다시 또 돌아온 … 그녀석…. 입니다
저번 리뷰에서 였나..? 제가 연구가 잘 진행되고 있지 않다..? 이런식의 말을 했던 것 같은데, 어디서 자꾸 논문이 나오는 건가 싶을 것 같습니다. ㅋㅋ 이제 거의 다 한 것 같습니다….. Sensors 까지 오게 되다니…. 전통 Self-supervised 방식은 왠만한건 다 본 것 같아요 ㅋㅋ 이 다음은 뭐가 될런지… 궁금하네요.
이번 논문은 예전에 신정민 연구원이 리뷰했었던 Featdepth를 거의 모방한듯한 논문입니다. 담고 있는 의미가 유사한 것 같아요. 그럼 리뷰 시작하도록 하겠습니다. 아 시작하기에 앞서 이 논문은 딱히 배울 점이 없는 논문이니 넘어가도 좋을 것 같다는 점을 알려드리고 시작을 하도록 하면서 독자의 시간을 아끼도록 하겠습니다.
이 논문의 contribution은 다음과 같습니다.
- 기존 photometric loss의 단점을 보완하고자 영상을 warping 하여 사용하지 않고 feature map을 warping 하여 계산함
- smoothness loss를 1차미분 2차미분을 통해서 계산함
- 백본을 변경 ( 굉장히 뭔가 많이 바꾼거 같긴한데 딱히 큰 의미를 두고 바꾼거 같진않음)
1 같은 경우 featdepth를 거의 그대로 사용한 느낌이고, 3은 억지로 쥐어짜낸 느낌이라… 흠… 마음엔 들지 않네요.. 그래도 성능을 올렸다는 점에서 네트워크를 들여다 보았습니다.
- Method
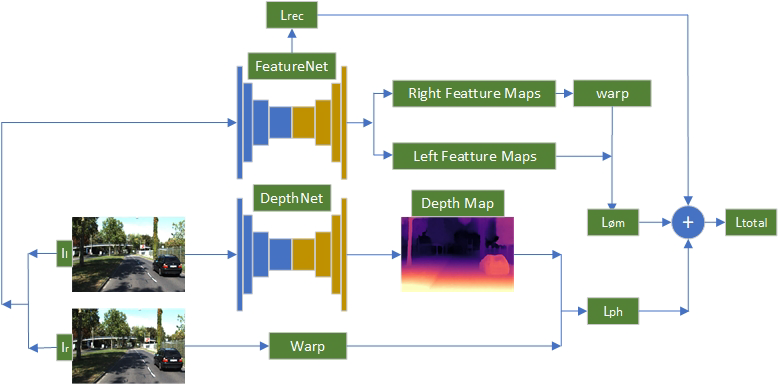
이 논문은 일단 제가 계속 가져왔던 Mono video 가 아닌 monodepth1과 같인 stereo 기반으로 진행을 했습니다. 사실 이부분도 마음에 안드는게 먼가 Featdepth가 mono video로 해서 아예 stereo로 튼 느낌이랄까…. featurenet 저건 아무리 봐도 Featdepth의 아이디어가 아닌가.. 싶네요
먼저 이 논문에서는 본인들이 제안하는 Network에 대해서 설명을 해줍니다. 기존 Resnet애눈 문제점이 있다는데요. 그건 한번의 resblock을 통과 할때마나 ReLU가 있어서 이는 정보를 너무 삭제할 가능성 있고 아예 ReLU를 안쓰는 것은 학습을 제어를 할 수 없기 때문에 아래 그림과 같이 모든 Resblock을 통과한다음 ReLU를 하도록 적용했다고 합니다.
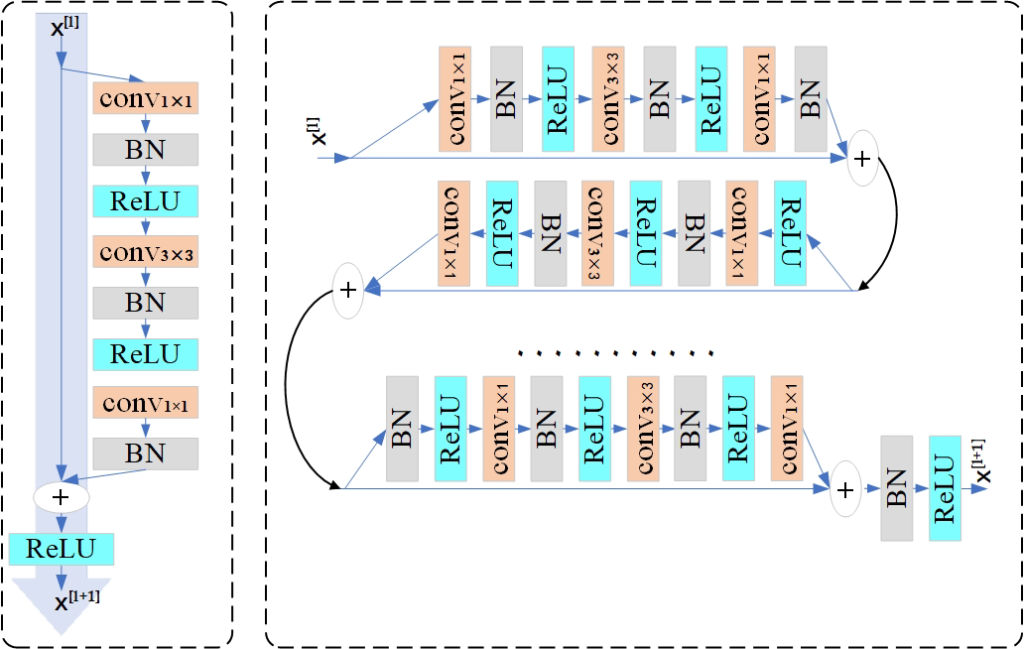
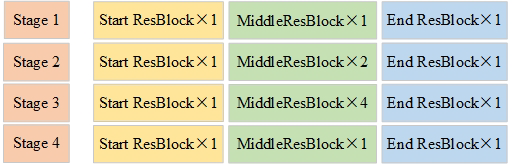
위에서 설명한 것을 전체 ResNet backbone에 대해서 아래그림과 함께 설명을 하자면, 기존에는 Start block 이던 Middle block 이던 상관없이 ReLU가 들어 갔었지만 이 논문에서는 End ResBlock에만 ReLU를 넣으므로써 손실 되는 정보를 줄였다고 합니다. 이때 아쉬운점은 이 논문에서 아래 그림이 ResNet과 다른 점이라는데 어떻게 다른지 설명이 없었어서 그게 쫌 아쉬운 것 같습니다. (설명도 무식하게 적어놓음)
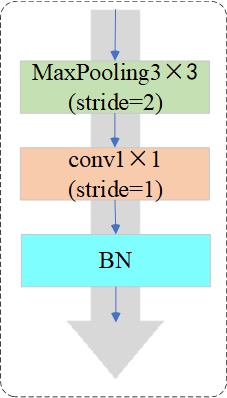
기존 ResNet에서 conv1x1을 이용해 차원을 맞춰서 다른 feature끼리 합치는 방식을 사용했는데 이렇게 단순히 conv1x1만을 사용할 경우 featuremap에서 75퍼 정도의 정보 손실이 일어난다고 합니다( 근거가 뭔지는 모르겠습니다) 이것을 막기 위해서 이 논문에서는 아래와 같이 maxpooling을 통해서 한번 feature 중 중요한 정보를 고르고 conv1x1을 거쳐서 정보손실을 최대한 막는 방식을 제안한다고 합니다
기존의 skipconnection은 단순히 feature 크기가 맞는 encoder와 decoder feature들 끼리 합쳤는데 이렇게 될 경우 가장 큰 feature의 경우 두 feature 들간의 의미가 크게 달라져있어서 학습에 어려움이 있을 수 있다고 합니다. 이를 막기위해 이논문에서는 아래와 같은 방식의 skipconnection을 제안합니다. 보면 아래 단계의 feature가 위의 단계에 계속 영향을 끼칠 수 있도록 설계한 것 같습니다.
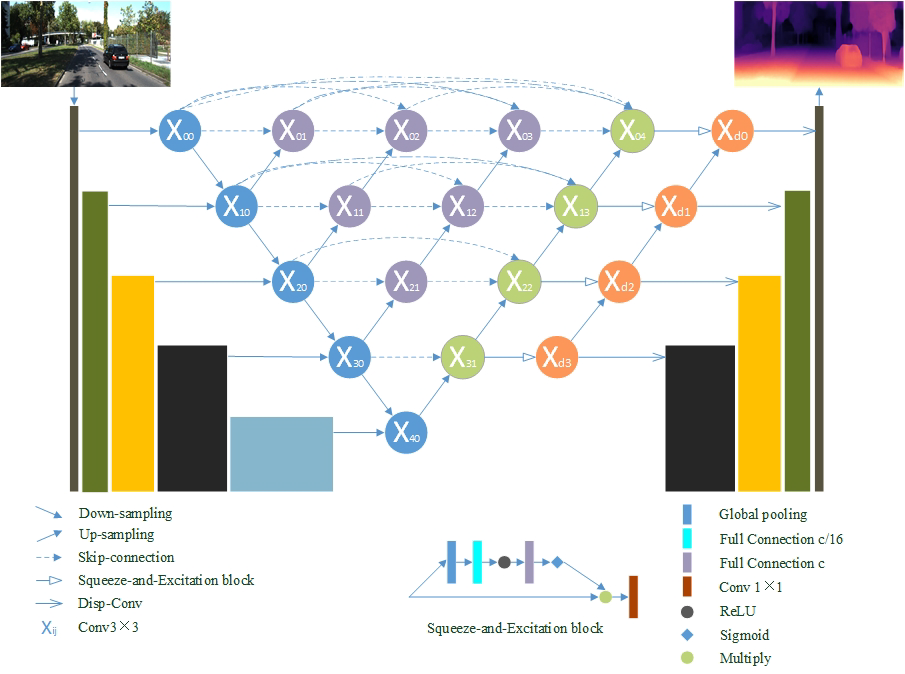
Loss에서 또한 추가적인 contribution이 있습니다.
첫번째로는 Featdepth의 loss가 single scale에서만 진행 되어 scale에 강인성이 떨어질 수 있으므로 Mutil scala에 적용했다는 것이고 다음으로는 기존 smoothness loss가 1차 미분으로 된 기울기 값을 사용하던 혹은 2차 미분을 사용하던 두가지가 제안되었는데 둘을 같이 사용하여 성능 향상을 보였다는 것입니다.
2. Result
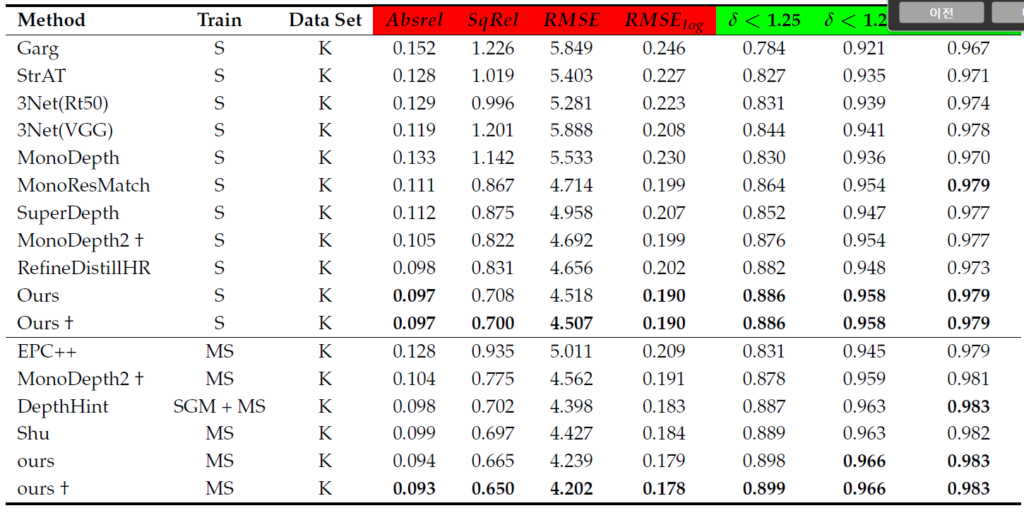
저기 저 Shu가 featdepth 인데,,,,, 도대체 왜…. MS도 할꺼면서 M에 대해서는 성능측정을 안했는지….featdepth 성능을 안넣었는지…. 마음에 들지 않네요… 딱 봐도 M에서 성능이 안나와서 S로만 간거 같은데… 크흠…
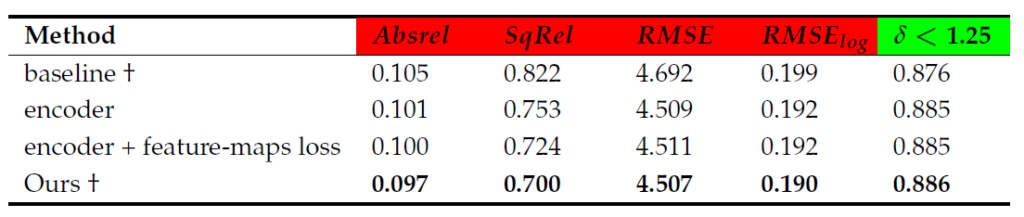
그렇다고 ablation study가 깔끔한 것도 아니고…. 저기 저 encoder가 뭐고 encoder+feature-maps loss와 Ours의 차이에 대해서 굉장히 불친절하게 설명이 되어 있어서, 어떤 부분이 어떻게 ours 의 성능을 향상 시켰는지가 알 수가 없는 부분입니다.
이 두개 외 에도 VKitti에서 성능 평가(Monodepth2 하고만 비교되있음 이데이터셋은 처음보는데 다른 논문에서는 안써서 그럴수도 있긴하거 같습니다.), Improved Kitti에서 성능 평가(비교논문들이 마음에 안듦 너무 예전 논문만 비교해놓은것 같은 느낌이 많이듭니다.), Make3D 에서 성능 평가(보통 정량적 평가하는데 정성적 평가만 있음), Cityscape에서 정성적평가(보통 Cityscape에서 정정적 평가를 안하고 pre train 시킨다음에 KITTI에서 평가를 하는데 이걸 해봤는데 성능이 안오라서 논문에 실지 않은건지… 왜 이렇게 평가를 했는지 모르겠습니다.) 등 실험은 많은데 실속이 없고 굉장히 Sensors에 대해서 의심만 커져가는 논문이였던 것 같습니다. 배울 점이… 없던 것 같네요 하하… 읽고 나서 후회… 했습니다.
Sensor에서 잘 도망쳐 나왔다…가 핵심이군요…!