첫 논문 리뷰를 작성하게 되었습니다. 해당 논문을 선택하게 된 이유로는 연구실에 들어오고 저희 팀에서 수행해야하는 연구들 중 가장 먼저 공부해보고 싶은 것으로 Image translation 을 선택하게 되었고, 처음 볼 논문으로 해당 논문을 추천받게 되었습니다.
Background
Conditional GAN (cGAN)

기존의 GAN 은 생성을 위한 입력으로 random noise 인 $z$ 입력으로 받았습니다. 하지만 이는 모델이 출력으로 무엇을 생성할지 제어할 수 없다는 단점이 있습니다. cGAN 은 $z$ 와 더불어 $y_fake$ 라는 condition을 함께 입력으로 받게되고 해당 condition에 맞는 출력을 생성합니다. 예를들어 MNIST 데이터에 대해서 GAN은 0~9 중 어떤 것을 생성할지 제어할 수 없었지만 cGAN은 이를 condition 으로 주어서 원하는 출력을 얻을 수 있습니다.
Introduction
Image translation 은 이전부터 제기되던 문제 중 하나였다고 합니다. 해당 문제의 다양한 task가 있었지만 결국 같은 일을 해야되는 것임에도 불구하고 task 마다 loss 를 각각 구성하는 등 새로운 세팅을 해주었다고 합니다. 또, 기존의 단순한 Euclidean distance 를 통한 loss 는 전체 outputs 의 평균을 최소화하는 방향으로 진행되기 때문에 결과를 blurr 하게 만드는 경향이 있다고 합니다. GAN 방법을 통해서 이 문제를 해결하게 되었는데, 이는 실제와 구별하기 힘든 결과를 만드는 한가지 목표를 갖게 되어 생성 모델이 실제 이미지와 오차가 적은 이미지를 생성함과 동시에 생성한 이미지가 실제인지 가짜인지 구별하도록 loss 를 학습하며 진행됩니다. blurry images 또한 실제와 같지 않기 때문에 가짜로 분류되고 이렇게 blurr 한 결과를 갖는 문제도 해결하게 됩니다. 여기에 cGAN 의 특정 condition 에 대한 결과를 생성하기 특징은 cGAN 이 Image-to-Image translation 에 적합하게 한다고 합니다.
이렇게 GAN 은 활발하게 연구되고 있고 해당 논문에서 연구하는 기술들도 이전에 제안된 것들이라고 합니다. 하지만 이전에는 적용에 초점을 두고 있었고 image-conditional GAN 이 Image-to-Image translation 에 얼마나 효과적일지는 불명확했다고 합니다. 해당 논문의 주된 contribution 은 두가지가 있다고 합니다.
- conditional GAN 이 다양한 문제에서 합리적인 결과를 도출해내는지를 설명하는 것
- 좋은 결과를 얻기에 충분한 간단한 프레임워크를 제시하고 몇 가지 중요한 구조적 요인을 분석하는 것
Method
objective
- z : random noise vector
- y : output image -> 아래 식에서는 GT…?
- x : observed image
- G : generator
- D : discriminator
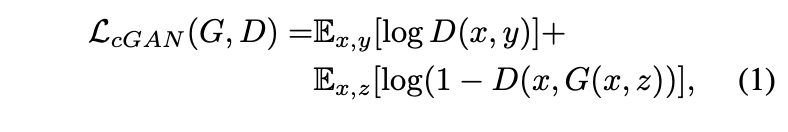
위 식은 cGAN 의 목적함수입니다. 여기서 D, G 의 입력으로 x가 함께 들어가게 되는데 이는 condition에 해당되는 정보이며 예를 들면 segmentation label -> RGB 에서는 segmentation label 에 해당되는 값입니다. G 가 목적 함수를 최소화 하려고 하고 동시에 적대적인 D는 목적 함수를 최대화 하려는 방향으로 학습된다고 합니다. 즉, $D(x, y)$ 는 실제 이미지를 정답으로 분류 해야되므로 1을 향해가며 전체적으로 목적함수를 최대화 시키고 $D(x, G(x, z))$ 에서 $G(x, z)$ 는 실제와 같은 이미지를 생성하려고 할 것 이고 이는 discriminator 를 속여 생성된 이미지를 진짜라고 믿게 만들어 $D(x, G(x, z))$ 가 1을 향하도록 해서 전체적으로 목적함수를 최소화 시킨다.
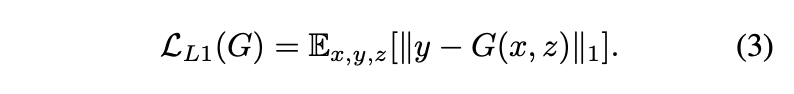
위 식은 생성된 데이터의 분포가 다른지를 계산하기 위한 식이고 이를 통해 generator는 discriminator 를 속이는 것 뿐만 아니라 GT와 가까운 이미지를 생성하여야 한다. L2 가 L1 보다 blurring이 더 심하기 때문에 L1 을 사용했다고 합니다.
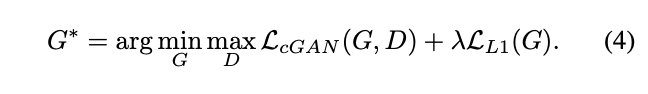
위 식은 최종 목적함수 입니다.
Network architecture
Generator with skips
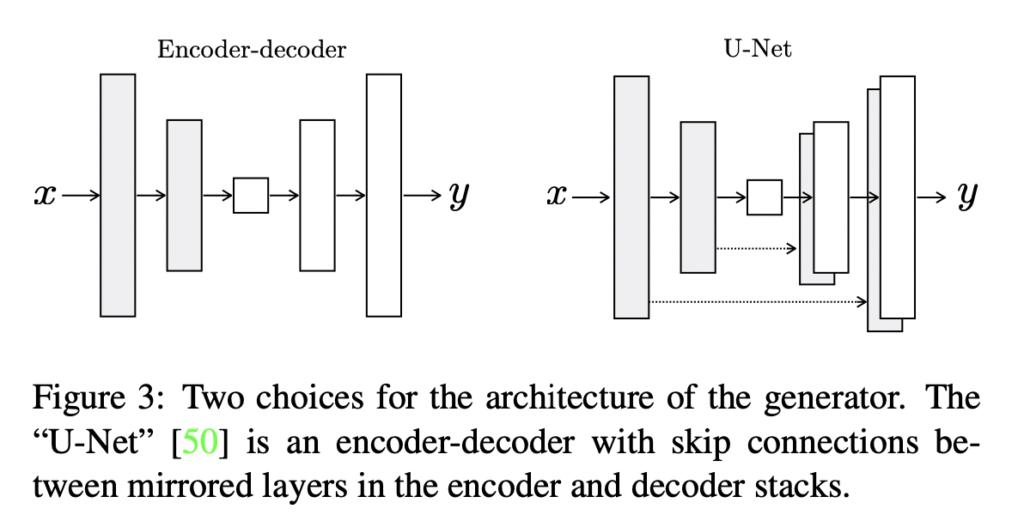
이전에는 왼쪽과 같은 기본적인 encoder-decoder 구조가 사용되었었다고 합니다. 하지만 이는 정보의 병목을 갖게됩니다. 많은 image translation 문제에서 input – output 사이의 정보는 공유될 수 있기 때문에 병목현상을 막기 위해 오른쪽과 같이 skip connection 을 통해 정보를 직접 전달하는 것은 효과적일 수 있다고 합니다. 정보가 공유될 수 있다는 것은 예를 들어 colorization 에서 input 과 output 은 대부분의 edge 를 공유합니다.
Markovian discriminator (PatchGAN)
$L_2$, $L_1$ Loss 는 blurr 한 이미지를 생성하게 만듭니다. 그렇기 때문에 좀 더 sharp 한 이미지를 얻기 위해 PatchGAN 이라는 discriminator 를 사용한다고 합니다. 이는 이미지의 real or fake 를 구분할 때 이미지 전체에 대해서 진행하는 것이 아니라 전체 이미지의 특정 사이즈인 patch 단위로 convolutional 하게 진행해서 그 평균을 이용한다고 합니다. 이렇게 해서 멀리 있는 픽셀과는 독립적으로 지역적 특징이 반영되어 더 sharp한 이미지를 얻을 수 있다고 합니다.
Limitation
서로 도메인이 다른 두 이미지 X, Y의 데이터를 한 쌍으로 묶어서 학습이 진행되어야 합니다. 이런 데이터를 얻기 쉬운 경우도 있지만 그렇지 못 한 경우가 많다고 합니다.
리뷰 잘 읽었습니다.
Image to Image Translation은 아무래도 새로운 도메인의 영상을 만드는 것이기에 정성적 결과가 상당히 중요합니다. 해당 리뷰에서는 정성적 정량적 결과들을 확인할 수 없어 조금 아쉽네요.
논문에서 GAN과 L1 loss를 사용할 때와 안할 때에 대한 결과 차이는 안보여주나요? 보여준다면 어떠한 차이가 발생하나요? 그리고 리뷰 내용 중 Patch Discriminator를 통해 저자는 fake/ real을 구분할 때 영상 전체가 아닌 patch를 본다고 하셨는데 저자가 사용한 패치 사이즈는 몇인가요? 패치 사이즈에 따른 결과 분석도 있을 것 같은데 패치 사이즈를 어떻게 하느냐에 따라 생성되는 결과가 어떻게 달라지나요?
질문 감사드립니다.
말씀 주신 것처럼 결과에 대한 이미지들을 첨부하고 싶었는데, 계속 용량이 초과한다고 첨부되지 않아서 못 한 부분이 있습니다. 방법을 찾아서 다음부터 첨부하도록 하겠습니다.
L1Loss 만 이용할 경우 blur 한 이미지를 얻게 되기 때문에 GAN이 사용됩니다. 이는 L1Loss가 high-frequency crispness 를 학습할 수 없어서라고 나와 있는데 이를 sharp한 이미지를 얻지 못 한다는 표현으로 이해했고, 그 이유는 전체를 평균한 값을 이용하기 떄문이라고 합니다. 그래서 high-frequency 를 얻기 위해 GAN을 사용합니다. 이때 GAN 은 L1Loss 가 low-frequency 를 얻어주기 떄문에 high-frequency 만을 위한 구조이고 이를 위해서 이미지 전체가 아니라 이미지를 패치단위로 확인하는 것이 좋다고 합니다. 그렇게 L1Loss 만 사용했을 경우 blur한 이미지를 얻게되고 GAN만 사용할 경우 훨씬 sharp한 이미지를 얻을 수 있었지만 일부 visual artifacts 가 포함되었고 이 둘을 같이 사용했을 때 가장 좋은 이미지가 얻어졌다고 합니다.
논문에서는 patch size 에 대해 (1 * 1), (16 * 16), (70 * 70), (286 * 286) size 의 patch 를 (256 * 256) 크기의 이미지를 통해 실험해보았습니다. 이떄 (1 * 1) colorfulness 는 얻을 수 있었으나 sharp함은 얻을 수 없었으며 (16 * 16) 은 어느 정도 sharp 함을 얻었지만 visual artifacts 가 발생했고, (70 * 70)에서 가장 좋은 성능을 얻었다고 합니다. (286 * 286) 일 때는 정성적 평가에서 큰 개선이 없는 것으로 확인 되었고, 정량적 평가에서도 좋지 못 한 결과를 얻었다고 하는데 이 이유로는 큰 patch size 는 많은 parameter를 가져서 학습하기 어렵기 때문이라고 하며 속도 또한 느리다는 단점이 있습니다. 저자는 이를 통해 (70 * 70) patch size 를 이용했다고 합니다.
아쉬웠던 부분을 말씀해주셔서 감사합니다. 답글을 달며 다음에 더 다루었으면 좋을 부분이 어떤 부분인지 느껴지는 것 같습니다. 해당 부분 개선해서 다음에는 더 디테일한 리뷰 작성하도록 하겠습니다.
답변 감사합니다.
참고로 캡처한 화면이 용량을 초과해서 담아지지 않을 경우에는 정성적 결과를 부분만 캡처하시거나 jpg로 저장 후 업로드하시면 대부분 해결됩니다.