
오늘은 이전 리뷰했던 BSN의 다음 버전 논문인 BSN++에 대해 리뷰해보려합니다. 기존 BSN은 중간 Proposal Generation Module에서 Starting point와 Ending point를 예측 및 매칭 하는 과정에서 미분이 되지 않는 점 때문에 BSN 내의 세 가지 모듈 TEM, PGM, PEM을 각각 학습하여야했습니다. 그러나 오늘 리뷰 드릴 BSN++은 Unet 구조를 활용하여 전체 네트워크를 end-to-end 구조로 변경하였습니다. 또한, 이전과 달리 Proposal 간의 relation을 활용하는 모듈 또한 추가하였으며, Data imbalance 문제를 해결하기 위해 scale-balanced re-sampling 방식 또한 도입하였다고 합니다.
1. Method
1.1 Visual Feature Encoding
여타 다른 Action Proposal, Action Detection 방법론과 동일하게 한 video를 일정 크기의 겹치지 않는 clip으로 나누고 매 clip 별로 RGB feature와 Flow feature를 추출해내어 concat한 feature를 사용하였다고 합니다.
1.2 Proposed Network Architecture: BSN++
BSN++에서는 앞서 추출된 clip-level의 feature를 입력으로 BaseNet을 거치고, 두 개의 모듈 Complementary Boundary Generator와 Proposal Relation Block으로 각각 나눠져 Proposal을 생성하게 됩니다.
- BaseNet
앞서 얻은 clip-level의 feature는 clip 길이만큼의 sequence한 정보를 포함하고 있으나 서로 겹치지 않는 clip이기 때문에 clip 간의 연관 관계가 낮은 특징을 지닙니다. BaseNet에서는 이러한 특징을 지닌 feature에 clip-level의 temporal information을 추가하고자 두 층의 1D convolution layer로 구성되어 있습니다. 해당 모듈을 거치고 나온 clip-level feature들은 이후 두가지 모듈의 입력으로 사용됩니다.
- CBG(Complementary Boundary Generator)
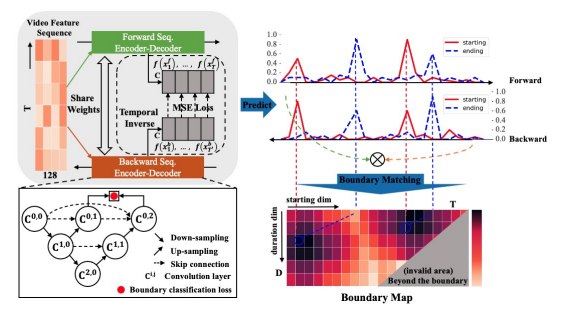
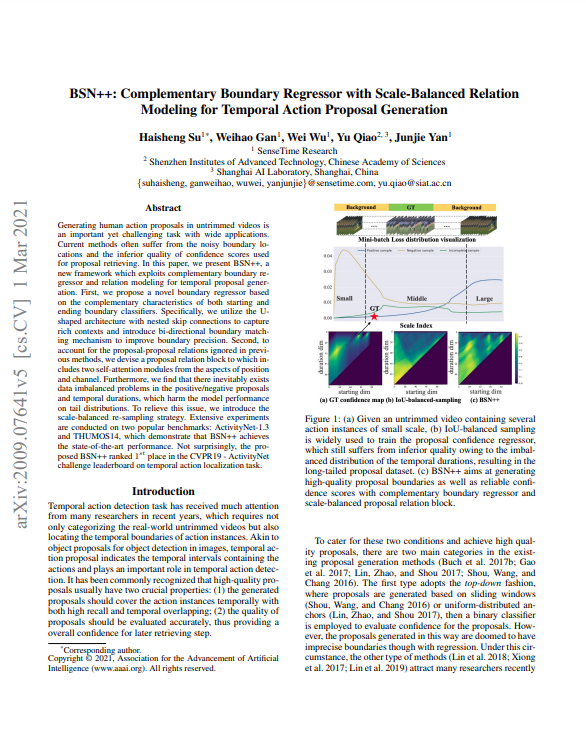
앞선 clip-level feautre가 향하는 두 가지 모듈 중 하나인 CBG에서는 Boundary를 예측하게 됩니다. Object dection에 비교하자면 localization을 담당하는 모듈입니다. 저자는 해당 모듈에서 starting point와 ending point를 예측할 때, high-level의 global text와 low-level의 local detail을 같이 볼 수 있는 UNet을 활용하였습니다. 또한, 기존 BSN에서는 시간의 흐름에 따라 starting point를 예측하고 ending point를 예측하였으나, starting point 혹은 ending point 둘 다 background와 foreground의 사이에 위치한다는 공통점을 활용하기 위해 시간의 흐름의 반대 방향으로 연산을 추가해 bi-directional한 구조를 설계하였습니다. UNet의 구조는 Fig 3의 좌측 하단 박스와 같으며 모든 convolution layer는 1D convolution layer로 구성됩니다. 이처럼 UNet 구조로 앞서 얻은 clip-level feature의 foward 방향과 backward 방향 연산을 진행한 후 각각 starting heatmap, ending heatmap을 얻게 되어 총 4가지의 heatmap으로 boundary map을 생성하게 됩니다. Foward 방향을 ->, Backward 방향을 <- 라고 표현하고, h_{i}^{s}를 i번째 clip의 starting point 확률, h_{i}^{e}를 i번째 clip의 enidng point 확률이라고 표현할 때, starting heatmap H^{s}과 ending heatmap H^{e}은 식 (1)과 같이 나타납니다.
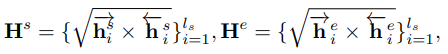
학습 시에는 식 (2)와 같이 forward 방향과 backward 방향으로 각각 starting, ending point과 GT 간의 binary logistic regression을 통해 boundary 인지 아닌지를 loss로 계산하게되며, bi-directional한 두 방향의 중간 feature(f(x_{i}^{f}), f(x_{i}^{b})) 표현력이 유사해지게 하기 위해 perceptual loss와 같은 형태로도 계산을 하여 설계하였습니다.
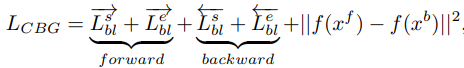
평가 시에는 식 (3)에서 Fig 3의 우측 하단과 같이 두 heatmap을 활용하여 boundary map을 생성하고 가로 방향으로 큰 값을 같는 starting point를 찾은 뒤, 해당 위치에서 세로 방향으로 proposal의 길이를 예측해 proposal을 생성하게 됩니다. 여기서 T는 비디오의 최대 길이, D는 Proposal의 최대 길이를 의미합니다.
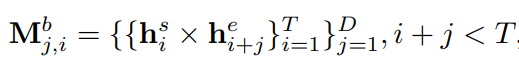
- PRB(Proposal Relation Block)
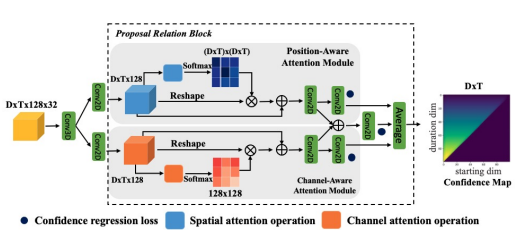
해당 모듈의 목표는 앞서 생성한 proposal feature들을 추출 후 confidence 계산하여 평가하는 것입니다. 이전 모듈과 마찬가지로 clip-level feature를 input으로 사용하며, BMN 방식에서와 마찬가지 방식으로 Conv Layer로 구성된 BM Layer를 통과 시켜 DxTx128x32 차원의 proposal feature를 추출합니다. 이후 proposal feature를 self-attention과 유사하게 서로 다른 축을 기준으로 position-aware attention과 channel-aware attention을 각각 적용시킨후 average 하여 confidence map을 계산하며, 학습 시에는 해당 map의 x축은 starting point, y축은 duration을 나타내기에 index로 localization loss를 계산하고 해당 영역 내의 confidence score로 binary classification loss를 계산해 식 (4)와 같이 학습합니다.
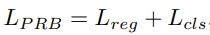
- Re-sampling
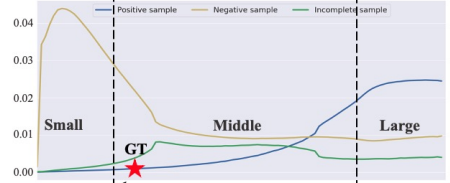
매 배치 별로 학습 시, Fig 5와 같이 foreground라 불리는 positive sample과 background라 불리는 negative sample 간의 duration 분포가 달라 학습에 방해가 되는 것을 막고자 매 배치별로 해당 비디오의 positive 길이에 따른 batch resampling 과정을 적용하였습니다. 식 (5)와 같이 scale s_{i}인 positive의 수 P_{i}의 비율이 r_{i} 일 때, lambda 보다 작다면 일정 weight를 주어 배치에 해당 크기인 positive의 비율을 늘려주었습니다. 여기서 N_{s}는 사전에 정해진 normalized scale region ([0 − 0.3, 0.3 − 0.7, 0.7 − 1.0]) 에 해당하며lambda는 경험적인 결과에 의해 0.15로 두었다고 합니다.
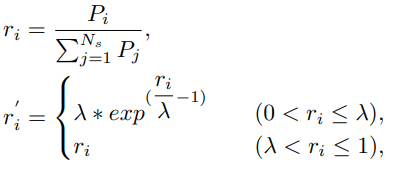
2. Experiments
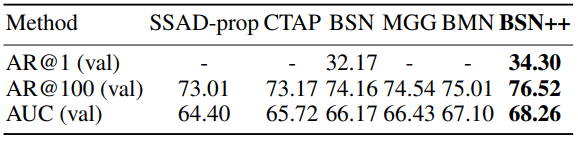
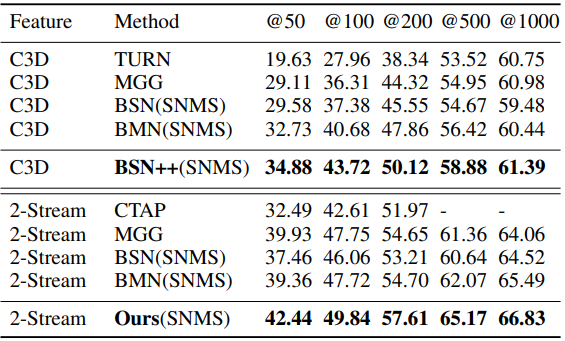
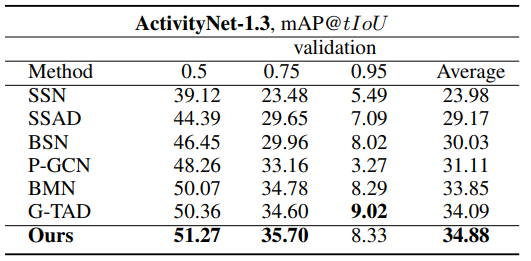
Table 1과 2는 각각 ActivityNet v1.3과 THUMOS14 데이터 셋에서 BSN++의 Proposal 성능입니다. AR@N은 N개의 proposal 중 GT가 하나라도 있으면 해당 비디오의 proposal을 맞췄다고 판단하는 지표이며 이전 SOTA였던 BMN을 웃도는 성능을 보였습니다.
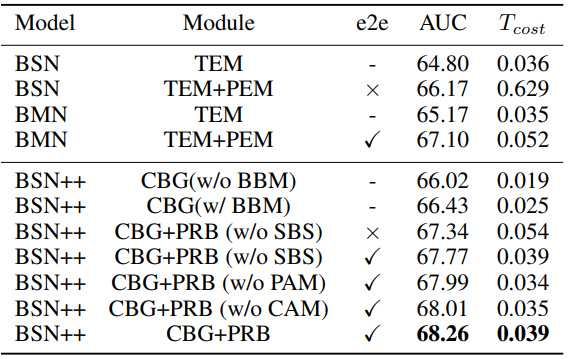
Table 3는 ActivityNet v1.3에서 BSN++의 ablation study 결과 입니다. e2e는 end-to-end 학습 방식을 사용하고 있는지, T_{cost}는 3분짜리 비디오를 처리할 때 걸리는 시간(sec)을 나타내며, SBS는 scale balanced sampling, PAM과 CAM은 PRB 내의 두 가지 attention module을 나타냅니다. 최초 버전인 BSN에 비하면 성능도 많이 올랐으며 속도 또한 약 20배 정도 빨라 진 것을 알 수 있습니다.
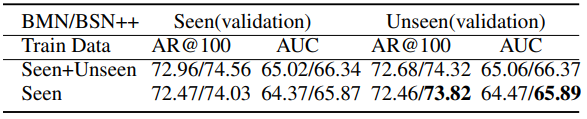
Table 4는 ActivityNet v1.3에서 학습 및 평가 시 사용하는 데이터를 각 카테고리 별로 Sports, Exercise, Recreation는 seen 으로 Socializing, Relaxing, Leisure는 unseen으로 나눈 후 generalization을 평가한 실험입니다. 이전 SOTA였던 BMN에 비해 좋은 generalization 성능을 보입니다.
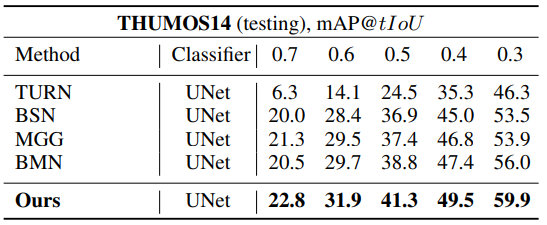
Lin et al. 2018; Liu et al. 2019; Lin et al. 2019) on testing
set of THUMOS14, where video-level classifier (Wang et al.
2017) is combined with proposals generated by BSN++
Table 5와 6는 앞선 두 데이터 셋에서 Proposal generation을 한 뒤, video-level의 classifier를 붙여 평가했을 때의 Action Detection 성능입니다. 좋은 Proposal을 생성해내는 만큼 Detection 성능도 높은 것을 확인할 수 있습니다.
3. Reference
[1] https://arxiv.org/pdf/2009.07641v5.pdf
리뷰 잘 읽었습니다.
confidence map을 만드는 부분이 BMN과는 비슷하면서도 뭔가 요즘 트렌드가 반영된 느낌이 드는 거 같네요.
확실히 Supervised라 그런지 지난번에 리뷰했던 SSTAP보다는 성능이 더 전반적으로 높은 것 같습니다.
궁금한 것은 confidence map을 만드는 부분에서 attention이 적용이 되었는데 position-aware attention과 channel-aware attention이 어떤 목적을 가지고 진행이 되는 건가요?
feature에 축에 따라 attention 이 적용됩니다