이번 논문도 Depth Estimation 논문입니다. 원래는 Transformer 기반의 Depth estimation 논문을 리뷰하려고 했었는데, self-supervised 방법론으로 나온 것은 stereo를 입력으로 사용하는 것 외에는 없는 듯 하고, 그렇다고 Supervised 방법론을 읽기에도 애매해서 그냥 CNN 기반의 Depth estimation을 리뷰로 쓰게 되었습니다.
그럼 시작합니다.
Introduction
해당 논문은 monocular depth estimation으로 학습 방식은 stereo image를 사용하는 것이 아닌, monocular video를 사용합니다. 그래서 Depth network뿐만 아니라 Camera Pose network도 같이 학습시키게 되죠.
즉 Depth network가 아무리 정확하더라도, Camera pose가 정확하지 않으면 학습에 사용되는 photometric loss가 큰 값을 가지게 되고 결국 Depth network 역시 잘못된 방향으로 학습이 될 수 있습니다. 또한 이러한 monocular training 기법에서 사용하는 warping은 한가지 가정을 전제로 진행되는데 바로 카메라만이 움직이고, 그 외에 모든 물체는 정지해 있따는 것입니다.
하지만 실제 도로 환경에서는 이러한 가정들이 대부분 다 깨지게 되겠죠? 빨간 불로 인해 내 차가 정지한다던지, 아니면 주행 중 내 앞 또는 옆에 차들이 막 움직이는 상황이 연출될 것입니다. 이러한 가정이 깨지는 경우에 depth hole이 발생한다던지, 학습에 좋지 못한 영향을 주게 됩니다.
그리고 인접한 프레임이라 하더라도 동일한 프레임으로 촬영된 stereo 영상과는 다르게 occlusion이 상대적으로 심할 수 밖에 없습니다. 이러한 occlusion은 warping된 영상과 target 영상을 정확히 비교할 수 없게 만들어 depth 네트워크가 학습하는데 있어 매우 치명적입니다.
저자는 이러한 문제를 해결해보고자 relational self-attention 기법과 새로운 data augmentation 기법을 제안합니다. data augmentation 기법은 supervised loss로 활용되어 occluded edge와 영상 경계면 쪽에서의 depth 정확도를 잘 살려주도록 하며 self attention moudle은 최적화된 feature relation을 학습할 수 있도록 해준다는데 자세한건 아래에서 살펴보시죠.
Method
일단 전반적인 학습 방식은 monodepth2와 상당히 유사합니다. 하지만 네트워크 구조들이 미세하게 다른 부분들이 많이 존재하기도 합니다.
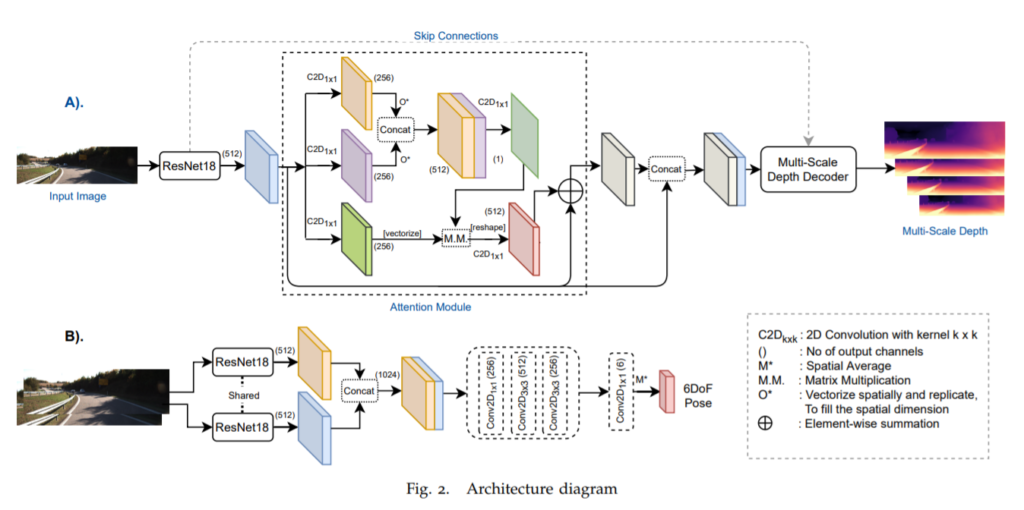
그림1은 모델 파이프라인을 의미합니다. A는 Depth network, B는 pose network로 두 네트워크의 백본 모두 일반적인 ResNet18을 사용해준 모습입니다. Depth network의 경우 Resnet18에서 타고 나온 512채널의 feature를 논문에서 제안하는 attention module을 한번 더 거쳐줍니다.
일반적으로 Self attention은 Query, Key, Value를 의미하는 1×1 컨볼루션들을 생성한 후 각각을 태워서 적절히 연산을 취해주게 되는데 해당 논문도 유사하게 3개의 서로 다른 1×1 컨볼루션을 먼저 각각 태운 후 2개(그림1에서 주황색과 보라색 레이어)는 vectorize하여 concatenate를 한 모습입니다. 그 후 다시 1×1 컨볼루션(진한 녹색 레이어)을 태운 후 연두색 layer에서 나온 feature와 행렬곱 연산을 수행합니다. 그 후 한번 더 1×1 컨볼루션(붉은색 layer)를 태워준 후 기존 ResNet18에서 나온 feature와 skip connection을 수행하고, 추가적인 연산 후에 Decoder의 입력으로 사용합니다. (생각보다 자잘자잘하게 레이어를 많이 사용했네요;;)
Monodepth2와 유사하게 Encoder-Decoder에 long skip connection을 사용하고 있고, multi scale로 depth를 추정하여 photometric loss를 계산하게 됩니다. 모든 layer의 activation function은 ELU를 사용하고 있으며 Depth를 추정하는 레이어들만 sigmoid를 사용합니다.
이렇게 추정된 target Depth D_{t} 와 target frame I_{t}는 augmentation을 적용하여 각각 I_{aug}, D^{true}_{aug}로 탄생하게 됩니다. 이 때 D^{true}_{aug}는 Pseudo Label로써supervised loss를 계산하는데 사용되며 I_{aug}는 다시 Depth network의 입력으로 들어가 D^{out}_{aug}를 추정하게 됩니다. 이러한 supervised loss는 밑에서 다시 설명하겠습니다.
Pose network 역시 ResNet18을 사용합니다. 하지만 기존의 depth estimation 방식들과는 조금 다른데, 기존에는 두 frame 입력 영상을 concat하여 한번에 encoder에 통과시켰지만, 해당 방법론은 shared한 encoder에 따로 태워서 feature를 생성한 후, 해당 feature를 concat하여 추가적인 컨볼루션 layer를 태우는 모습입니다.
Constraints for depth prediction
일단 앞부분은 self-supervised monocular training 방법론들과 모두 동일한.. 거의 정석에 가까운 loss들에 대한 설명이라서 가볍게 다루고 넘어가겠습니다.(이 논문에서는 data augmentation을 통한 loss가 사실 중요한거라..)
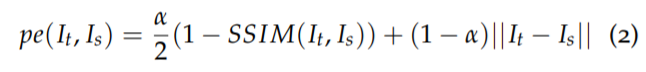
먼저 추정된 Depth와 Pose를 통해 source 영상을 target 영상으로 warping한 후 warping된 영상이 target과 얼마나 유사한지를 비교하는 photometric loss입니다. monodepth2와 동일하게 SSIM과 L1 loss를 알파 비율 만큼 사용하였는데 비율 역시 동일하게 0.85 대 0.15를 사용합니다
그리고 monodepth2와 동일하게 이전 프레임과 이후 프레임 중 loss값이 더 작은 값을 골라서 loss에 반영하게 됩니다. 이는 한쪽 프레임에서는 occlusion으로 인해 loss가 크게 생기는 반면 다른 쪽 프레임에서는 occlusion이 존재하지 않아 loss가 작아지는 경우들이 있기에 occlusion을 해결하는 방법 대안책으로 자주 쓰입니다.
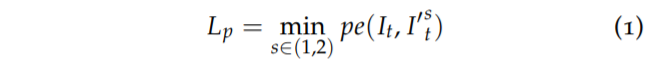
그 다음은 auto mask입니다. auto mask는 위에서 설명드린 카메라만 움직이고 물체는 정지하게 되는 가정을 깨는 물체를 제거하는 binary mask로 다음과 같이 구할 수 있습니다.
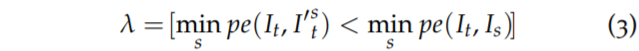
하지만 저자는 여기서 오토마스크 람다의 문제점을 지적하는데, 바로 위에 오토마스크 때문에 정적인 영역 주변에서 랜덤한 white noise가 생성되며 이는 깊이를 학습하는데 있어 민감하게 만든다고 합니다. 이러한 문제가 발생하는 이유로 저자는 해당 마스크가 단순히 photometric error 값을 부등호로 비교만 하고 주변 이웃 픽셀들에 대해서는 전혀 신경쓰지 않는다고 지적합니다.
그리하여 이 문제를 해결하고자 저자는 람다에 대하여 다음과 같은 L1 regularisation을 적용합니다.
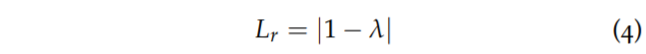
네 뭐 간단합니다. 람다가 0또는 1의 값을 가지게 되는데 최대한 1의 값을 가지도록 즉, warping한 영상과 target 영상을 비교한 photometric loss가 warping을 안한 영상과 target 영상을 비교한 photometric loss보다 작도록 하는 픽셀들이 최대한 많아지도록 loss에 추가를 한 것이죠. 이를 통해 정말로 동적인 물체를 제거하는 auto mask로서의 역할만 하기를 바란 것 같습니다.
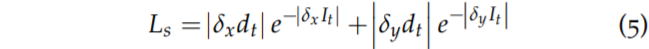
다음으로는 smoothness loss인데 추정한 depth map이 불연속적인 것을 방지하고 스무스하게 생성되고자 해당 loss를 같이 사용합니다. 물론 object boundary 같은 gradient가 살아있어야하는 곳도 스무딩처리하면 곤란하기 때문에 입력 영상의 gradient가 큰 곳은 loss가 작게 설정되게끔 되어있습니다.
Data augmentation for Depth supervision
다음은 저자가 제안하는 첫번째 contribution입니다. 저는 개인적으로 해당 내용을 흥미롭게 봤었는데 먼저 first stage에서는 위에서 설명한 loss들을 통해 depth network를 학습시킵니다.
그 다음 학습시킨 depth network로부터 입력 영상 I_{t} 을 넣고 추정한 D_{t}와 입력 영상한테 동일한 augmentation을 취하여 D^{true}_{aug}, I_{aug}를 생성합니다. 그 다음으로 다시 I_{aug}를 입력으로 새로운 Depth map D^{out}_{aug}를 생성한 후 이전에 만들어두었던 D^{true}_{aug}를 가지고 L1 loss를 통하여 Depth network를 finetuning하게 됩니다.
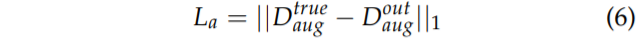
즉 요약하자면 해당 방법론은 two stage로 모델을 학습하는 것이며 첫번째 stage는 기존의 self-supervised monocular training 방식을 따르며 두번째로는 첫번째 단계에서 학습시킨 모델을 통해 추정한 depth map에 다양한 geometry augmentation을 취한 후 이를 2번째 단계에서 추정한 depth map의 pseudo label로 사용한다는 것이죠.
augmentation으로 사용된 목록들은 cropping, flipping, skewing, scaling, affine transformations가 있으며 추가로 입력으로 사용되는 RGB영상에 한해서만 brightness, gamma, saturation등과 같은 color jitter 기법들을 적용했습니다.
저자는 camera egomotion으로 발생하는 이미지 경계면 쪽에서의 occlusion에 대해 이러한 rescaling과 crop augmentation이 랜덤하게 경계 영역들을 제거하고 동시에 스케일은 기존과 동일하게 맞춰줌으로써 occlusion으로 인한 학습 부정확성을 줄이고 더욱 정확한 깊이를 추정할 수 있도록 해준다고 합니다.
Relational Self-Attention
다음으로는 저자가 Depth network에서 적용한 attention module에 대한 설명입니다. 제가 pipeline 설명할 때 같이 말씀드리기는 했으나 말로만 줄줄 한거라 수식적으로 함께 보도록 하겠습니다.
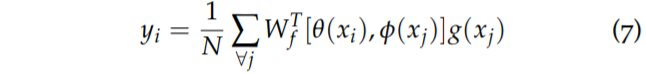
먼저 W_{f}는 weight factor로 comcatenate된 벡터를 scalar로 투영시키는 컨볼루션 weight를 의미합니다. 여기서 [ , ]는 concatenate를 의미하구 N은 X의 길이를 의미합니다. 또한 세타, 파이, g?는 각각 1×1 2D 컨볼루션을 의미합니다.
즉 입력 X에 대해서 각각 query, key, value를 표현하는 latent space로 투영시키는 컨볼루션들이 존재하는 것이며 이러한 컨볼루션을 통해 생성된 임베딩 벡터들은 다음과 같습니다.
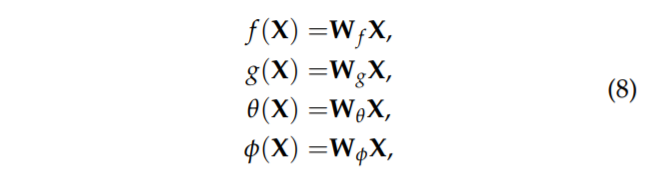
아무튼 마무리 정리를 해보자면 query(세타)와 key(파이) 사이에 관계는 W_{f}에 의해 투영되며 그 후 value(g)와 행렬곱을 취함으로써 relational self-attention을 계산하게 됩니다. 그 후 입력 X와 residual 연산을 적용함으로써 attention block의 결과값이 생성됩니다. 그 결과값은 다시 encoder의 feature와 concat된 다음에 decoder로 들어가서 depth를 생성하게 되는 것이지요.
최종적인 loss 계산은 결과적으로 다음과 같습니다.
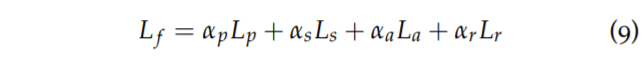
Experiments
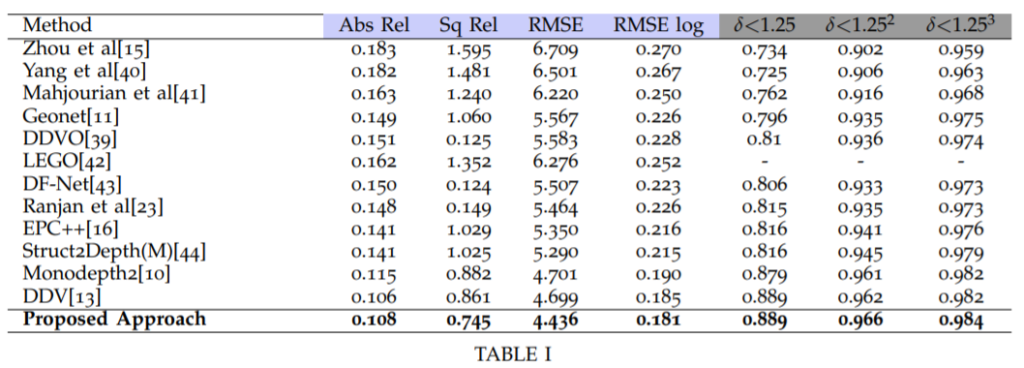
위에는 KITTI dataset에서의 정량적 평가입니다. 최근에 나온 논문들도 많은데 굳이 monodepth2보다 좋지 못한 성능들의 옛날 논문들을 박박 긁어서 리포팅했는지는 잘 모르겠지만… 그래도 (표에는 나와있지 않지만) 최근에 나온 self-supervised monocular depth estimation 방법론들 중에서 SOTA에 근접하는 성능을 보여주고 있습니다.
하지만 위에 표1에 대한 성능이 사실 정확한 비교는 아닌데 그 이유는 DDV의 경우 해상도는 monodepth2와 같지만 backbone이 ResNet18이 아닌 101이며, ADAA의 경우 ResNet18이지만 Resolution이 1024×384이기 때문입니다.
그래도 다행히 저자가 ablation study에서 양심있게 정확히 비교한 결과표도 같이 보여줍니다.

보시면 동일한 backbone과 동일한 해상도로 추정할 때 DDV와 ADAA는 Abs_rel은 서로 같으나 다른 평가 메트릭에서는 대부분 조금 더 우세한 모습을 보여주고 있습니다.
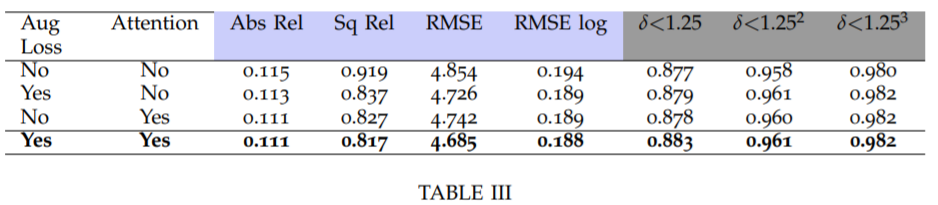
해당 테이블은 KITTI dataset에 대하여 입력영상 640×192일 때 ablation study 결과입니다. 보시면 논문에서 제안한 augmentation loss와 Attention을 사용할 때와 안할 때에 대한 성능을 나타내고 있으며 모든 평가 메트릭에서 성능 향상을 보여주고 있습니다.

다음으로는 Attention module 내에서도 어떠한 구조를 적용하는지 그리고 skip connection에다가도 attention module을 적용하게 되면 어떤지에 대한 결과를 보여주고 있는데, 사실 저는 여기서 이 저자가 어떻게든 성능을 쪼기 위해 노력한 모습이 보였습니다.
어찌보면 attention module이 상당히 복잡하다고 느꼈는데 아마 성능이 제대로 오르지 않아서 feature를 concat도 해보고, skip connection에다가도 적용해보고 여러가지로 실험을 해본 듯 합니다.
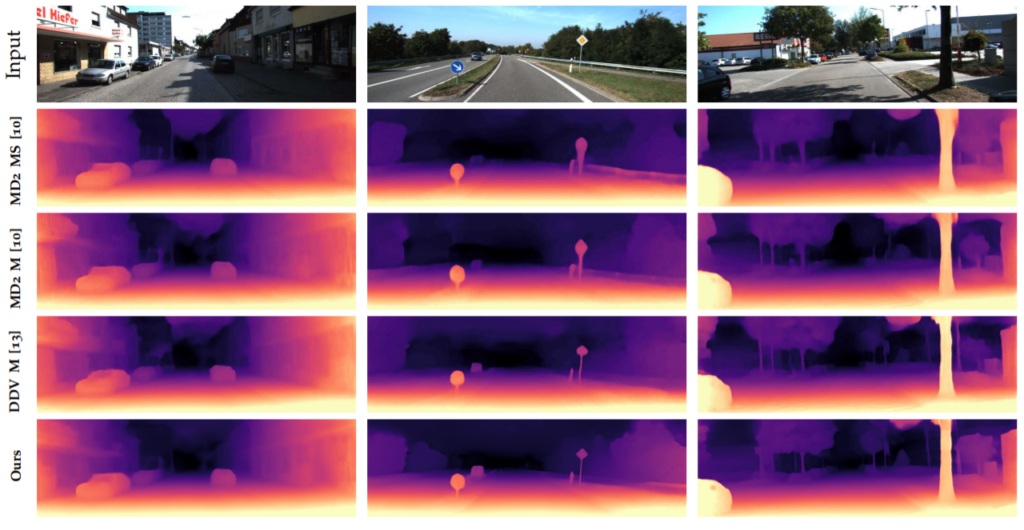
다음은 정성적 결과입니다. 2번째 컬럼에서 표지판을 상당히 샤프하게 표현하고 있으며 사실 가장 인상 깊은 점은 거리가 무한대로 측정되는 하늘에 노이즈가 없다는 점입니다. 사실 이것이 정량적 결과에서는 아무런 영향을 미치지 않지만, 정성적 결과에서는 상당히 지저분하게 보여서 신경쓰이는 것 중 하나입니다. 저자의 auto masking에 regularisation을 적용해줌으로써 하늘같이 연이은 프레임에서 변화하지 않는 곳의 번지는 현상을 예방했다고 합니다.
결론
해당 논문에서 제안한 contribution 중 data augmentation은 상당히 흥미롭게 봤었습니다. 하지만 그 외에 attention module은 무언가 성능을 쪼게 하기 위한 그리고 contribution을 하나라도 더 넣기 위한 모습으로 보여서인지 논문에서 다루는 비중과 설명이 그리 크지는 않았습니다.
그리고 정량적 평가에서 비교하는 대상들도 대부분 monodepth2 이전에 나온 옛날 방법들이고 최신 방법론이라고 해봤자 DDV 하나랑만 비교하고 있습니다. 특히 20년도 쯤에 나왔던 PackNet은 전혀 언급도 하지 않았는데 이는 정량적 성능이 메트릭에 따라 조금 모자르거나 조금 이기는 정도여서 그런 것으로 판단됩니다. 그럼에도 어떻게든 성능이 잘 나온다는 것을 어필하기 위해 1024×384 성능을 640×192 방법론들과 비교하는 곳에 보여주는 것이 많이 아쉽네요. 표에다가 입력 해상도, 백본의 크기 등을 함께 게시하여 독자들이 읽는데 오해없이 했으면 좋았을텐데 마치 논문을 자세히 읽지 않고 표1만 본 사람들한테 자기들 논문이 SOTA라는 것을 보이게끔 하는 딱 좋은 그런 표였습니다.
뭐 attention을 concat에 어떻게 적용했는지가 궁금..해지네요 그냥 skip connection할 feature를 한번 self-attention 했다고 생각하면 될까요?