저번주에 이어 이번주에도 Face Landmark Localization 에 대한 논문을 가져왔습니다. 그 중 3D Face landmark localization에 대한 논문입니다.
Face Landmark Localization 연구는 추후 Face 3D Reconstruction (3D 얼굴 복원), Facial Expression Recognition (얼굴 표정 인식) 등 다양한 분야에 접목되곤 합니다. 리뷰 시작에 앞서 해당 분야에 대해 먼저 간단하게 설명을 드리도록 하겠습니다.
Face Landmark Localization 연구는 크게 2D와 3D 두 가지 방법으로 진행이 됩니다. 2D Face Landmark Localization 은 아래 예시처럼 2D 얼굴 이미지에서의 얼굴의 특징점(Landmarks, eg. 눈, 코, 입, 턱선 등)의 위치를 찾는 것입니다.

그리고 제가 이번에 리뷰할 논문에서는 3D Landmark의 위치를 어떻게 구하는지에 대해 설명합니다. 그렇다면 3D Face Landmark Localization이란, 아래 예시와 같이 2D Face Image만으로 얼굴의 특징점(Landmark)을 찾아 3D 상의 좌표로 얼굴의 상대적인 깊이까지 3차원의 좌표로 나타내는 것입니다.

그렇다면 그동안 어떤 방식으로 해당 연구가 진행이 되었을까요? 정말 가볍게 어떤식으로 연구가 진행되고 있는지에 대해 설명드리겠습니다.
먼저 2D Face Alignment 라고도 하는 2D Face Landmark Localization 연구는 초기 shape-index feature를 landmark의 좌표들과 매핑시키는 Regression 기반의 방법론이 주를 이루었다고 합니다. 다시 말해, 해당 얼굴의 특징 벡터를 landmark 좌표와 매핑시킨다고 생각하면 좋을 것 같습니다. 그러다 각 랜드마크가 있을 위치의 likelihood를 나타내는 heatmap 추정하는 방법론이 등장하였습니다. (참고로 pose estimation 에서 흔히 사용되는 이 heatmap에서 영감을 얻어 face 관련 태스크에도 heatmap 이 자주 사용됩니다.) 이 방법은 feature 공간에서 랜드마크 위치로 매핑 시 non-linear 한 비효율적인 학습을 피할 수 있다는 장점이 있습니다.
초기 3D Face Landmark Localization 은 두 가지 단계로 구성되었습니다. 먼저, 앞서 설명한 2D Face Landamrk Localization 방식으로 2D Landmark 를 추출 후, depth 추정 혹은 3D Modeling 을 통해 3D face landmark 를 얻습니다. 이 방법은 아무래도 2D Landmark 추출에 전적으로 의존할 수 밖에 없다는 치명적인 단점이 존재합니다. 따라서 이를 극복하고자 2D heatmap 이 아닌 3D heatmap 을 추출하자니, 랜드마크 수에 비례한 메모리 부담이 생긴다는 단점이 있습니다.
따라서 본 논문은 기존 3D 방법론의 복잡함을 개선하고자 the Joint Voxel and Coordinate Regression (JVCR) 을 제안합니다.
Contribution
- compact volumetric representation
위치의 복셀 단위 likelihood 를 3D 공간의 랜드마크로 인코딩하는 compact volumetric representation 제안 - coarse-to-fine strategy to regress the volumetric representation
랜드마크 간의 3D 구조적 제약 조건을 신경망에 의해 보다 효율적으로 학습할 수 있도록 볼륨 표현을 regress 하는 전략 사용 - the proposed joint voxel and coordinate regression framework enables end-to-end training
기존 방식( [1] 2D Landmark 추출 후, [2] 이를 바탕으로 3D 로 확장)과 달리 end-to-end 학습이 가능
Joint Voxel and Coordinate Regression for Accurate 3D Facial Landmark Localization – [ 바로가기 ]

Pipeline of the Joint Voxel and Coordinate Regression (JVCR) method
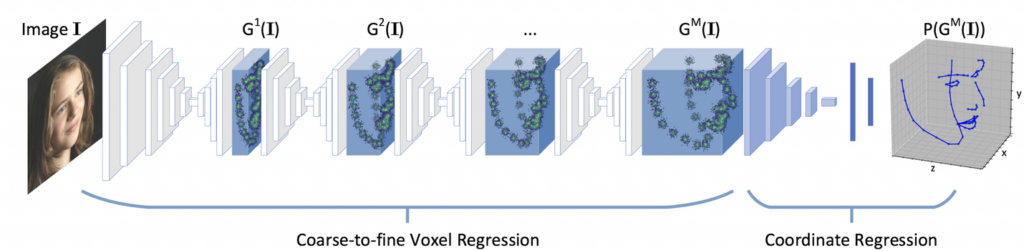
본 논문의 메인 파이프라인입니다. 해당 논문의 방법론은 크게 두 개의 main blocks 으로 구성이 됩니다.
- Coarse-to-Fine Voxel Regression
- Corrdinate Regression (3D Convolution Network )
Coarse-to-Fine 방식의 Cascaded regression는 2D 랜드마크 로컬라이제이션에 광범위하게 사용되곤 합니다. 왜냐하면 이 Cascaded Regression 을 사용하면 Regression을 충분히 사용할 수 있어, output을 점차 개선할 수 있기 때문입니다. 따라서 이 방식을 3D 에 접목시키고자 위에서 언급한 두 가지 단계로 나누었다고 합니다.
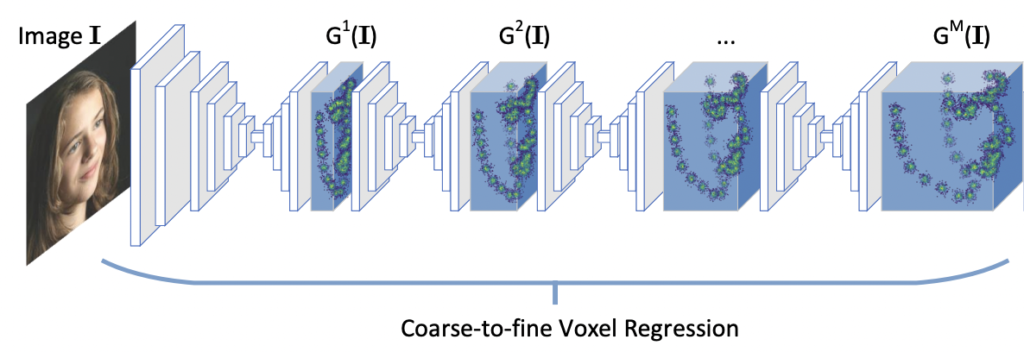
1) Coarse-to-Fine Voxel Regression
첫번째 단계인 Coarse-to-Fine Voxel Regression 에서는 3D 랜드마크의 이상적인 volumetric representation ( 편의상 입체 표현이라 칭하겠습니다 ) 을 Coarse-to-Fine 한 방식으로 Regression 시키는 것을 목표로 합니다. 직역하니 무슨 소리인지 전혀 감이 안오실 수도 있는데.. 아래 그림처럼 얼굴 이미지 I 를 4개의 backbone 네트워크에 순차적으로 태워가며 다소 coarse(거친/조잡한) 한 3차원 표현을 점차 fine(미세한) 3차원 표현으로 랜드마크의 위치를 regression 시키는 것을 목표로 하는 단계입니다. 즉, 얼굴 이미지만으로 4개의 hourglass 모델을 통해 입체적인 랜드마크의 위치를 regress하는 단계입니다.
Voxel Regression Subnetwork G는 얼굴 이미지 I의 픽셀에서 volumetric 표현 V: G(I) → V로의 매핑을 학습합니다. 여기서 G^m 는 m번째 Hourglass 모듈에 의해 출력되는 볼륨이며 Loss 함수는 아래와 같습니다.
(여기서 backbone을 hourglass 모델로 삼은 이유는 바로 pose estimation 에서 이 방법을 따온 것이기 때문입니다. hourglass는 pose estimation (동작 예측)에서 흔히 사용되는 네트워크로 작아졌다 커졌다 하는 것이 모래시계 같아 만들어진 이름으로 생각하면 이해가 쉬울 것 같네요.)
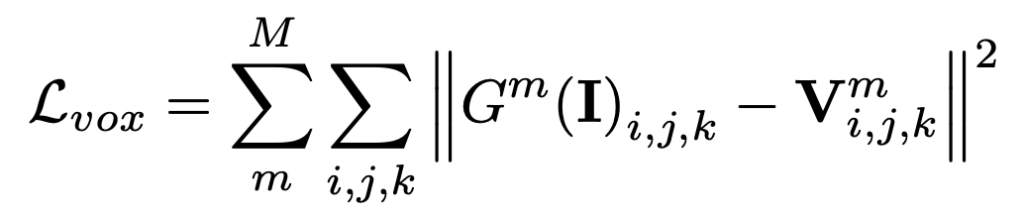
2 Coordinate Regression
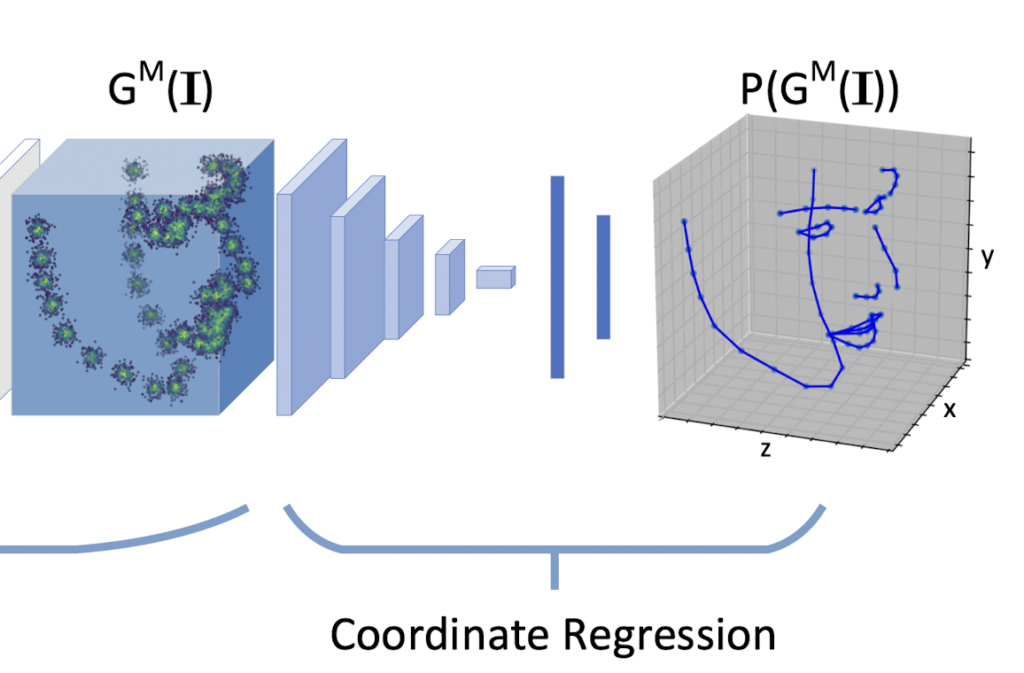
두번째 단계는 1단계에서 구한 모든 랜드마크의 입체 표현을 다시 실제 랜드마크의 좌표를 회귀시켜야합니다. 3D 표현의 복잡도를 줄이기 위해 compact volumn representation 으로 랜드마크의 입체 정보를 표현했기 때문에, 이를 다시 좌표화 시켜주는 과정이라고 생각하면 좋을 것 같습니다.
일반적인 Heatmap Regression 기반 방법은 해당 heatmap의 peak point에서 직접 랜드마크의 좌표를 찾습니다. 모든 랜드마크의 위치가 하나의 볼륨으로 인코딩된다는 점을 고려할 때, 랜드마크 순서가 compact volumetric representation으로 보존되지 않아 기존의 “tacking-maximum” 작업은 더 이상 적용되지 않습니다. 따라서 해당 volumetric representation으로에서 랜드마크의 좌표를 유추해야 합니다.
이를 위해, compact volumetric representation V에서 해당 좌표 벡터 x: P(V) → x로의 매핑을 학습하기 위한 Coordinate Regression Subnetwork P를 제안합니다. 3D object recognition 그리고 hand pose estimation에 대한 연구에서 영감을 받아, 좌표 회귀에서 2D 컨볼루션 대신 3D 컨볼루션 커널을 채택하였다고 합니다. (3D 컨볼루션은 보통 비디오 분석 문제의 공간 및 시간 차원 모두에서 형상을 추출하는 데 사용됩니다.) 그렇기 때문에 입체 표현에서 3D 정보를 추출하기 위해 3D 컨볼루션을 선택하는게 자연스러웠다고 하네요… 학습을 위해서는 예측 좌표 벡터에 L2 regression loss 를 사용하였습니다.
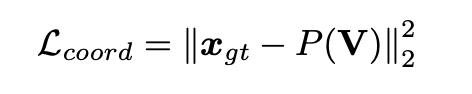
3 Training
전체 네트워크를 처음부터 훈련하는 대신, 더 안정적이고 효과적인 성능 보장을 위해 2단계로 나누어 학습합니다. 위에서 언급한 두 개의 subnetwork는 각각 사전에 별도로 pre-train 되고 마지막으로 통합된 네트워크로 fine-tuning 됩니다.
특히, pre-train 단계에서 Voxel Regression Regression SubNetwork는 얼굴 이미지와 실제 Volumne으로 학습됩니다. 한편, Corrdinate Regression SubNetwork는 GT 와 해당 좌표 벡터로 학습됩니다.
Fine-Tuning 단계에서 Voxel Regression Regression SubNetwork는 Corrdinate Regression SubNetwork에 연결되고, 전체 네트워크는 GT 및 좌표 벡터로 fine-tuning 됩니다. 따라서 최종 Loss 는 아래 수식과 같습니다.
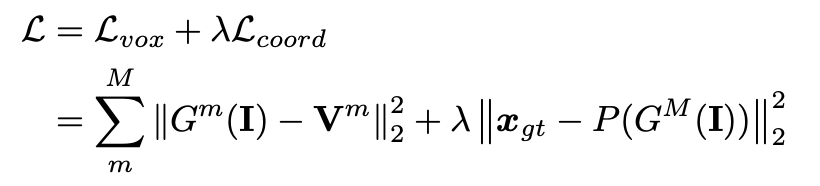
Experiments
implementation detail (제가 참고하려고 정리해둔 것입니다)
- input size : 256 × 256
- output : volumetric representation & the coordinate vector
- four Hourglass modules are stacked together as the voxel regression
- output volumes size : (64 × 64 × d) . . . d of z-dimension is chosen from the set {1, 2, 4, 64}
- data augmentation : applied randomly (eg. rotation, scaling and fliping)
- 25 epochs in total : 15 epochs for the pre-training + 10 epochs for the fine-tuning
- optimizer : RMSprop
- initial learning rate : 2.5×10−4 & reduced by a factor of 10 every 10 epochs
- During testing, it takes about 50ms in TITAN Xp GPU
Evaluation Metrics
평가 지표는 이전 연구와 동일합니다. 특히 3D landmark localization의 경우, 3DFAW 챌린지에서 권장하는 평가지표인 Ground Truth Error (GTE) 와 Cross View Ground Truth Consistency Error (CVGTCE) 를 사용하였습니다.
- GTE : 눈의 바깥 끝점 사이의 거리에 의해 정규화된 점대점 유클리디언 에러의 평균
- CVGTCE : 3DFAW 챌린지에서 제안되며 예측된 랜드마크의 크로스 뷰 일관성을 평가하는 것을 목표합니다. 따라서 수식은 정규화된 평균 오차(NME)이며, 경계 상자 크기의 제곱근에 의해 정규화된 평균 2D 지점 대 점 유클리드 오차
Experimental Results
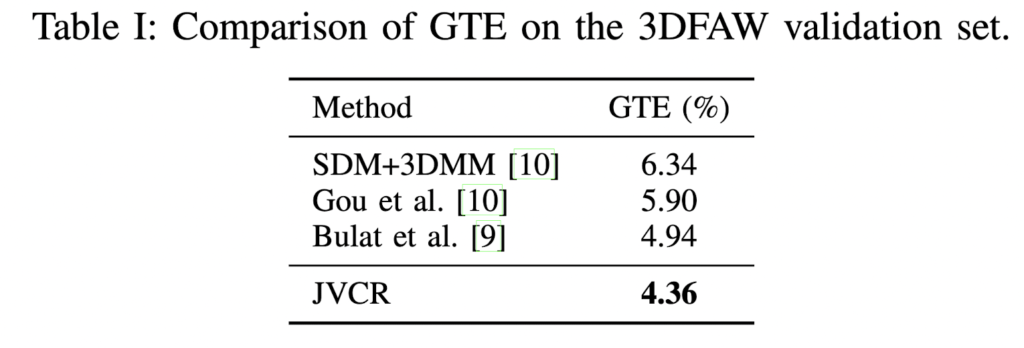
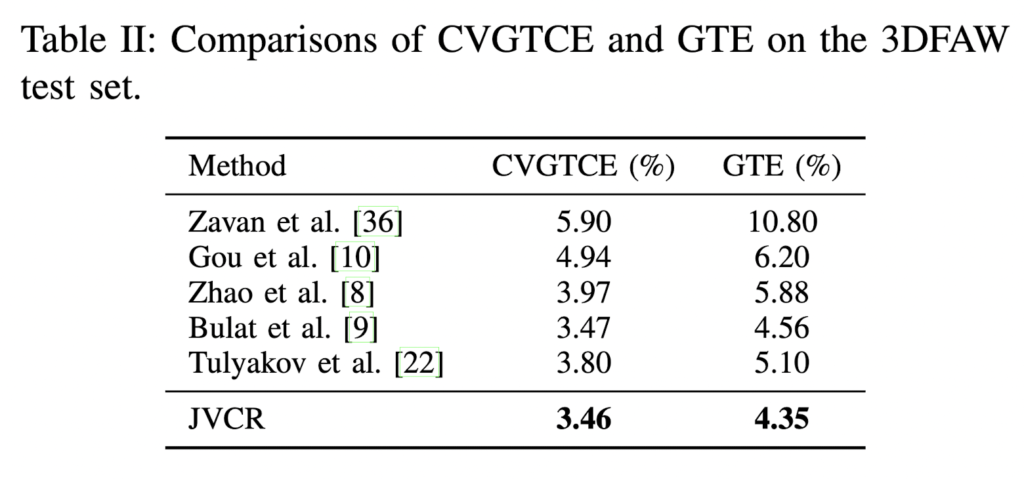
실험 결과는 다음과 같습니다. 먼저 표 I은 검증 세트에 대한 GTE의 비교 결과를 보여줍니다. 표 1에서 2-stage 를 기반으로 하는 다른 방법보다 성능이 우수하다는 것을 알 수 있습니다. 3DFAW 챌린지의 SOTA와 비교하기 위한 3DFAW testset의 CVGTCE와 GTE 는 표 2에서 확인이 가능하며 역시 성능이 가장 높다고 언급합니다. 그림 4를 통해 3DFAW testset에서 제안된 방법의 정성적 평가를 확인할 수 있습니다.

본 논문을 읽으면서 이건 한번 내가 코드를 분석해보고 싶다는 생각이 들기도 하여 신기하였습니다. 얼굴 관련한 데이터셋에 대해 추가로 기술하고 싶은 부분이 있어 그 때 코드도 함께 첨부하려고 합니다. 읽어주셔서 감사합니다.