이번 논문도 Transformer 관련 논문입니다. 요새 의도치않게 Transformer를 주제로 한 리뷰를 자주 쓰네요.
Abstract
사실 제목만 봐도 아시겠지만, 지난 주에 제가 리뷰한 Swin Transformer의 후속작입니다. 그래서 풀고자 하는 문제?가 매우 유사한데 요약하자면 이미지 도메인은 Text 도메인과 큰 차이점들이 존재합니다.(데이터 자체가 high resolution이라는 점, scale이라는 개념이 존재한다는 점 등)
하지만 기존에 제안된 ViT는 이러한 도메인의 차이를 고려하여 네트워크를 설계한 것이 아니라 한계가 존재하였고 Swin은 이러한 문제를 해결하고자 local attention과 Sifted window 방식을 통해 attention과 연산량의 trade-off 관계를 잘 조절하였습니다. 또한 Transformer block을 통과할 때마다 feature의 2배씩 줄임으로써 계층적 구조로 학습하여 scale의 특성을 잘 학습할 수 있도록 하였죠.
하지만 이러한 Swin 방식도 결국 연산량을 줄이기 위해 local attention을 하다보니, receptive field를 global attention을 할 수 있을정도로 키우기 위해서는 많은 block들을 쌓아야하는 단점이 존재했습니다. block을 계속 태워서 feature의 크기가 줄어들어야 global attention을 할 수 있기 때문이죠.
그래서 CSwin의 저자는 넓은 범위의 receptive field를 효율적으로 가지면서 동시에 연산량은 계속 줄일 수 있는 방법에 대해 고민했고 결국 CSwin을 제안하게 됩니다.
CSwin은 Cross-Shaped Window의 줄인말로 그림1의 a와 같이 연산하는 과정을 의미합니다.
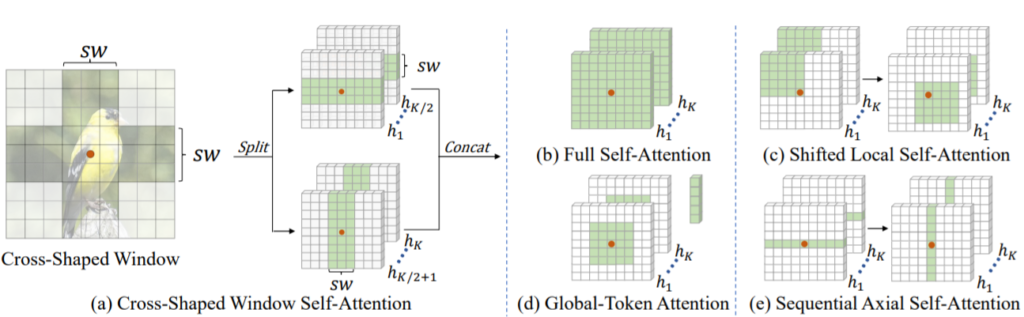
대충 그림1의 (b)는 기존 ViT의 self-attention 방식으로 global self-attention을 수행하기는 하지만, 전체를 다 계산하기 때문에 High Resolution 영상을 입력으로 하게 될 경우 제곱에 해당하는 연산량을 가지게 됩니다. (c)는 Swin을 나타내는 것처럼 보이고 (d)랑 (e)는 어떤 방법론인지는 모르겠으나 (e)같은 경우에는 CSwin과 제법 유사해보입니다.
또한 저자는 Locally-enhanced Positional Encoding(LePE) object detection과 segmentation과 같은 input varying downstream task에 매우 효과적인 positional encoding 방식도 제안합니다. 이 LePE는 기존 positional encoding 방식과는 다르게 각 transformer block에 위치 정보를 강요하는데 이는 attention 연산 과정 중이 아닌, attention 결과에 곧바로 적용됩니다.
아무튼 이러한 CSwin은 Swin과 동일하게 ImageNet, Object Detection, Segmentation에 대하여 성능을 보이고 있으며 이는 뒤에 실험 결과에서 리포팅하겠습니다.
Overall Architecture
CSwin의 전체 구조는 그림 2와 같습니다.
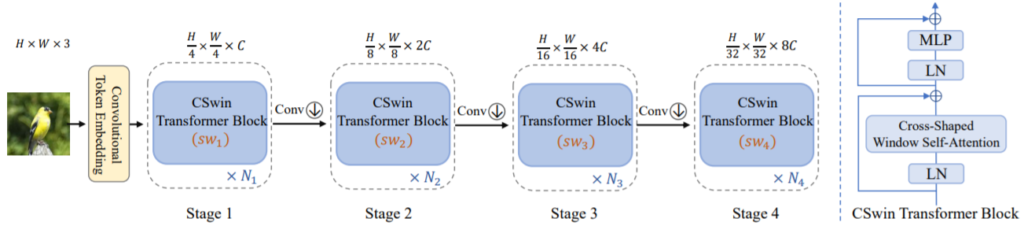
Swin과 유사하게 block은 4개로 구성되어 있으며 영상을 4×4 패치로 나누어 토큰으로 사용하기 때문에 첫 블럭에서는 입력 영상의 4배가 줄어드는 모습입니다. 또한 각 블럭을 지날때마다 Feature의 해상도가 2배씩 줄어드는 계층적 구조를 가지고 있으며 각 블록의 내부 구조는 그림2 우측과 같이 Layer Normalization –> CSwin –> Residual&LN –>MLP 형식으로 구성되어 있습니다.
여기서 Swin과 비교했을 때 한가지 바뀐 점은 각 Transformer block 사이에 컨볼루션 연산이 생겼다는 점인데, 기존에는 CNN으로 채널을 늘린 후 interpolation을 통하여 down sampling을 하였는데 CSwin의 경우 3×3 kernel, 2 stride를 가지는 CNN 연산을 통하여 채널과 down sampling을 동시에 수행한다는 점입니다.
Cross-Shaped Window Self-Attention
해당 내용은 뭐 결국 입력 영상이 커지면 기존의 self-attention 방식으로는 연산량이 너무 크게 늘어나게 되버리고, 이를 해결하고자 Swin과 같은 방법론들이 나왔지만 해당 방법론들 역시 Transformer block 개수를 global receptive field를 가질때까지 늘려야하는 바람에 연산량이 늘어나게 된다는 단점을 지적합니다. 그래서 이를 더 보완해서 만든게 CSwin이구요. 그럼 본격적으로 CSwin에 대해서 알아봅시다.
Horizontal and Vertical Stripes
먼저 CSwin의 multi-head self-attention 과정을 수식적으로 정의하는 것부터 시작하겠습니다. [(H * W), C] shape을 가지는입력 feature X는 제일 먼저 K개의 헤드로 linear projection 됩니다. 그리고 나서 local self-attention이 horizontal과 vertical stripe에 맞추어 진행되죠.
Horizontal stripes self-attention을 예시로 들면, X는 영역들이 겹치지 않도록 구역을 나누어 동일한 width sw를 가지는 horizontal stripe [X^{1}, ..., X^{M}] 들을 생성합니다. 즉 각각의 stripe은 sw \times W개의 토큰을 가지게 되는 것이죠. 여기서 sw는 stripe의 너비이기 때문에 해당 값에 따라서 학습 한도와 연산 복잡도를 조절할 수 있게 됩니다.
수식적으로 투영된 k번째 헤드의 query, key, value들은 모두 d_{k} 차원을 가지고 있으며 k^{th} 헤드에 대한 horizontal stripes self-attention의 출력값은 다음과 같이 정의됩니다.
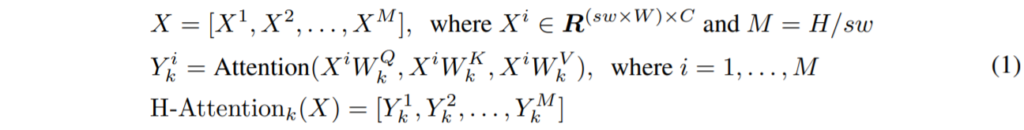
W^{Q}_{k}, W^{K}_{k}, W^{V}_{k}는 query, key, value space로 투영시키기 위한 투영 행렬이며 d_{k}는 feature의 채널에 헤드 개수 K를 나눈 값입니다.(C/K) 결과적으로 위와 유사하게 vertical stripes self-attention은 V-Attention_{k}(X)로 표현할 수 있습니다.
저자는 natural image들은 방향에 대한 bias가 없다고 가정하였기에, K개의 헤드를 2개의 그룹으로 동일하게 쪼갰습니다.(즉 K/2개로 헤드를 쪼갰으며 이때 K는 주로 짝수값을 가지게 됩니다.) 그 다음으로 첫번째 헤드 그룹은 horizontal stripes self-attention을 수행하며, 나머지 절반 그룹은 vertical stripes self-attention을 수행하게 됩니다. 마침내 두 병렬적인 그룹들의 결과는 concat 됩니다.

여기서 W^{O}는 self-attention 결과를 target output 차원으로 투영시키는 투영행렬로 이는 attention 결과가 마친 feature의 차원을 다시 default C로 변경하는 것이라고 보시면 됩니다.
이러한 CSwin의 Self-attention 동작 과정은 멀티 헤드를 여러 그룹으로 나누고 다른 self-attention 과정을 적용하게 됩니다. 즉 CSwin은 하나의 transformer block에서 각 토큰들의 attention 영역이 multi-head grouping을 통해 확대된 것을 의미합니다. 이와 대조적으로 기존의 attention 방법들은 서로 다른 멀티 헤드에 동일한 self-attention 기법이 적용되고 있죠. 저자는 이러한 기존 방식과 CSwin의 차이가 어떠한 성능 차이를 보이는지 뒤에 실험에서 보입니다.
Computation Complexity Analysis
CSwin의 self-attention 기법이 가지는 연산 복잡도는 아래 수식과 같습니다.
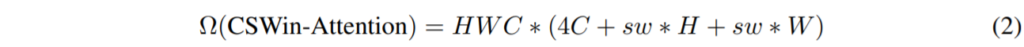
고해상도의 입력이 들어오게 될 경우, 초반 단계에서는 당연히 H,W가 C보다 더 클 것이고 뒷단으로 가면 갈수록 C가 H,W보다 더 커지는 상황에서 저자는 초반 단계에서는 작은 크기의 sw값을 가지고 뒷단에 갈수록 더 큰 sw를 가지는 방식을 적용하였습니다. 이러한 네트워크 위치에 따른 sw 값 조정은 뒷단에서 attention area를 유연하게 확장시킬 수 있어 block을 깊게 쌓지 않더라도 수월하게 large receptive field를 가질 수 있게 됩니다.
저자는 224 x 224 입력 영상이 들어왔다는 가정하에 sw 값을 각 단계별에 따라 1, 2, 7, 7로 설정하였다고 합니다.
Locally-Enhanced Positional Encoding
Self-attention은 permutation-invariant(무엇인지 잘 모르겠지만…)하기 때문에, 2D image에서 중요한 위치정보를 무시해버리곤 합니다. 대충 말하자면 각 패치 영역들에 대하여 score를 계산하기 때문에 CNN과 달리 특정 위치에 대한 정보들을 잘 습득하지 못하는 것이죠.
그래서 위치 정보를 추가해주기 위해, 다양한 positional encoding mechanism들이 기존 vision transformer에 적용되어왔습니다.

그림 3번을 살펴보시면 제일 왼쪽은 가장 일반적인 방식으로 Transformer block에 token을 넣기 전에 위치 정보를 추가해주는 방식입니다. NLP에서 가장 먼저 제안된 순혈? Transformer가 이 방식을 사용했었죠. 중간과 우측 방식은 모두 각 Transformer block 내부에서 위치 정보를 추가해주는 방식으로 각각 Swin과 CSwin에 해당합니다.
CSwin(그림3 우측)은 Softmax를 통한 attention calculation결과물에 위치 정보를 추가하는 Swin(그림3 중간)과 다르게 value 값에다가 바로 위치 정보를 추가해줌으로써 보다 직접적인 형식으로 위치 정보를 강조하였습니다.
value elements v_{i} and v_{j} 사이에 에지를 벡터 e^{V}_{ij}라고 한다면 Attention 연산 과정을 아래와 같이 표현할 수 있습니다.
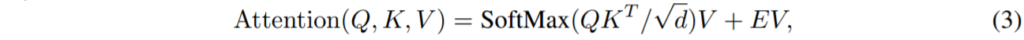
하지만 E에 대하여 모든 연결들을 고려해볼 때, 방대한 양의 연산량이 든다고 합니다. 이게 무슨 말인지 저도 정확히 이해는 못했지만 일단 저자가 연산량 증가를 줄이기 위해서 한 방식에 대해 바로 설명하겠습니다.
저자는 특정 입력 요소에 대하여 대부분의 중요한 위치 정보들은 그것의 주변 이웃으로부터 있을 것이라고 가정하였으며 이러한 가정을 바탕으로 locally-enhanced positional encoding(LePE)를 제안하게 됩니다. 이러한 LePE를 구현하는 방법은 Depth-wise convolution을 Value 값에다가 적용했다고 합니다.
결국에 위에서 제가 이해 못했던 E에 대한 모든 연결의 의미는 Value 값 전체에다가 일반적인 컨볼루션을 적용했을 때를 의미하는 것 같아 보이고 이게 연산량이 너무 크다보니 Depth-wise convolution 연산을 수행했다는 것으로 풀이됩니다.
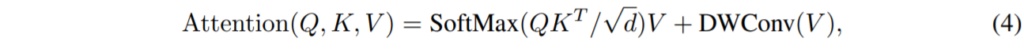
Architecture Variants
이제 뒤에 실험에 들어가기 앞서 CSwin 역시 Swin 때 처럼 임베딩 벡터의 채널 크기, 각 stage에 따른 block의 개수 각 단계에 따른 head의 개수 등 모델 학습에 필요한 파라미터에 따라 다음과 같이 모델 명칭을 지정하였습니다.

Experiments
실험은 위에서도 설명드렸다시피 ImageNet에서의 Classification, COCO dataset을 통한 Object Detection, ADE20K 데이터 셋을 통한 Segmentation으로 이루어집니다.
먼저 ImageNet-1K 분류에 대한 결과입니다.
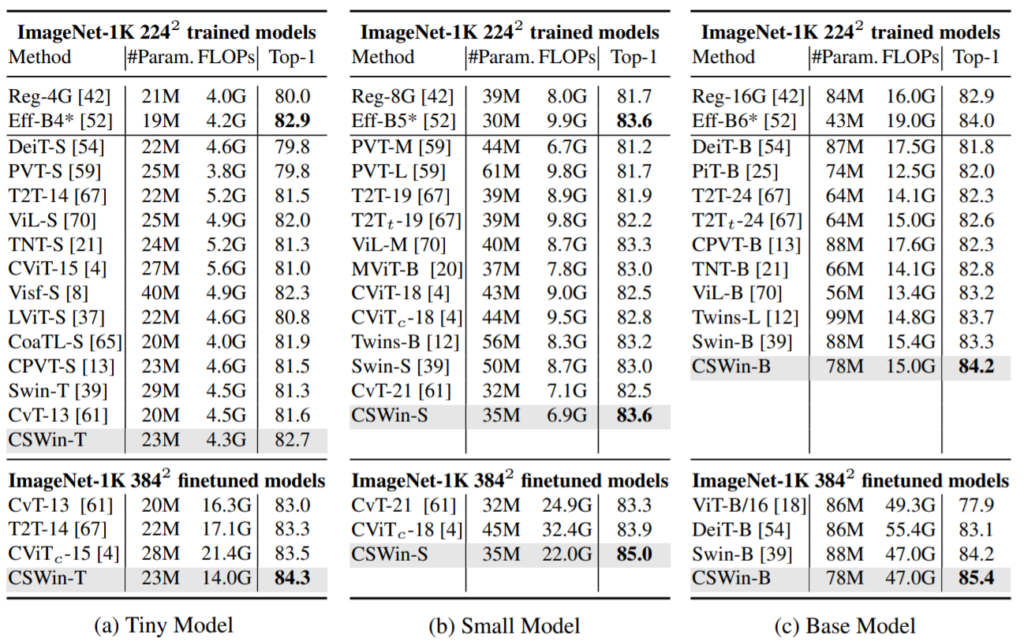
보시면 어떠한 모델 크기에 상관없이 CSwin이 타 방법론들 대비 우수한 성능을 보이고 있으며 특히 Tiny와 Small 모델에서 ImageNet 1K임에도 불구하고 Efficent B4랑 거의 유사한 성능을 보이고 있습니다. 물론 21K로 사전학습 후 1K로 finetuning한 결과에서는 EfficentNet B4보다 더 좋은 성능을 보이고 있구요.
그리고 다음은 Object Detection과 Segmentation 성능입니다.
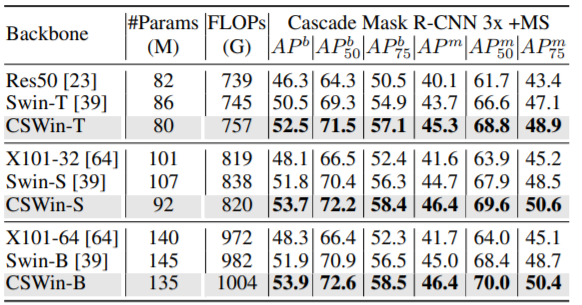
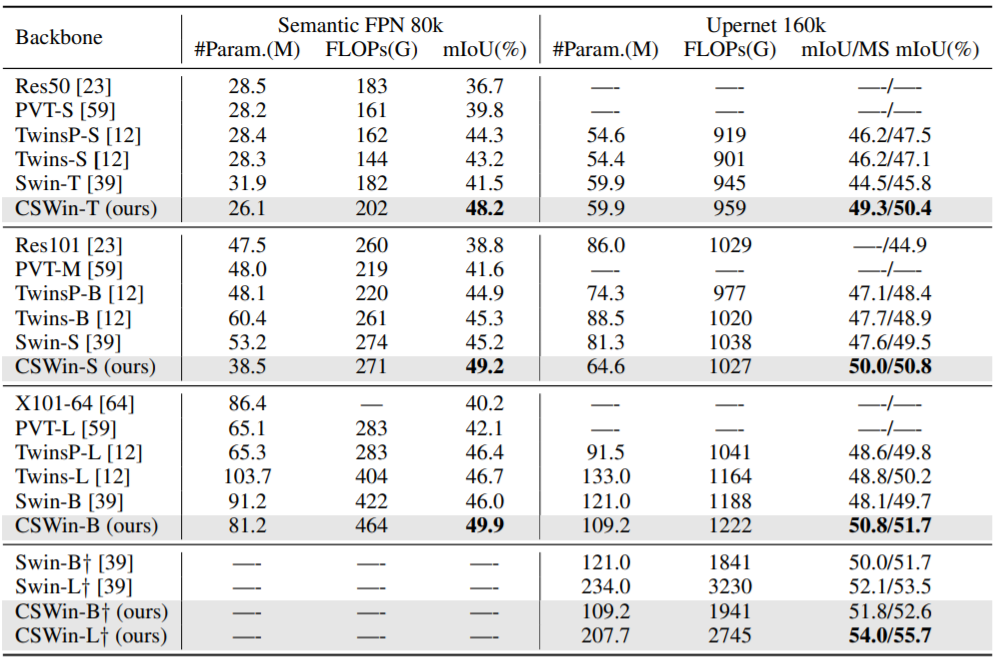
사실 타 방법론들과의 비교 실험보다는 ablation study부분이 더 중요하다고 생각해서 테이블만 보여주고 넘기겠습니다.
Ablation Study
저자는 자신들이 제안하는 Cross shaped window self-attention 방법들이 다른 방법론들(sliding window self-attention, shifted window self-attention, spatially separable self-attention, sequential axial self-attention)과 비교하여 얼마나 좋은지 비교 실험을 진행하였습니다. 또한 Positional encoding 방식도 적용하지 않을 때(No PE), transformer block을 태우기 전에 적용할 때(APE & CPE), Swin 방식(RPE)와 자신들의 방식(LePE)를 비교하는 실험도 진행하였습니다.
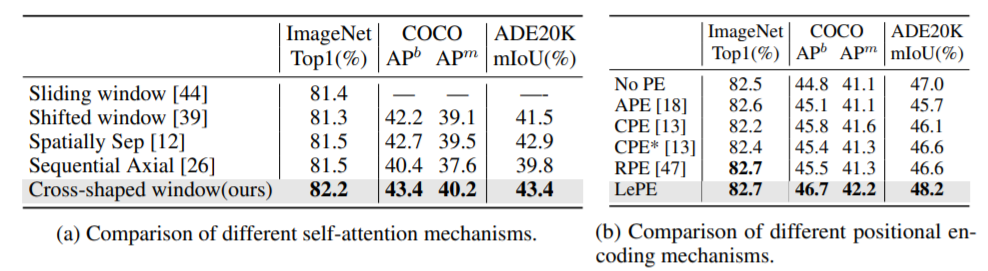
결과는 위와 같은데 가장 먼저 (a)를 살펴보시면 CSwin 방식이 Classification, Object Detection, Segmentation 모든 테스크에서 가장 좋은 성능을 보여주었습니다. 특히 Sequential Axial 방식과 Cross-shaped window 방식이 매우 유사하다고 볼 수 있는데, 저자는 Sequential axial 방식은 작은 stripe width(sw=1)로 설계된 방식으로 동작하기에 더 작은 attention area를 가지고 있으며 이는 downstream task를 수행하는데 있어 좋지 못하게 동작한다고 말합니다.
Positional encoding 비교 실험의 경우 요약을 하자면 1) Positional Encoding은 lcaol inductive bias를 제공함으로써 성능 향상에 기여해줄 수 있으며 2) RPE가 입력 해상도가 고정된 경우 분류 task에서 LePE와 동일한 성능을 거두었지만 LePE는 입력 해상도가 다양한 downstream task에서 더 좋은 성능을 보였다는 점이며 3) 결과적으로 LePE가 다른 PE방식들과 비교했을 때 가장 좋은 성능 향상을 보였다 입니다. (참고로 CPE*은 각각의 transformer block에다가 CPE를 적용한 것을 의미합니다. 기존 PE와 CPE는 맨 처음에 Transformer block 입력 전에 PE를 적용함)
결론
지난번 Swin 리뷰때도 살짝 언급하긴 했지만 Swin의 Shifted Window 방식은 살짝 애매한 감이 없지않아 있었는데 CSwin은 그나마 이해하기도 쉽고 직관적인 방식이라 좋았습니다. 하지만 또 CSwin보다 더 좋은 방법론을 가지고 Micro Soft에서 Transformer 논문을 쓰는 중일지도 모르겠네요…