먼저 해당 논문은 Artificial Intelligence Review라는 IF지수가 5점대 정도되는 저널에 2021에 출판된 버전입니다. 해당 논문이 처음나온건 2019년인거 같은데 최신 방법론들을 추가해서 2021년에 버전을 업데이트 한거 같네요.
해당 논문은 오랜만에 자세추정을 통한 grasping 논문으로 서베이논문 입니다. 이 논문을 가지고 온 이유는 올해 상반기쯔음에 pose estimation 관련 리뷰를 많이 했었는데, 뭔가 consistent 하지 않아서 조각나있는 파편들을 모아 한번 정리해보고 싶어서 읽게 되었습니다. 추석 맞이하여 잠시 메인연구와 큰 관련없는 논문을 읽고 쉬어가는?… 타임을 갖고자 해당논문을 선정하였습니다. 간만에 자세추정 논문을 읽으니 상당히 재밌네요. 한분야만 파다가 지칠때 쉬어가기 좋은거 같습니다. 다만 쉬어간다고 하기엔 내용이 40페이지 정도로 좀 많긴하네요…ㅋㅋ
개인적으로 정리하는 느낌에서 해당 논문은 매우 좋은 서베이 논문이라고 생각합니다. 먼저 짧게 요약한 후 디테일한 설명을 좀 해보고, 맨뒤에서 다시 마무리로 요약하는식으로 리뷰를 작성해보겠습니다.
논문
먼저 해당 논문은 vision기반으로 grasping하는 task에 대한 전반적인 review 페이퍼입니다. 크게 object localization, pose estimation, grasp estimation으로 구성되고, 각각의 메인스트림에 대한 설명과 방법론들에 대한 소개로 구성되어있습니다.
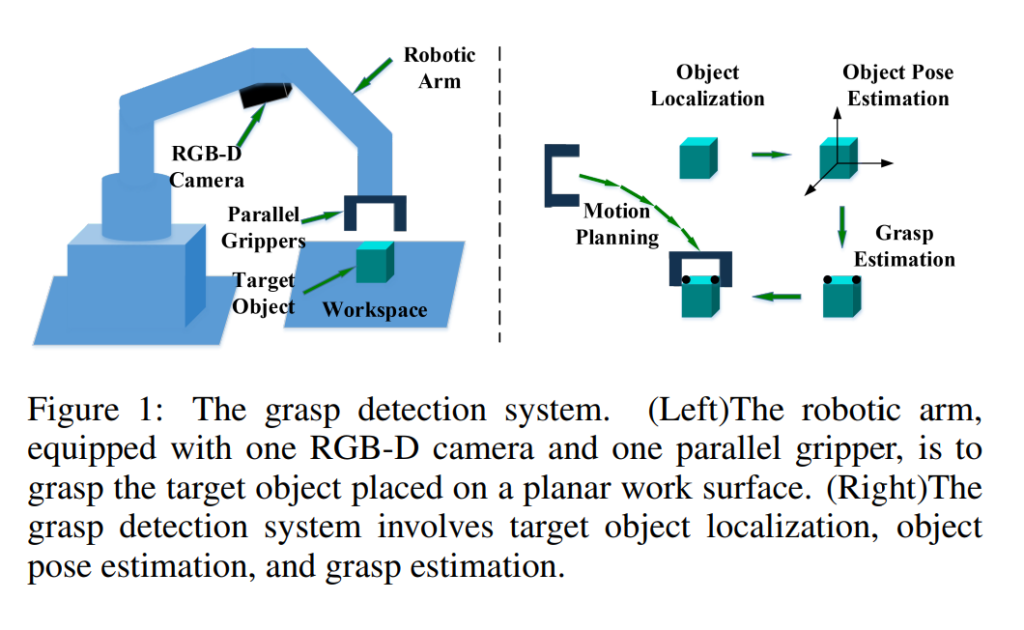
위의 그림을 보시면 직관적으로 어떠한 테스크인지 이해가 쉬운데요. Pose Estimatimation(자세추정)이 쓰이는 분야중에 하나인 grasping(집는거)에 대해서 주로 다루고있습니다. 로봇에게 grasping이라 하면 workspace상에 있는 로봇의 위치를 파악하고, 해당 물체가 어떠한 자세로 있는지를 파악한 후, robotic arm을 움직여서 end-effector를 이용하여 물체를 집어올리는 행위를 말합니다. 위의 그림처럼 RGB-D 카메라를 이용하는 경우가 가장 흔하구요. 경우에 따라서는 RGB만을 사용할 수도 있습니다. 아직까지 multispectral을 사용하는건 못본거 같네요.
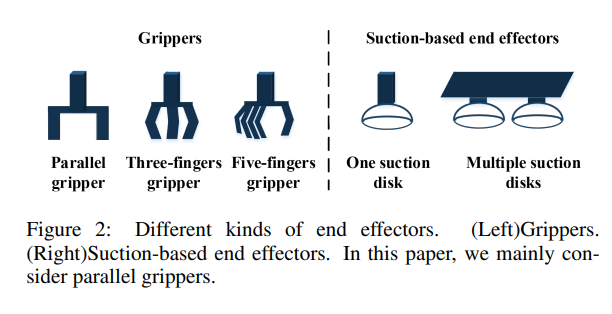
End-effector 로는 위의 그림처럼 다양한 종류의 grippers를 사용할 수 있는데요. 크게 suction based와 아닌 경우로 나뉘게 됩니다. 그리고 해당 논문에서는 suction based는 too easy task 이므로 생략하고 있습니다. 사실 suction based가 더 좋은 경우도 있지만, suction만으로는 grasping을 하기에는 무리인 경우도 많으며, 저희같은 컴비전 쟁이들에게는 좀 더 진보된 grasping을 가능하게 해주는 end-effector들의 활용이 좀 더 가치가 있다고 생각합니다.

Pose Estimation은 주로 RGB만을 사용하거나 RGB-D 를 사용하는데 RGB-D처럼 depth정보가 있으면 위 그림처럼 포인트클라우드로 representation 할수도 있겠지요.
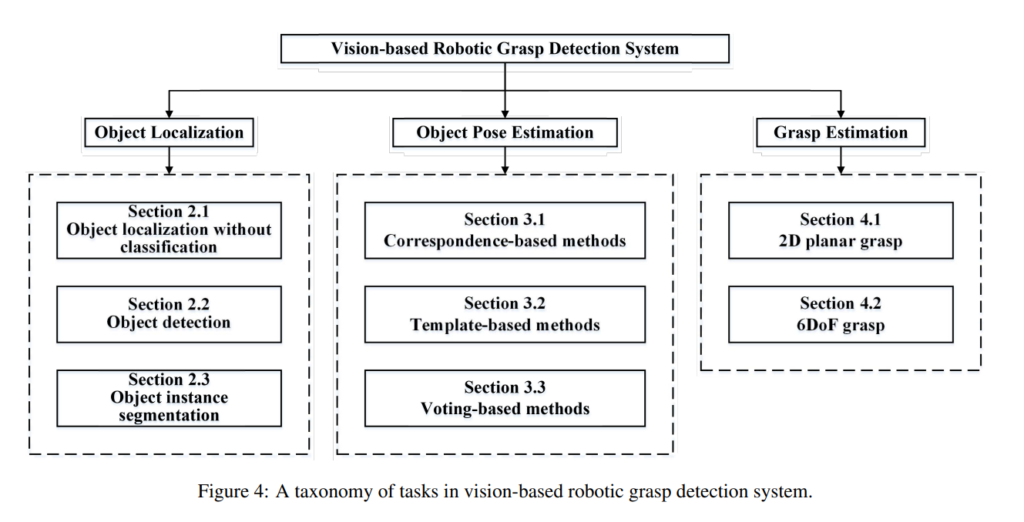
수 많은 자세제어 방법론들을 저자는 위와같이 분류하였습니다. 그리고 각각의 section별로 해당 내용을 설명합니다. 개인적으로 이런식으로 구별해둔게 마음에 들었는데 제가 주로 했던 리뷰들은 6DoF Pose Estimation 이었는데, 6DoF 자세추정 방법론이 grasping을 하는데 어떠한 방법들과 같이 쓰이는지 알 수 있어서 좋았습니다. 뭔가 굉장히 직관적이네요. 그럼 저 위에 많은 세분화된 섹션들을 하나씩 차근차근 살펴봅시다.
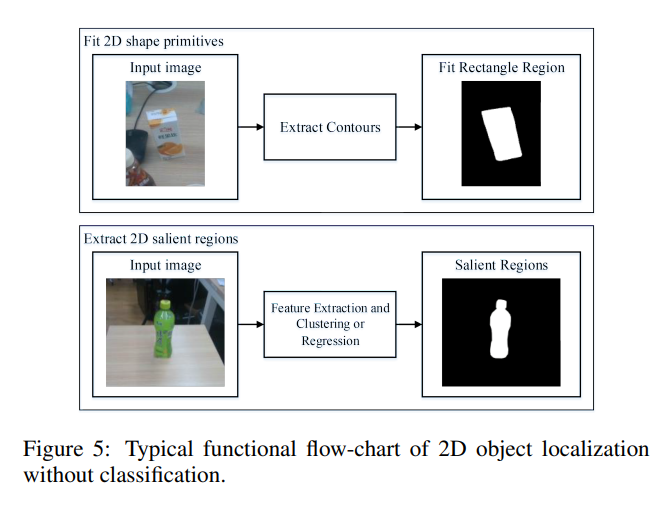
먼저 2D object localization without classification 입니다. Grasping을 하기위해서는 workspace상에서 물체의 위치를 파악하는 것이 중요한데, 그 방법론중에서 가장 나이브하게 물체에 대한 class 카테고리 없이 물체의 위치만을 파악하는게 바로 위의 그림과 같은 방법입니다. 위에는 primitives라고 불리는 shape를 fitting하는 방법이며 아래는 피쳐를 뽑아내고 클러스터링이나 회귀를 하여 salient region을 얻어내는 방법입니다. 차이점이라고 한다면 primitives를 얻는 방법은 rectangle, triangle 처럼 무언가 정해진 shape가 어느정도 있지만, salient region의 경우에는 segmentation과 유사하게 물체의 shape에 대한 제약이 좀 더 적습니다. 그런데 실제로 grasping을 할때 물체는 3D workspace상에 있을텐데 2D로 localization을 한다는게 이상하다고 생각하지 않으시나요? 아래에서 설명을 이어가겠습니다.
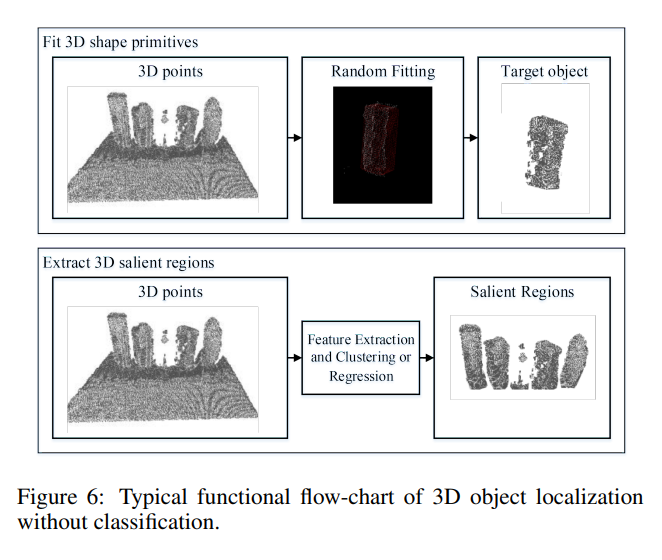
위에서 말했듯이, workspace상의 물체는 3D 이고 물체의 위치를 파악하려면 3D 상에서의 위치를 파악하는게 맞습니다. 그러나, 무언가 x, y ,z 축중에 한개가 고정되면 2D가 될 것이고, 이러한 경우에는 2D문제로 바뀌게 됩니다. 예를들어 물체를 평평한 workspace상에 있는 물체를 parallel하게 grasping하는 경우에는 z축에 대한 rotation및 translation을 고려하지 않아도 되게 됩니다. 이런식으로 constraint가 생기면 차원이 줄어들 수 있습니다. 하지만, 일반적으로는 위에서와 같이 3D에 대한 localization이 필요하고, 그중에서도 object category에 대한 고려없이 localization만 하는 경우에는 2D경우와 마찬가지로 primitives를 이용하는 방법과 salient region을 얻는 방법으로 나뉘게 됩니다. 자세한 설명은 위에서 설명한 2D와 같으므로 생략하겠습니다.

위에서 설명했던건 object의 category에 대한 고려없이 localization만 한 경우였는데 거기에 category에 대한 classification을 같이하면 우리가 잘 알고있는 object detection이 됩니다. 위에서 설명한 Localization과 마찬가지로 2D와 3D로 나뉘게 되는데, 사실 2D Object Detection은 워낙에 유명하고 익숙한 주제이기 때문에 자세한 설명이 필요할까 싶어서 넘어가겠습니다.
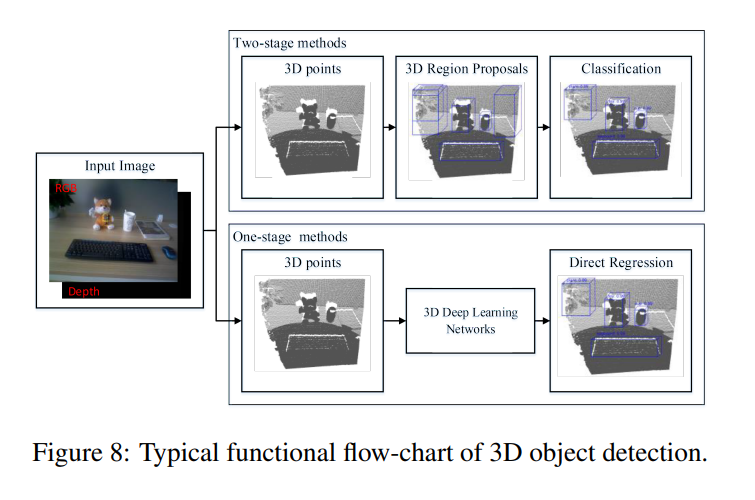
2D와는 다르게 3D object detection은 좀 더 고려해야할 사항들이 많이 있습니다. 일단 2D처럼 Two-stage 와 one-stage로 나뉘며, 메인 컨셉은 상당히 유사합니다. 2D에서의 RPN과는 다르게 3D region proposal은 좀 더 복잡한데, 저자는 크게 Frustum-based 방법과 global regression 방법, local regression 방법으로 나뉜다고 소개하네요.
제가 해당분야를 잘 아는 것은 아니지만, 일단 2D가 많이 익숙해지면 3D로 넘어가고자 하는 의향이 있는데요. 해당 서베이 논문을 읽고 이해한 내용을 바탕으로 각각 설명드리겠습니다.
먼저 Frustum-based 방식은 상당히 straight forward 한데요. 이미 성능이 잘 나오는 2D detector의 도움을 받아서 2D detector로 높은 confidence를 가지는 2D region proposal들을 받아다가 그 주변의 point clouds정보와 같이 사용하는 것 입니다.
그리고 global regression방법과 local regression 방법은 유사한데, local은 point-wise라는 점이 좀 다릅니다. feature representation 및 regression을 통해 region proposal을 얻어내는게 핵심 컨셉이며, 2D RPN과 비슷하다는 느낌을 받았습니다.
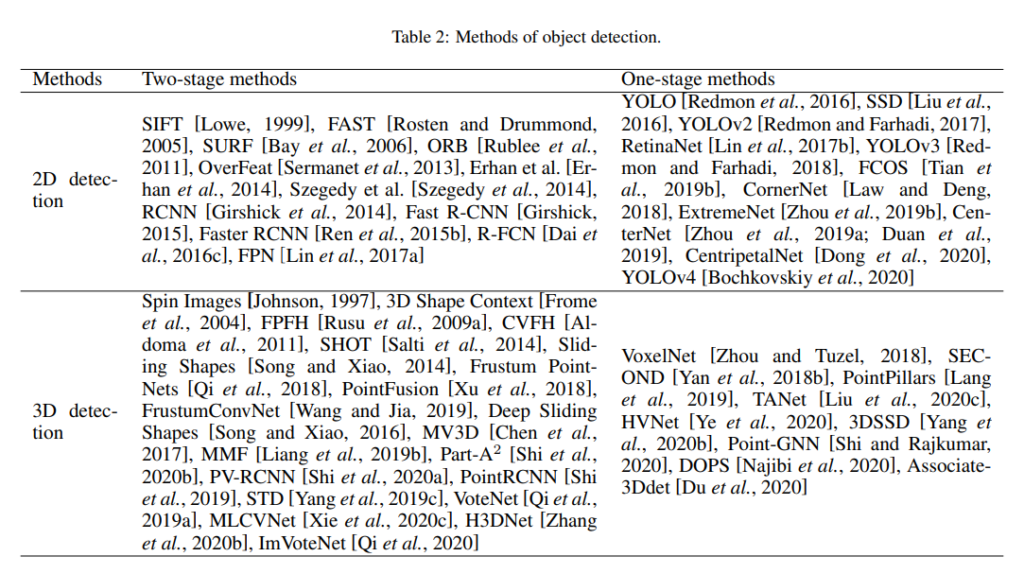
그래서 corresponding하는 방법론들에는 위에 표처럼 있습니다. 익숙한 방법론들이 많은 분들이 연구원님들중에 있을거라해서 표를 가지고 와봤습니다. 서베이내용에서 엄청나게 방대한 내용을 다루는거 치고, 방법론에 대한 설명들이 짧고 보기 좋게 잘 정리되어있는데 특히 3D Object detection쪽은 읽어보시는걸 추천드립니다. 리뷰에서 다 다루기에는 내용이 너무 많아서 무리라고 생각하여 제외하였습니다. (현재 내용이 약 이제 8페이지 정도까지네요…)

위에 Discussion은 중요한 결론이라고 생각해서 가지고 왔습니다. 결국에 3D object detection을 하는것 만으로는 grasping을 할 수 없다는것이 핵심입니다.
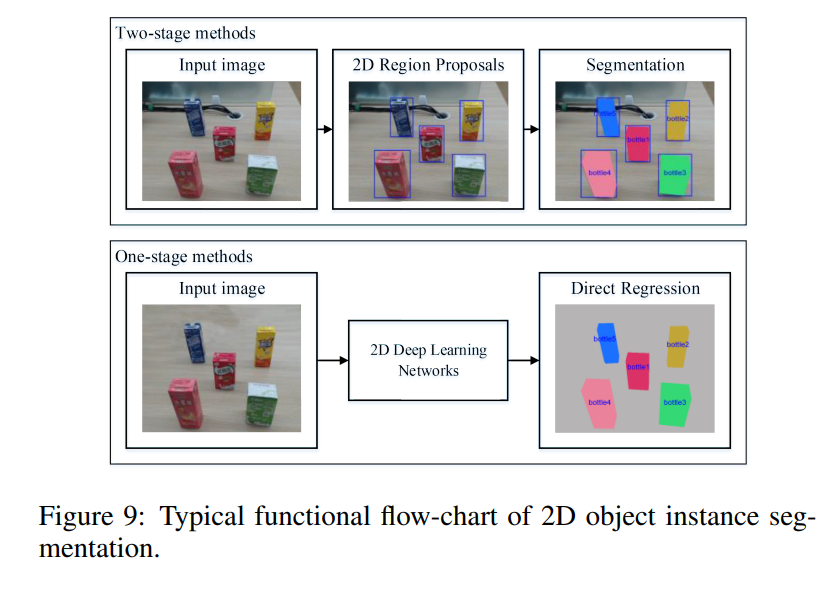
Object Detection과 마찬가지로 Segmentation도 grasping을 할 때, useful information을 줄 수 있다는 관점에서 사용될 수 있습니다. 뭐 bbox보다 좀 더 정교한 정보를 주는 것 이니깐요. OD와 매우 유사하게 One-stage와 Two-stage로 나뉘며 pixel-level로 classification을 한다는 점에서 OD와는 차이점이 있습니다.
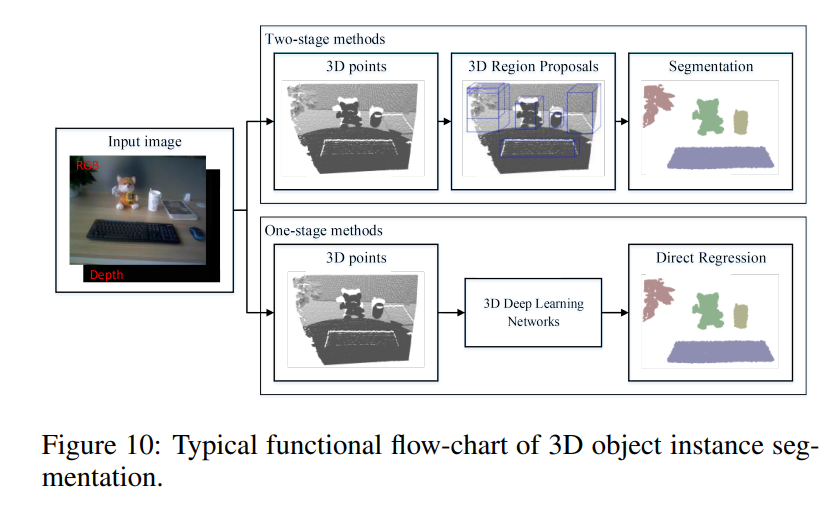
3D segmetation은 개인적으로 좀 낯설었는데, 저자의 말에 의하면 현재 grasping task에서 아직까지도 target object의 3D point cloud를 얻기위해 2D segmentation이 좀 더 흔하게 쓰이고 있다고 합니다. 그래도 3D segmentation을 이용한 방법도 최근 빠르게 발전하는 추세라고 하네요. 근데 또 생각해보면 제가 올해 초에 읽었던 sota에 가까운 pose estimation 논문들에서는 거의 3D segmentation을 활용했던거 같네요.
이전까지 언급했던 내용들은 workspace상의 물체의 위치 및 라벨정보를 얻기위한 localization, object detection, segmentation 이었습니다. 이번에는 본격적인 grasping을 하기전에 물체의 자세를 추정하는 방법에 대해서 알아보겠습니다.
자세추정
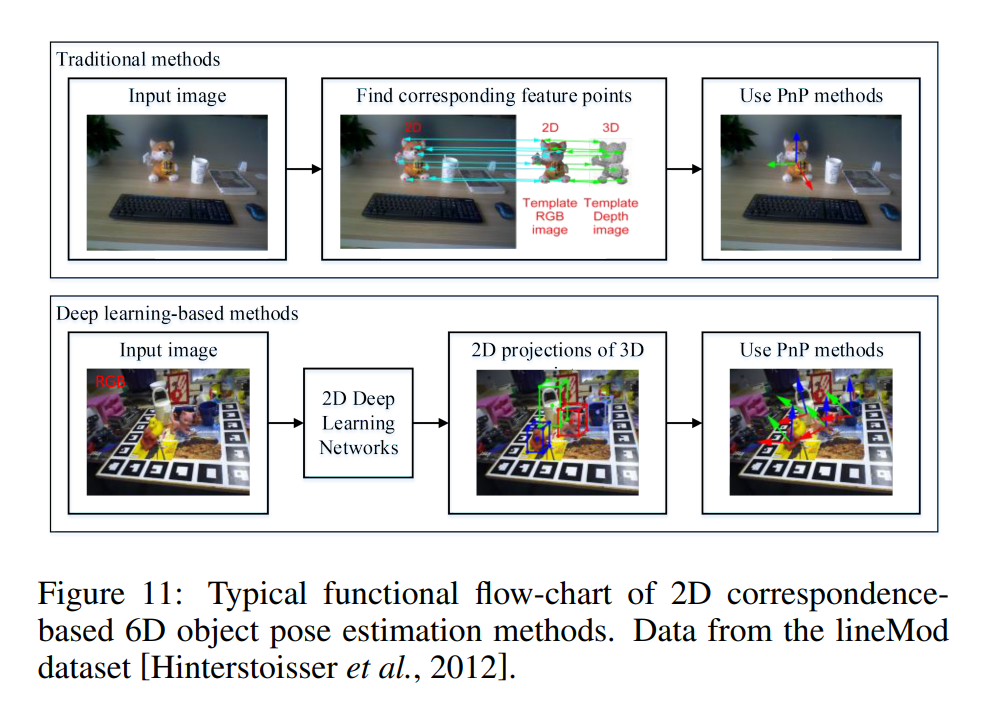
자세추정에는 크게 Traditional methods 와 Deep Learning-based methods로 나뉩니다. 개인적으로 저자가 분류해둔 방식들이 굉장히 마음에드네요. 보기편하고 알기 쉽게 정리를 잘해두었습니다.
그리고 Traditional methods와 Deep Learning-based 중에서도 correspondence-based, template-based, voting-based로 나뉘게 되는데요.
먼저 correspondence-based는 2D나 3D GT모델과 sensed input인 RGB이미지와의 correspondence를 기준으로 매칭을 한 후 PnP알고리즘을 이용하여 pose를 구하는 것 입니다. 이때, GT 모델은 rendering을 통해 다양한 각도와 시점으로 projection되어 사용됩니다.
PnP알고리즘은 카메라의 포즈를 구할 때 사용하는 것과 같은데요. 매칭점을 여러개 찾은 뒤 카메라의 포즈를 구했던 것 처럼 3D GT모델과 2D이미지 사이의 매칭점을 찾으면 해당 object의 포즈를 구할 수 있게됩니다. 이 때, GT 모델을 template이라고도 표현하는데 template-based method는 이와 약간 다른 방법론인데 헷갈리지 않으셨으면 합니다. 뒤에서 설명하겠습니다.
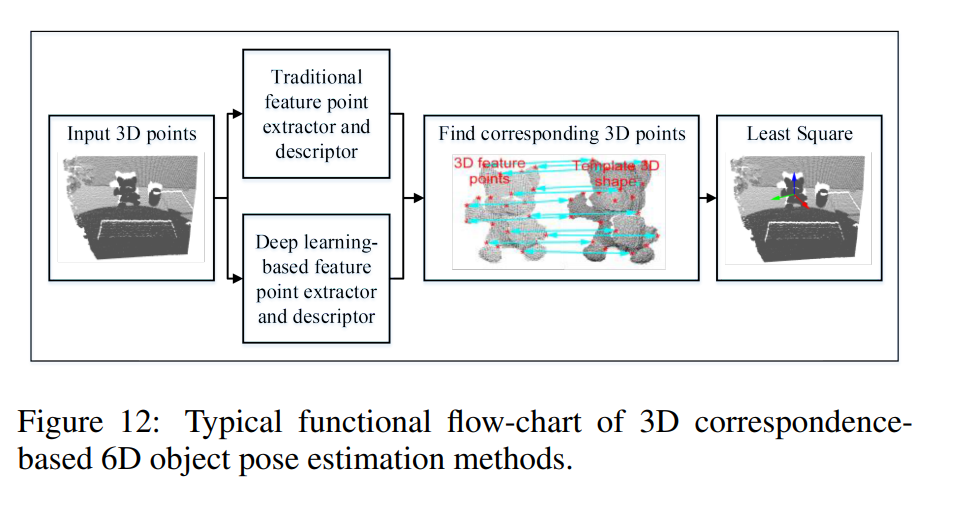
3D point cloud-based methods에서는 인풋이 3D cloud point가 사용이 되구요, 각종 feature representation을 하는 방식을 사용하여 local feature descriptor들을 추출한 후 해당 descriptor와 corresponding 하는 3D point를 찾은 후 Least Square방법을 사용하여 자세를 복원할 수 있습니다.
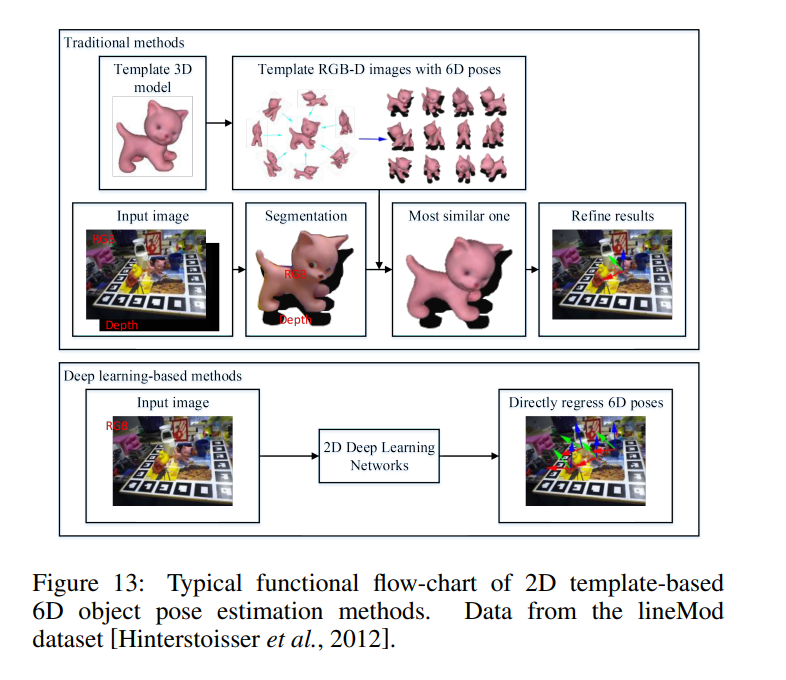
다음으로는 Template-based methods입니다. 위의 그림처럼 3D modeling된 정보를 다양하게 rotation 시키면서 rendering 한 후 해당 rendering 된 정보들을 template으로 사용합니다. 그리고 input image가 들어오면 pixel이나 point level로 3D segmentation 한 후 해당 segmentation 정보중에서 template들 중 가장 비슷한 template을 선정합니다. 그리고 그 template을 기준으로 refine을 진행합니다.
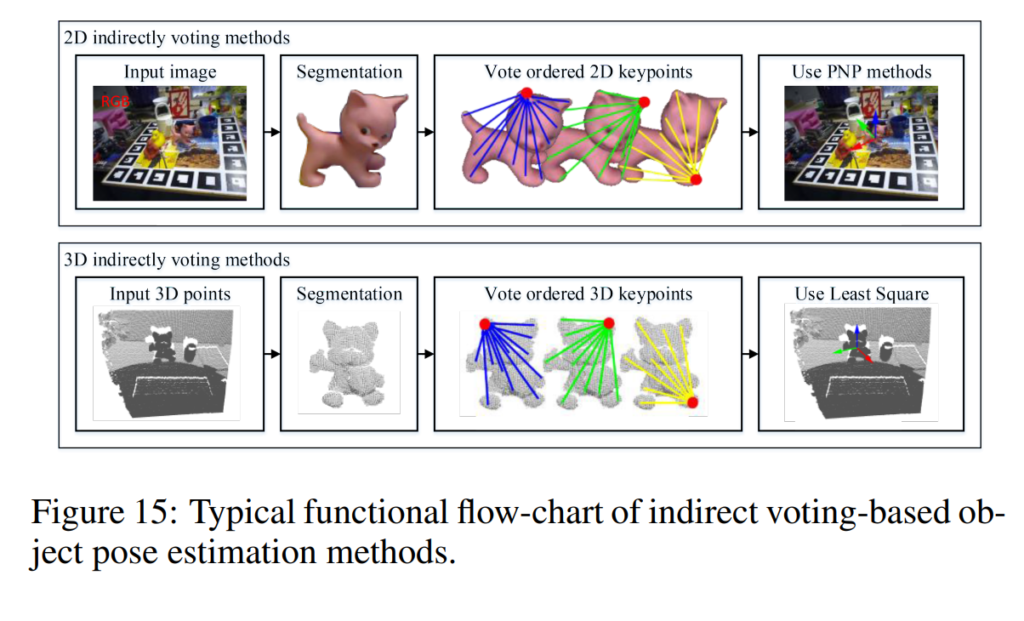
마지막으로 voting based 자세추정은 최근 논문들에서 핫하게 사용되는 방법인데요. PixelNet과 그 후속논문들에 대한 논문을 제가 리뷰한적이 있습니다. 더 궁금하신 분들은 제 리뷰를 참고해주시고요. 컨셉은 말그대로 voting인데 이 voting을 어떤식으로 하느냐… Hough voting이라고 불리는 방법을 사용합니다.
먼저 input image로 부터 Segmenation을 진행을 하고요. 그 뒤에 keypoint에 대해서 voting을 진행을 하는데요. 이때 여기서 말하는 keypoint는 hyperparameter로 일반적으로 object의 surface에 있는 8개의 점을 사용합니다. 좀 오래된 방법론에서는 3D bbox위의 점을 keypoint로 사용하는 경우도 있지만 아무래도 object의 surface위의 pixel을 keypoint로 사용하는게 성능이 더 좋습니다. 해당 keypoint는 furthest point를 구해나가는 알고리즘을 통해 구하게되고요. 아무튼 이러한 keypoint를 설정을 한 후 각각의 픽셀마다 해당 keypoint의 방향벡터에 대한 정보를 regression 합니다. 그리고 그 방향벡터들로 벡터장을 형성한 후, 벡터장의 교점을 voting하는 식으로해서 occlusion이나 truncation에 좀 더 강인한 자세 추정을 가능하게 합니다.
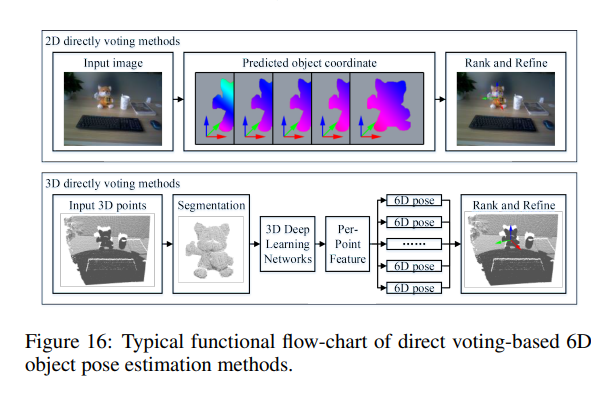
앞서 설명한 voting method는 indirect하게 keypoint를 voting한 후 PnP나 least square 방법을 사용하여 포즈를 구했다면, 이번에는 direct하게 pose를 구하는 방법입니다. 음… 쉽게 설명하자면 위에서 설명한 template-based 방법론과 비슷한데요. template-based는 template들 중에서 한개를 찾는 식이 었지만 direct-voting 방법은 template중에서 찾는 것을 voting식으로 풀어나간 것 입니다.
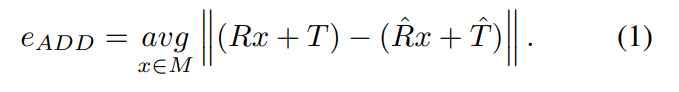
자세추정에서 metric은 주로 위의 수식처럼 GT Pose와 predicted pose를 그냥 빼고 절대값 씌우는 방식인 ADD가 사용이 되구요, 대칭인 오브젝트에 대해서는 ADD-S가 사용이 됩니다. 이또한 제가 리뷰에서 여러번 언급했으므로 생략하겠습니다. x-review찾아보시면 나올겁니다! 그리고 이러한 distance metric의 값이 object의 지름의 10%보다 낮게 나오면 올바르게 예측한것으로 처리하여 성능을 평가합니다.
그리고 데이터셋은 YCB Video와 Linemod 가 가장 많이 사용됩니다.
이번 리뷰에서 correspondence-based // template-based // voting-based 등의 방법을 통한 자세추정에 대해서 이야기 해보았는데 그럼 각각의 방법론에는 어떠한 장단점이 있을까요?
그에대한 답변을 해주는 부분이 아래에 있는데 너무너무 중요한 문장인거 같아서 원문으로 가지고 왔습니다.
Generally, when the target object has rich texture or geometric details, the correspondence-based method is a good choice. When the target object has weak texture or geometric detail, the template-based method is a good choice. When the object is occluded and only partial surface is visible, or the addressed object ranges from specific objects to category-level objects, the voting-based method is a good choice. Besides, the three kinds of methods all have 2D inputs, 3D inputs or mixed inputs.
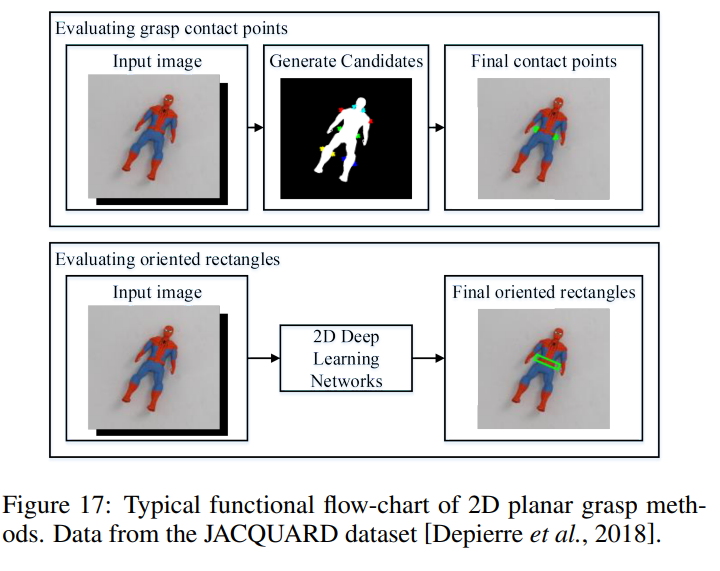
다음으로는 grasp point를 구하는 방법인데요. grasp estimation이라고도 불리는데 메니퓰레이터를 이용해서 어떠한 부분을 grasp해야하는지 구하는 방법을 의미합니다. 위의 경우엔 스파이더맨의 허리가 grasp 하기 가장 좋은 지점이라고 나오네요. 해당 스파이더맨은 2D planar상에 존재하고, z축을 기준으로 rotation만이 존재하므로 2개의 translation 과 1개의 rotation만으로 grasp point를 정할 수 있습니다. 즉 grasp point는 x, y 좌표와 z축 rotation theta로 총 3개의 값이 되고 해당 값을 모델을 통해서 구합니다.
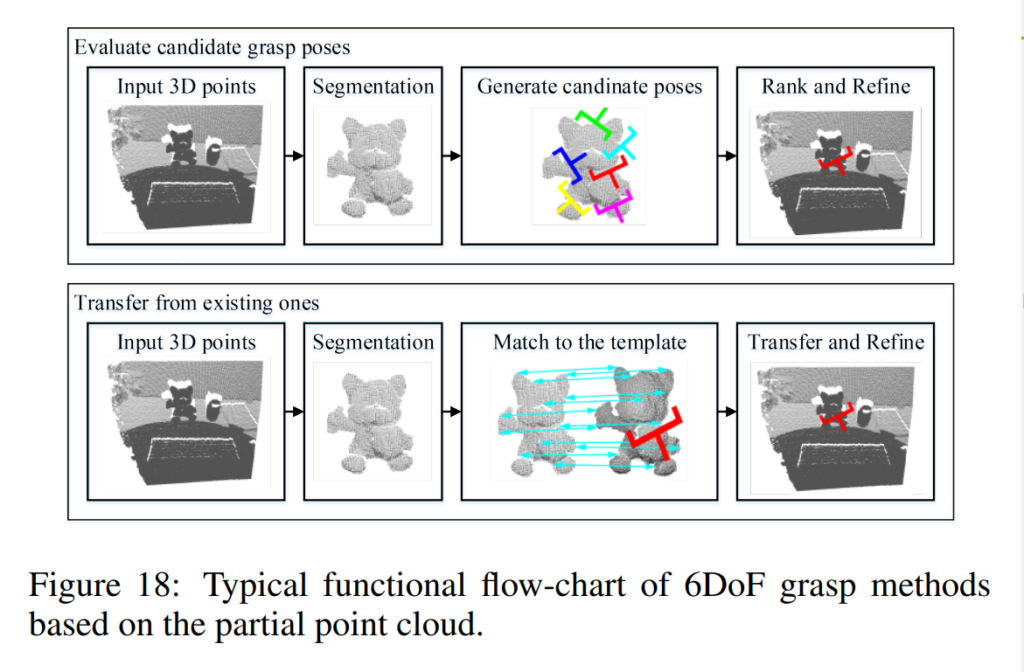
위에서와 다르게 3D point를 grasp하는 과정은 좀 더 복잡한데요. Template과 매칭한 후 가장 좋은 grasp를 택하는 방식으로 grasp point를 classification하기도 합니다.

다음 방법은 위의 그림처럼 Segmentation과 이후 shape를 완성한 후에 estimation을 하는 방법입니다. 이렇게하면 그냥 estimation을 하는 것보다 더 좋은 성능을 낸다고 합니다. 이제 길고긴 리뷰의 끝이 멀지 않았네요…
디스커션
위에서 grasping을 위한 방법론들의 핵심 컨셉들을 빠르게 짚고 넘어갔는데요. 그럼 현재 존재하는 방법론들의 한계와 챌린징한 요소들은 무엇이있을까요? 우선 3D 모델과 target 모델의 불일치성 입니다. LINEMOD와 YCB VIDEO처럼 유명한 데이터셋에서는 완벽한 3D CAD모델을 제공하지만, 실제로그렇지 않은 데이터셋도 많이 존재합니다. 특히나 TARGET의 shape가 변하는 경우에는 그 정도가 더 심하게됩니다. 그래서 현재 존재하는 자세추정 방법론은 대부분 추정하려는 물체가 강체인 경우에 좋은 성능을 내지만 그렇지 않고 deformation이 존재하는경우에는 성능저하가 심하게 유발합니다.
또다른 문제점으로는 segmentation에 의존적이란 점 입니다. 대부분의 자세추정 알고리즘은 segmentation을 선행하고 시작하므로 segmentation의 성능에 의존적이게 됩니다. 그러나 class category가 많아질수록 segmentation task의 난이도는 올라가게되고 이렇게되면 자연스럽게 자세추정 정확도도 떨어지게 됩니다.
다른 문제점으로는 cluttered scene에서 occlusion이 발생하는 경우에 grasp point를 정확하게 예측하기 매우 힘들다는 것 입니다. 최근 연구들에서는 이러한 cluttered scene에서의 grasping만을 다루는 논문들도 많이 나오고 있습니다. 참고로 cluttered scene이라고 하면 workspace가 messy한것과 동일한 의미라고생각하시면 됩니다.
마지막 문제점은 항상 정면방향으로 물체를 촬영하고 있기 때문에 반대방향에서의 촬영정보가 없다는 것 입니다. 아무래도 정면에 보이는 정보만으로 자세를 추정하려고하니 성능을 저하시키는 요소가 됩니다.
이렇게 서베이 페이퍼를 리뷰해보았는데 개인적으로 읽어본 논문들이 정리가 잘 안되는 기분이었는데 해당 서베이페이퍼를 읽고 많이 정리가 된 느낌을 받았습니다. 아무래도 work의 flow를 파악하는데 정말 많은 도움이 되었던거 같습니다. 긴 페이퍼였지만 읽은보람이 있네요. 그리고 개인적으로 재밌기도 했고요. 아무래도 수식이 없고 연구동향의 흐름에 대해서 설명을 하는 페이퍼였기 때문에 그렇지 않았나 싶습니다. 맨위에 제가 최근에 제가 하는 연구와 좀 동떨어져있는 논문을 리뷰한다고 하였는데 사실 지금와서 생각해보면 제가하고싶은 연구는 grasping쪽에 가까운거 같고 grasping을 하려면 어찌됐든 object detection도 필요하니 그다지 동떨어있는 연구는 아닌거 같기도 하네요. 이상 TMI였구요. 리뷰 마치겠습니다.