
안녕하세요! X-Review 에 작성하는 첫 논문리뷰입니다. 제가 읽은 논문은 3D ConvNet 을 이용하여 비디오의 시공간적 특성을 학습하는 방법에 대한 논문 입니다. 이 방법을 사용하면 여러 video analysis tasks 에서 좋은 성능을 낼 수 있기에, 그 결과를 실험을 통해 보여줬습니다.
Abstract
이 논문에서는 Spatio-temporal featrue learning, 즉, 시공간적 특성 학습을 위한 단순하고 효과적인 방법을 제안합니다. 간략하게 설명하자면, deep 3d convolutional networks 를 사용하여 large scale 의 supervised video dataset 으로 train 시켜서 시공간적 특성을 학습합니다.
이 논문의 finding 3가지는 다음과 같습니다.
- Spatio-temporal feature learning 에는 2D ConvNets 보다 3D ConvNets 이 적합하다.
- 3D ConvNets 중에서는, 모든 layer 가 small 3*3*3 convolutional kernel 을 가진 architecture 가 성능이 제일 좋다.
- 간단한 linear classifier 를 이용해서 학습된, C3D (Convolutional 3D)는 기존의 최신 방법들 보다 성능이 좋다.
또한 이 network의 features 는 compact 하고, conceptually simple 해서 학습하고 사용하기에 쉽다고 합니다.
Intro
우선 Computer vision 커뮤니티에서 다루는 문제들에는
- Action recognition
- Abnormal event detection
- Activity understanding
등이 있다고 합니다.
이런 video tasks 들을 해결하는데 필요하기 때문에, 효과적인 generic video descriptor 에 대한 수요가 증가하고 있다고 해요. 이때, 효과적인 descriptor 가 되기 위해서는 아래의 4가지 특성이 필요하다고 합니다.
- generic
- 서로 다른 종류의 videos 들을 잘 표현하고, 구별하기 위해서
- compact
- processing, storing, and retrieving 등을 더 쉽게 수행하기 위해
- efficient to compute
- 빠르게 실행하기 위해
- simple to implement
- 간단한 모델에서도 잘 작동하기 위해
그런데, image based deep features 는 motion modeling 이 부족하기 때문에 videos 에 적합하지 않다고 해요. (이건 Section 4,5,6을 통해 확인 수 있다고 합니다.) 그래서 이 논문에서는 deep 3D ConNet 을 사용해서, spatio-temporal fatures 를 배울 것을 제안합니다. 이때 간단한 linear classifier 를 이용하여, 이 learned features가 여러 video analysis tasks 에서 좋은 성능을 내는 것을 실험적으로 보여줍니다.
Learning Features with 3D ConvNets
해당 섹션에서는, 3D ConvNets 의 basic operations 에 대해 설명하고, 실험적으로 3D ConvNets의 여러 구조에 대해 분석을 하고, feature learning 을 위해 이 3D ConvNets 들을 어떻게 train 해야 하는지에 대해 정교하게 설명합니다.
3D convolution and pooling
2D ConvNet 과 비교했을 때, 3D ConvNet 은 3D Convolution / pooling operations 을 사용하기 때문에 temporal 정보를 더 잘 model 하는 능력을 갖고 있다고 합니다.
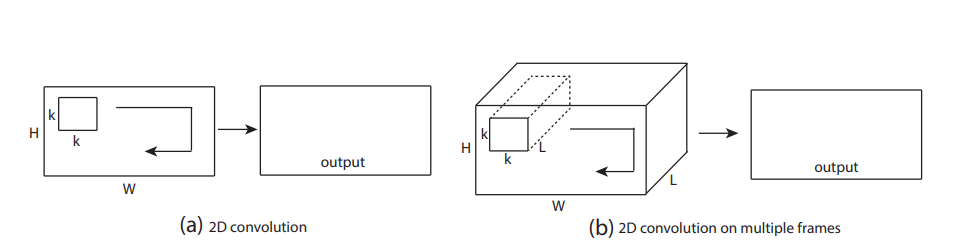
(a) 하나의 이미지에 대해 2D Convolution 하면 하나의 이미지를 output 으로 내보내고
(b) 여러 개의 이미지 (채널) 에 대해 2D Convolution 해도 하나의 이미지를 output 으로 내보냅니다.
→ 2D ConvNets 는 convolution operation 을 적용한 후에는 input signal 의 temporal 정보를 잃게 됩니다. 즉, spatial 정보만 갖게 되는 것이죠.
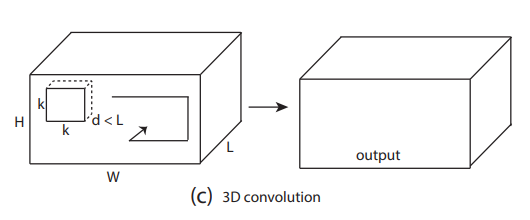
(c) 반면, 3D Convolution 은 input signal 의 temporal 정보를 보존하여 output volume 을 내보냅니다.
→ 3D ConvNets 은 convolution operation 을 적용한 후에도 spatio-temporal 정보를 잃지 않습니다.
위의 이미지는 convolution 에 대한 것이지만, 같은 현상은 2D / 3D polling 에 대해서도 마찬가지입니다. (convolution 은 학습될 수 있다는 것을 제외하면, 어쨌든 유사한 operation 이니까요)
이것보다 먼저 나온 논문들에서 발췌한 내용을 살짝 언급하자면, 아래와 같습니다.
- 해당 논문에서 temporal stream network 에 multiple frames 를 input 으로 집어 넣더라도, 2D Convolution 때문에 첫 번째 convolution layer 에서 temporal 정보가 완전히 collapsed 된다. [K. Simonyan and A. Zisserman. Two-stream convolutional networks for action recognition in videos. In NIPS, 2014.]
- 해당 논문에 2D convolutions 을 사용하는 fusion models 들이 나오는데, 대부분의 networks 들이 첫번째 convolution layer 이후에 input 의 temporal signal 을 잃게 된다. 그런데 이 논문에 나오는 모델 중에 Slow Fusion model 은 처음 2개의 convolution layer에서 3D convolution / pooling 을 사용하고, 성능이 가장 좋다. 그래서 우리는 성능이 좋은 key reason 이 바로 3D convolution / pooling 을 사용했기 때문이라고 본다. 아무튼, 이 모델 또한 세번째 convolution layer 이후에 temporal 정보를 모두 잃기는 한다. [A. Karpathy, G. Toderici, S. Shetty, T. Leung, R. Sukthankar, and L. Fei-Fei. Large-scale video classification with convolutional neural networks. In CVPR, 2014.]
3D ConvNets 를 위한 good architecture 를 identify 하려고 하는데, large-scale dataset 에 대해 사용하면 시간이 너무 많이 드니까, 우선 medium-scale dataset 인 UCF101에 대해 실험을 해봤다고 합니다.
* UCF101
- UCF101 is an action recognition data set of realistic action videos, collected from YouTube, having 13320 videos from 101 action categories
Notation
video clip 의 사이즈는 c * l * h * w 로 설정한다.
- channel 수, length (frames 수), height, width (각 frame 의 size))
3D convolution / pooling kernel size 는 d * k * k 로 설정한다.
- d = kernel 의 temporal depth
- k = kernel 의 spatial size
Common Network Settings
우리가 train 시킨 모든 networks 에 적용한 network settings 를 describe 하는 내용이다.
- network의 input은 video clips 이고, class labels (101 different actions) 를 predict 한다.
- video frames 는 128 * 171 로 resize 된다. (UCF101 frames 의 대략 절반 정도의 resolution 이라고 한다. 아마 시간을 줄이기 위해 이렇게 하지 않았나 싶다.)
- videos 는 networks 의 input 으로 사용될 때 non-overlapped 인 16-frame clips 로 split 되어 사용된다.
- 따라서, input dimension 은 3 * 16 * 128 * 171 가 된다.
- training 할 때, 3 * 16 * 112 * 112 의 input clips으로 random crop 을 해서 jittering 을 사용한다.
- networks 는 5개의 convolution layer 와 5개의 pooling layer 가 있고, (각 conv 뒤에 pool 하나씩 있음.)
- 2개의 fully-connected layer와 1개의 softmax loss layer 가 있어서 action label을 predict 한다.
- 5개의 convolution layer 1 ~ 5 에 대한 filters의 갯수는 각각 64, 128, 256, 256, 256 이다.
- 모든 convolution kernels 는 d size 이다. (d 는 kernel temporal depth) (+ 나중에 d 의 값을 바꾸면서, 좋은 3D architecture 를 찾아볼 것임)
- 모든 convolution layer 는 시공간적으로 적절한 padding 을 갖고 있고, stride 는 1 이다. (이렇게 하면, input 을 conv 에 태운 후에 output 으로 내보냈을 때 size가 안 바뀜)
- 모든 pooling layers 는 kernel size 가 2 * 2 * 2 이고 (첫번째 layer 를 제외하고는) stride 가 1인 max pooling layer 이다. 따라서 output 의 size는 input 의 1/8로 줄어들게 된다.
- 1st pooling layer 는 kernel size 가 1 * 2 * 2 인데, 이건 temporal size를 너무 일찍 merge 하지 않기 위한 의도를 담고 있다고 한다. 또한, 16 frames 의 clip length 를 만족하기 위함이다. (설명을 추가하자면, convolution layer 가 5개니까, 1/2 로 줄어드는 pooling 을 4번 하려면 5번 중 1번은 안 해야하는데, 그걸 1st pooling layer 에서 안 하는 것이다. d = 1 로 만들어서! 즉, L (16) 또한 d (2) 값에 의해 16, 8, 4, 2, 1로 점점 줄어들게 될 것인데, 그걸 1st pooling 에서 안 하는 것이라고 이해했다.)
- 2개의 fully connected layers 는 2048 outputs 을 내보낸다.
- 우리는 초기 learning rate 은 0.003 으로, mini-batches of 30 clips 를 사용해서, networks를 맨 처음부터 훈련시킨다.
Varying network architectures
이 논문의 주요 관심사는 deep networks 를 통해 어떻게 temporal information 을 종합하는지에 있습니다. 이때 좋은 3D ConvNet architecture를 찾기 위해서, 아까 언급했던 다른 세팅들은 다 고정해두고, kernel 의 temporal depth 인 d 값만 조정하여 실험합니다.
이 때 실험하는 architectures 는 2가지 types 이 있습니다.
- homogeneous temporal depth : 모든 convolution layers 는 같은 kernel temporal depth 를 가짐
- d = 1, 3, 5, 7 인 4가지 networks를 살펴봄 (depth-d 라고 각각 부를 예정)
- 이때, depth-1 net은 separate frames 에 대해 2D convolutions 를 적용하는 것과 같다.
- varying temporal depth : kernel temporal depth 는 layers 에 따라 달라짐
- temporal depth 가 증가 / 감소하는 2가지 networks 를 살펴봄 (순서대로 1st ~ 5th layers 의 depth)
- increasing 하는 경우 : 3-3-5-5-7
- decreasing 하는 경우 : 7-5-5-3-3
이 networks 모두 last pooling layer 의 output signal 이 같은 size를 갖게 되는데, 이건 fully connected layers 의 parameters 수와 동일합니다. 따라서 이 network 들 모두 fully connected layer 의 parameter 수가 같게 되죠. networks 들의 parameters 수는, 오직 convolution layers 에서 서로 다른 kernel temporal depth 때문에 달라지는데, 이 차이는 fully connected layers 의 millions of parameters 에 비교하면 상당히 작은 편이라, architecture search 의 결과에 영향이 없을 것이라고 합니다.
Exploring kernel temporal depth
UCF101 의 train split 1 에 대해 networks 를 train 시켰을 때, different architectures 에 대한 clip accuracy 는 Figure 2. 의 이미지처럼 나왔다고 합니다.
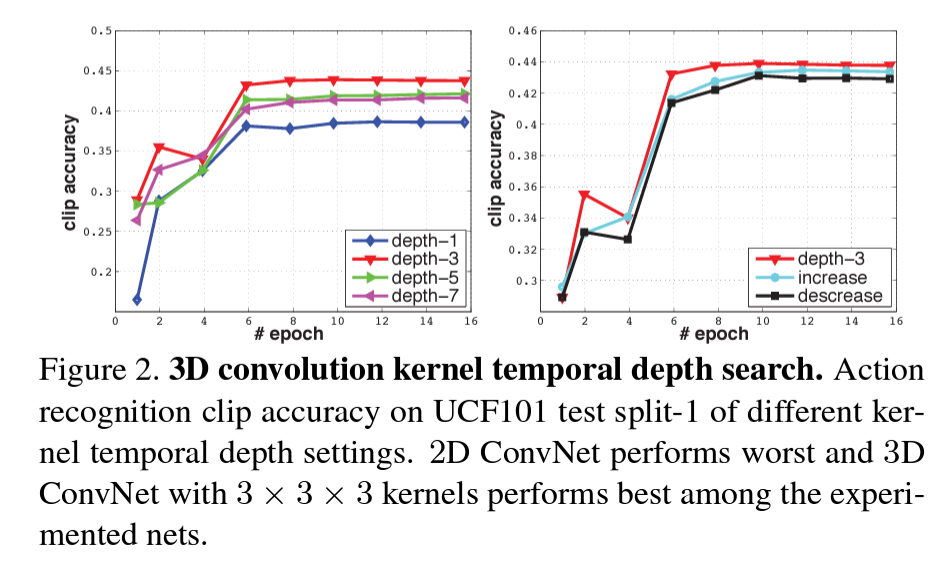
따라서, 이 결과를 통해 아래의 2가지를 알 수 있습니다.
- 2D ConvNet (depth-1) 보다 3D ConvNet(나머지) 이 성능이 좋다.
- 3D ConvNet 중에는 3 * 3 * 3 kernel (depth-3)이 성능이 가장 좋다.
더 큰 spatial receptive field (e.g. 5 × 5) 를 갖거나, full input resolution (240 × 320 frame inputs) 을 가진 경우를 실험해도 비슷한 양상을 보였다고 합니다.
Spatiotemporal feature learning
Network Architecture
이제, 3*3*3 kernel 의 3D ConvNet 이 가장 좋은 선택이라는 걸 알게 됐기 때문에, Figure 3. 과 같은 C3D architecture 라는 모델을 디자인 했습니다.

Dataset
Spatiotemproal features 를 학습하기 위해서, Sports-1M dataset 으로 C3D 를 train 시킵니다.
*Sporst-1M
- It is currently the largest video classification benchmark. The dataset consists of 1.1 million sports videos. Each video belongs to one of 487 sports categories. Compared with UCF101, Sports1M has 5 times the number of categories and 100 times the number of videos.
Sports-1M Classification Results
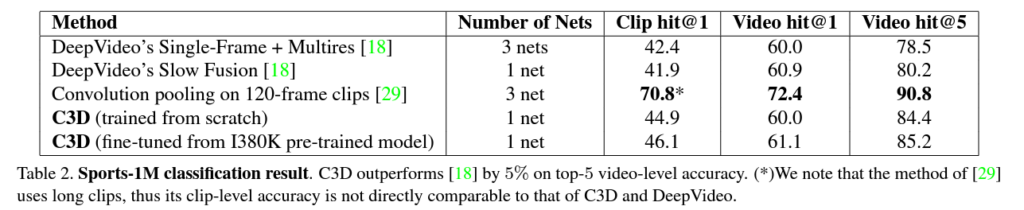
Table 2. 를 보면 C3D networks 가 DeepVideo’s networks의 성능을 능가함을 알 수 있었습니다. [29]이 C3D 보다 성능이 좋기는 한데, 이 메소드는 더 긴 120 frames 을 사용하기 때문에 C3D랑 DeepVideo 와 직접적으로 비교하기에는 좀 무리가 있다고 합니다. 여기서 주목해야하는 건, [29] 의 Clip hit@1 과 Video hit@1 의 차이가 1.6% 으로 작다는 것입니다. 실제로, [29] 를 C3D features 에다가 적용시키면 video hit performance 를 더 향상시킬 수 있다고 합니다.
C3D Video Descriptor
training 이 끝나면, C3D 는 video analysis tasks 에 대해 feature extractor 로 사용될 수 있습니다. C3D feature를 뽑기 위해서, 하나의 비디오를 16 frame 의 clips 로 쪼갭니다. 이 때 두개의 연속적인 clips 사이에는 8-frame overlap 이 있다고 합니다. (이건 왜 이렇게 하는 지에 대해서는 안 나와있지만, 추측컨데 이렇게 하면 clips 수가 거의 2배가 되니까 학습을 더 잘하기 위해서가 아닐까 싶습니다.) 이 클립들은 fc6 activations 를 뽑아내기 위해 C3D network 에 전해집니다. 클립 fc6 activations 들은 4096-dim video descriptor 를 형성할 수 있도록 averaged 되고, 그 다음에 L2-normalization 이 수행됩니다. 이렇게 해서 만들어진 representation (표현)을 C3D video descriptor/feature 라고 말합니다.
What does C3D learn?
C3D가 내부적으로 뭘 학습하고 있는지 이해하기 위해, deconvolution method 를 사용해봤다고 합니다. 이를 통해, C3D 는 처음 몇 프레임의 모습에 집중하는 걸로 시작하고, 그리고 그 다음 프레임들의 salient (두드러진) motion 을 track 한다는 걸 알 수 있었다고 합니다.
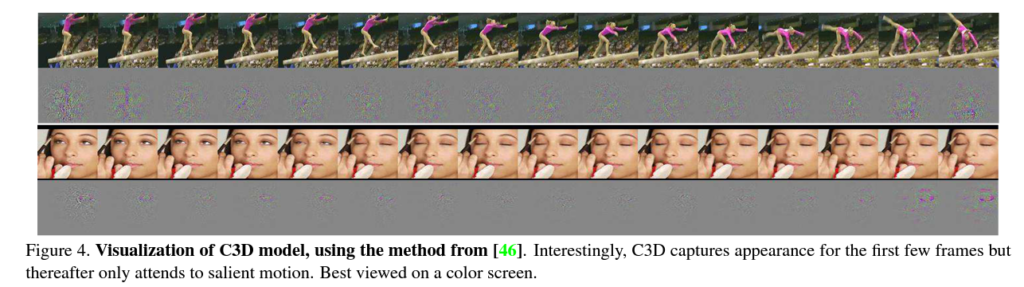
첫 번째 예시 (Figure 4. 의 위쪽 그림)
feature 는 우선 whole person에 집중하고, 그 다음 나머지 프레임들에서 pole valut performance 하는 motion 을 track 합니다.
두 번째 예시 (Figure 4. 의 아래쪽 그림)
feature 는 우선 eyes에 집중하고, 그 다음 make up 을 받는 동안 eyes 주변에서 일어나는 motion 을 track 합니다.
따라서, C3D 는 motion 과 appearance에 선택적으로 attend 한다는 것을 알 수 있었습니다. 이는 standard 한 2D ConvNet 와는 다른 점이라고 하네요!
그리고 다음 섹션에서부터는 learned feature 에 대한 insight 를 주기 위한 시각화 보충 자료입니다. 앞에서 언급했던 3가지 video tasks를 순서대로 다룹니다.
Action recognition
Dataset
- UCF101
Results
- 세 가지의 nets 을 사용하여 뽑아낸 C3D descriptor 에 대해 실험을 해보았는데, I380K 으로 trained 되고 Sports-1M으로 fined-tuned 된 C3D 가 가장 성능이 잘 나와서 (약 1% 정도) 이걸로 결과를 냈다고 합니다.
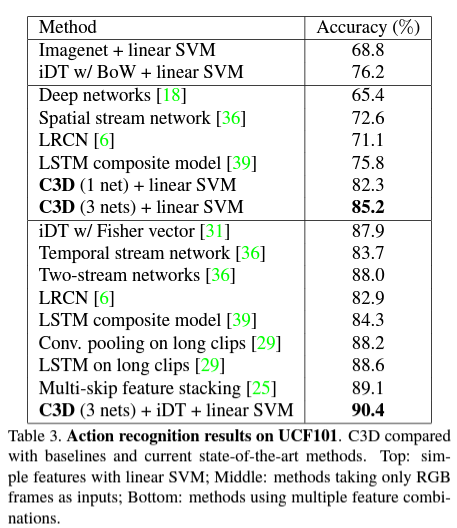
여기서 주목할 만한 것은, C3D 가 iDT 와 합쳐졌을 때 accuracy 가 90.4%로 (+ 5.2%) 올랐다는 것입니다. 반면 C3D 가 ImageNet과 합쳐졌을 때는 0.6% 올랐다고 합니다. 이건 C3D 가 appearance 와 motion 정보를 잘 capture 했기 때문에, appearance based deep feature 인 ImageNet 과 합쳐졌을 때 이점이 별로 없었음을 의미합니다.
이와 다르게, C3D 를 iDT와 서로를 보완하는 효과가 있어 합치는 것에 이점이 있다고 합니다. 실제로 iDT 는 optical flow tracking 과 low-level gradients 에 대한 histograms 에 based 된 hand-crafted features 인데, 반대로 C3D 는 high level abstract / semantic 정보를 capture 하기 때문에 높은 accuracy 를 낼 수 있었습니다. (low-level 과 high-level 이기 때문에, 서로 보완한다는 뜻으로 이해했습니다.)
C3D is compact
C3D features 의 Compactness (효과적인 descriptor 에게 필요한 특성 중 하나) 를 평가하기 위해, PCA 를 사용하여 features 를 더 낮은 dimensions 로 project 시키고, linear SVM을 사용하여 projected features 의 classification accuracy 를 report 했습니다. 같은 process 를 iDT features 와 ImageNet features 에도 적용시켰고, 그 결과를 비교한 것이 Figure 5. 입니다.
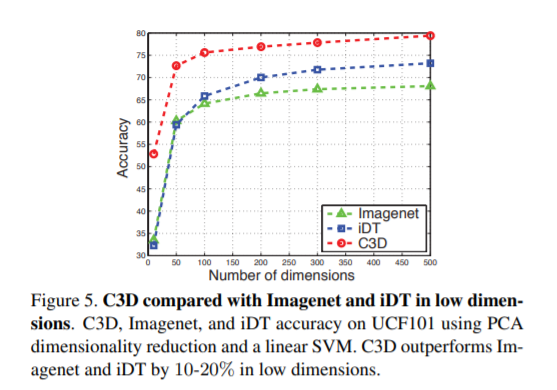
이를 통해, C3D features 가 compact 하고 discriminative 함을 알 수 있었습니다. 이런 특성을 갖기 때문에 low storage cost 와 fast retrieval 이 중요한 large-scale retrieval application 에서 굉장히 도움이 된다고 합니다.
또한, learned C3D features 가 좋은 video 에 대해 generic feature 인지 평가하기 위해 다른 데이터셋에 대한 learned feature embedding 을 시각화 해봤다고 합니다. Figure 6 은 UCF101 데이터셋에 대한 Imagenet 과 C3D 의 feature embedding 을 시각화 한 것이고, 이때 원하는 결과를 얻기 위한 추가적인 fine-tuning 같은 건 하지 않았다고 합니다.

이를 통해 C3D 가 Imagenet 보다 좋다는 것을 확인할 수 있었습니다.
Action Similarity Labelling
Dataset
- ASLAN
- The ASLAN dataset consists of 3, 631 videos from 432 action classes. The task is to predict if a given pair of videos belong to the same or different action.
Results
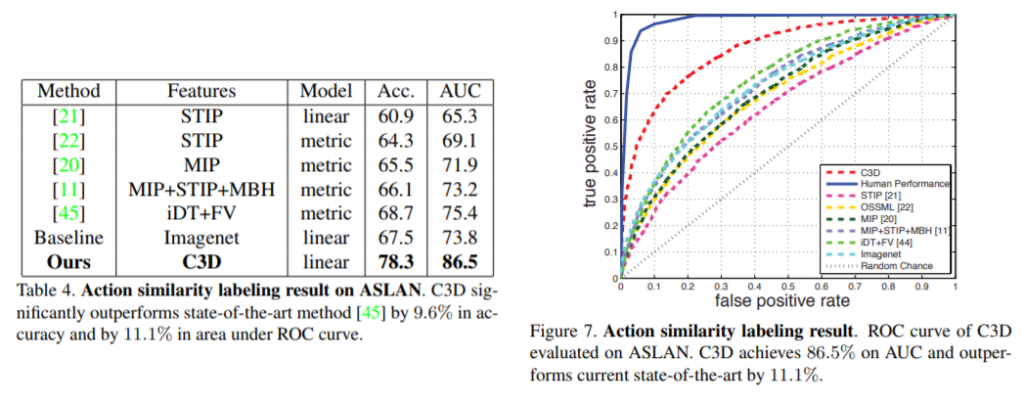
Table 4. 에서, C3D 를 state-of-the-art methods 들과 비교해보았습니다. C3D의 성능이 Accuracy 와 AUC 둘 다 가장 좋음을 알 수 있었습니다.
* AUC
- The Area Under the Curve (AUC) is the measure of the ability of a classifier to distinguish between classes and is used as a summary of the ROC curve. The higher the AUC, the better the performance of the model at distinguishing between the positive and negative classes.
Figure 7. 은 앞에 언급했던 메소드들, human performance, C3D의 ROC curves 를 비교하여 plot 해줍니다. C3D 는 human performance (98.9%) 절반 정도로, 다른 최신 메소드들과 비교했을 때 엄청난 발전을 보였습니다.
Scene and Object Detection
Datatsets
Scene recognition : 2가지 benchmark에 대해 C3D를 평가합니다.
- YUPENN : 420 videos of 14 scene categories
- Maryland : 130 videos of 13 scene categories.
Object recognition
- egocentric dataset : 42 types of everyday objects. (이 데이터셋 모든 영상들이 1인칭 시점이라서 training dataset 에 있는 비디오들과 꽤 다른 appearance와 motion 특성을 갖고 있습니다.)
Results
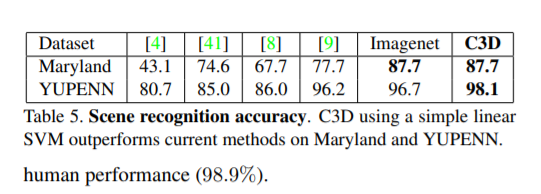
Scene Recognition
Table 5. 를 통해 다른 메소드들에 비해 C3D의 accuracy 가 더 높다는 것을 알 수 있습니다. 주목할만한 점은, C3D는 clip features 를 단순히 averaging 하는 linear SVM 만 사용하는 반면에, [9] 는 complex feature encodings (FV, LLC, and dynamic pooling) 을 사용했다는 것입니다. 그럼에도 불구하고 C3D가 성능이 더 좋습니다.
Object Recognition
C3D 이 22.3%의 accuracy 로 메소드 [32] (X. Ren and M. Philipose. Egocentric recognition of handled objects: Benchmark and analysis. In Egocentric Vision workshop, 2009)보다 성능이 10.3% 좋다고 합니다. 주목할만한 점은, C3D는 아까도 언급했듯이 linear SVM 을 사용하는데, [32]는 RBF-kernel on strong SIFT-RANSAC feature matching을 사용한다고 합니다.
Imagenet baseline과 비교했을 때는 C3D 가 성능이 3.4% 더 안 좋은데, 이건 input resolution 이 C3D는 (128 × 128) 이고, Imagenet 은 full-size resolution (256 × 256) 을 사용하기 때문이라고 설명할 수 있습니다. 또한 C3D 는 fine-tuning 없이 Sports-1M videos (487 categories) 에 대해 train 하는 반면, Imagenet 은 1000 object categories 에 대해 fully trained 되기 때문에, 이 task 에서는 C3D의 성능이 낮은 것이 어찌보면 당연합니다.
이 결과는 C3D 가 video에서 appearance / motion 정보를 capture 하는데 얼마나 generic 한 descriptor인지 보여줍니다. (Scene / Object 2가지 문제에서 다 효과적이기 때문에, generic 하다고 이해했습니다.)
Runtime Analysis
UCF101 dataset 에 대한 C3D, iDT [44], Temporal stream network [36] 의 Runtime을 비교했습니다.
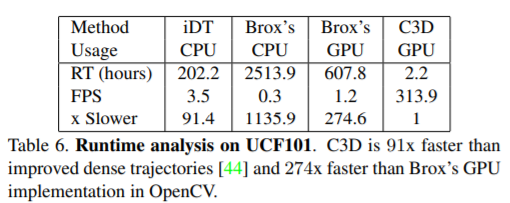
주목할 점은, 다른 메소드들은 processing speed가 4 fps 보다 낮은 반면, C3D는 313 fps 으로 훨씬 빠르다는 것입니다.
Conclusion
다시 한 번 말하자면, 이 논문에서는 large-scale video datasets 에 대해 train 시킨 3D ConvNet 으로 시공간적 특성을 학습하는 문제에 대해 다뤘습니다. 요약하자면 아래와 같습니다.
- 2D ConvNet 보다는 3D ConvNet 이 좋다.
- 3D ConvNet 중에는 3 * 3 * 3 의 kernel size 가 가장 성능이 좋다.
- C3D features with linear classifier가 video analysis benchmarks 에 대해 여태껏 가장 좋았던 메소드의 성능을 능가하거나, 근접한다.
- 제안된 C3D features 가 efficient, compact, simple to use 하다.
그럼 이상으로 논문 리뷰 마치겠습니다!
논문
- https://openaccess.thecvf.com/content_iccv_2015/html/Tran_Learning_Spatiotemporal_Features_ICCV_2015_paper.html
참고자료
- https://www.analyticsvidhya.com/blog/2020/06/auc-roc-curve-machine-learning/
중간 Figure 4 그림 예시에서 회색 부분이 어떤 것을 의미하나요?
C3D가 track 하지 않고 있는 부분이기 때문에, 이전 / 이후의 프레임과 비슷하거나 동일한 값을 가진 프레임을 의미한다고 이해했습니다! 주석으로 달린 [46] 논문도 찾아봤는데, 회색 부분에 대한 언급은 없는 것 같아서 모델이 학습하는 부분은 아니라고 생각했습니다.