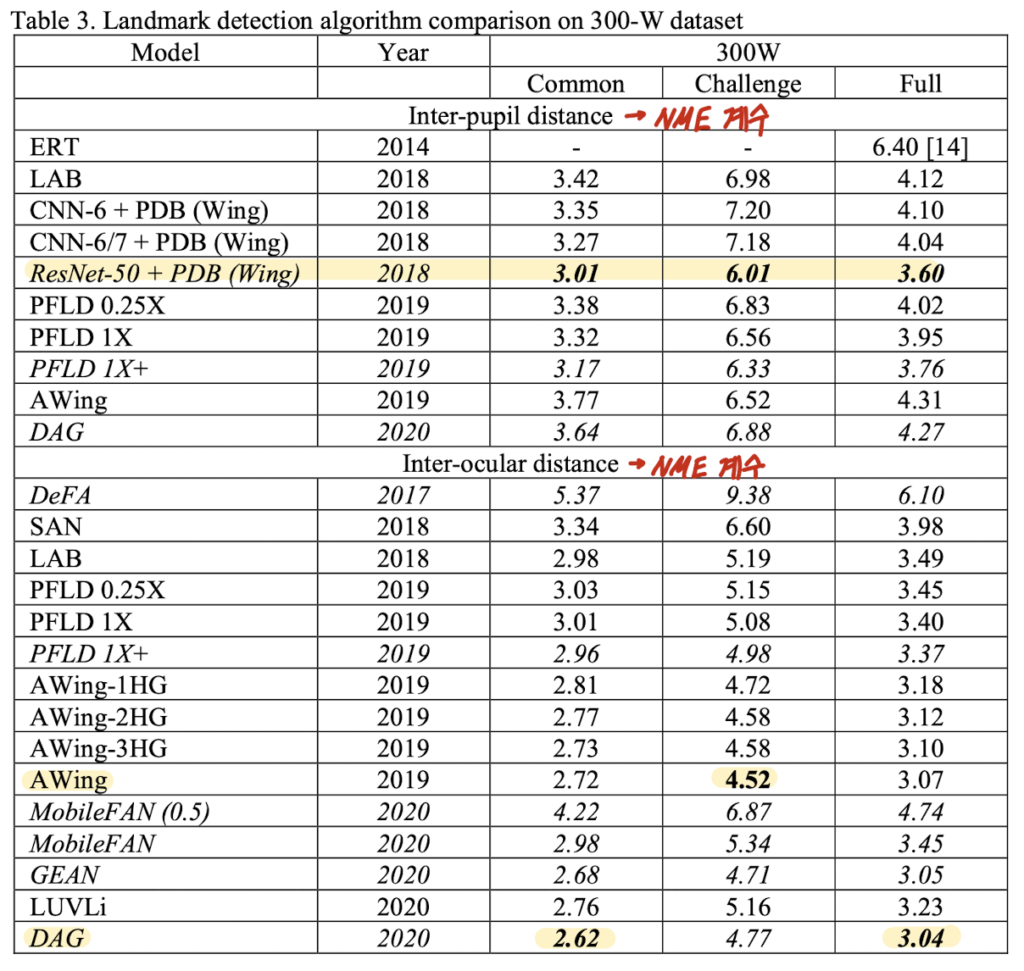
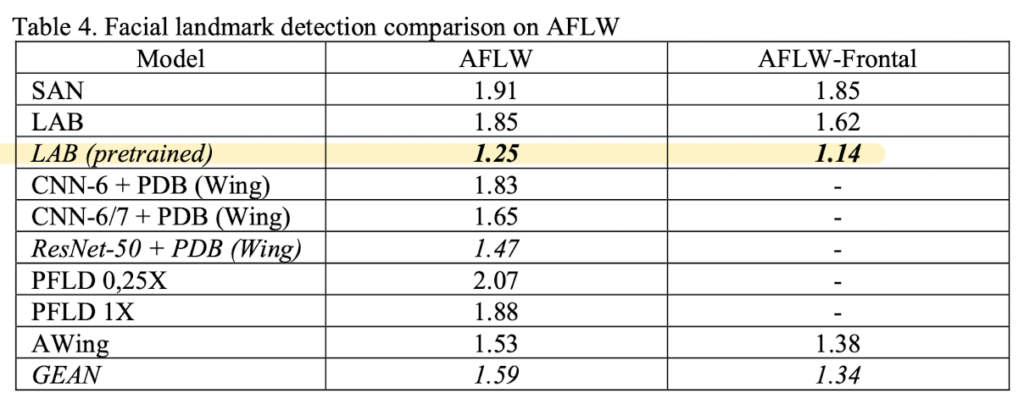
Performance
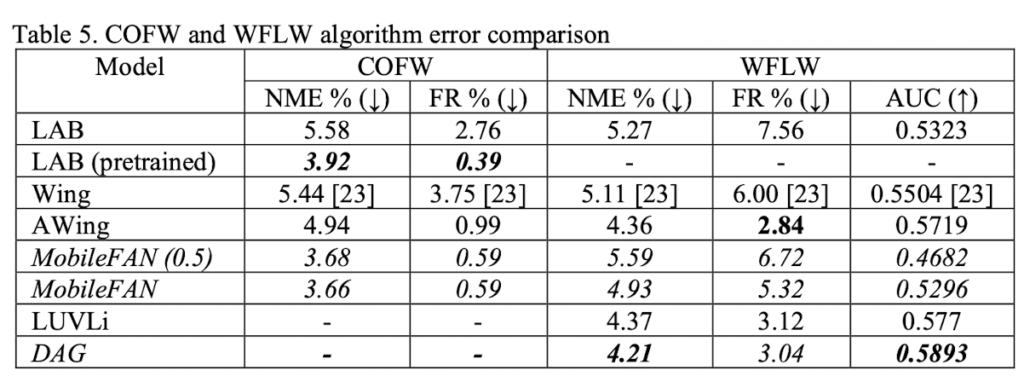
논문에 제시된 결과로 데이터셋 별 결과를 정리한 테이블입니다.
아래 테이블을 통해 같은 데이터셋 (300W 혹은 AFLW)에 한하여 지난 몇 년 동안 성능이 향상된 것은 분명하지만.. 더 실제와 같은 조건을 반영한 데이터셋인 COFW 혹은 WFLW 의 결과를 보면 성능이 다른 데이터셋에 비해 미흡합니다. 즉, 여전히 해결해야할 문제가 많은 것 같네요..
지금까지 서베이 논문에 대해 리뷰해보았습니다. 각 방법론을 너무 가볍게 다룬 것 같아 아쉽지만, 이렇게 많은 연구가 진행되고 있는지 알게된 계기가 된 것 같습니다. 그리고 약간의 감을 잡은 듯하여 다음 리뷰는 더욱 꼼꼼하게 작성해보고자 합니다.