이번 리뷰는 카네기 멜론 대학에서 제안한 Open Pose 방법론의 전신인 방법론에 대해 소개해보려고 합니다. 해당 방법은 local한 구역에서 스테이지가 변해가면서 global한 부분을 보는 방법을 적용함으로써 이전 방법론(2016년 기준)과는 차별적인 방법을 사용하며, SOTA의 성능을 달성하였던 방법론입니다.
해당 방법론의 가장 큰 의미는 처음으로 confidence map(belief maps)을 이용하여 키포인트를 추론 및 학습했다는 부분에 있습니다. score map을 이용한 방법은 이후 Bottom-up 방식의 pose estimation 방법론에 큰 영향을 끼쳤습니다.
Intro
이전 방법론들(2016년 기준)은 대부분 그래프를 이용하여 사람의 자세를 추정하였습니다. 그래프를 이용한 방법론들은 키포인트를 추정함에 있어서 전문가들이 사전에 정의한 정보들을 이용합니다. 그에 따라 신체 일부(관절 일부)가 보이지 않는 경우, 제대로된 키포인트 추론이 어려운 문제가 있습니다. 저자는 이러한 문제를 해결하기 위해 키포인트의 추론 부분부터 학습하는 방법을 제안합니다. 이번에 리뷰할 Convolutional pose machines(CPM)의 전신인 Pose Machines에서 전통적인 기법(HoG, Random Forests)를 이용하여 local에서 global하게 인지 구역을 넓히면서 다른 부위와의 관계를 고려한 방법을 처음 제안함으로써, 키포인트를 학습을 하여 추론할 수 있게 됩니다. CPM은 전통적인 기법들을 CNN으로 변경한 방법론이라고 보시면 됩니다.
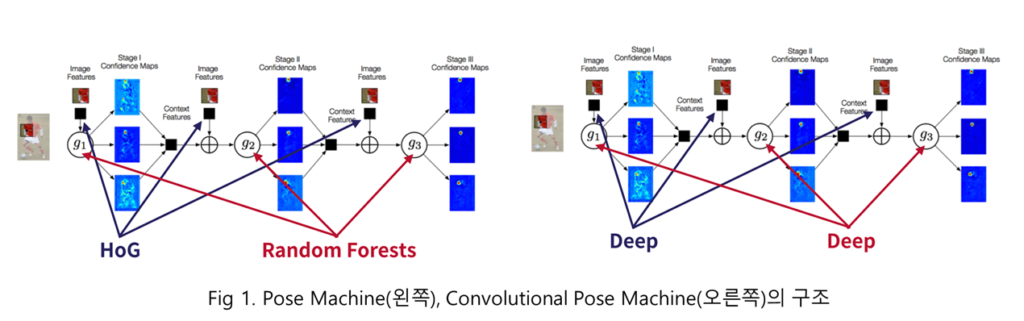
CPM에서는 앞서 설명한 바와 같이 CNN을 이용합니다. CNN으로부터 추론된 confidence map을 다음 stage에서 다음 입력값에 넘겨 개선된 탐지를 진행합니다. 또한 Gradient vanishing 문제를 해소하기 위해서 각각의 stage에서 loss를 설계하여 학습을 수행합니다.
Method
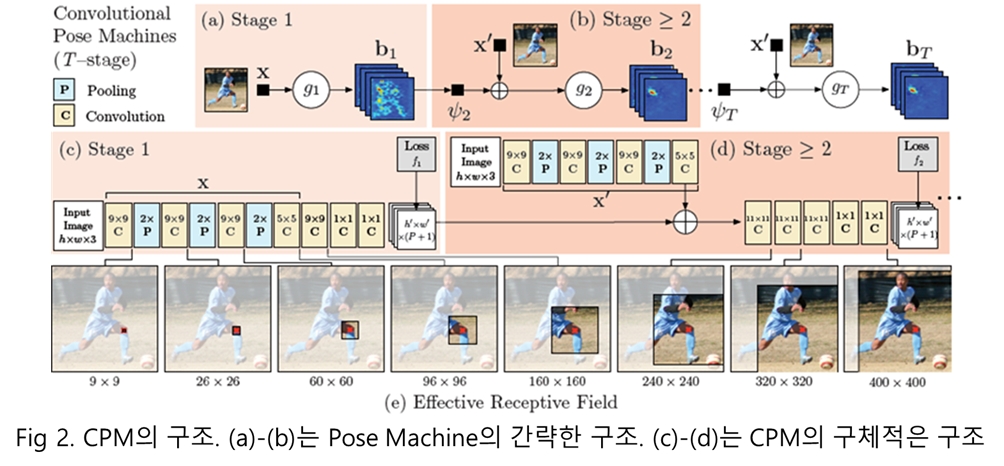
CPM과 PM의 가장 근본적인 목표는 키포인트를 추론하는 것이 목표입니다. 각 관절의 키포인트를 추론하기 위해서 각 관절부를 P개라고 가정하고 Multi-Classifier를 통해 관절부의 위치 Y=(Y_1,...Y_p) \in Z 를 예측하는 방법을 사용합니다.
Pose Machine
Pose Machine에서는 fig 2의 다중 클래스 예측자 g을 통해 계층이 나아감에 따라 개선된 예측을 가져옵니다. g를 통해 P+1 번의 연산(분류)을 반복 수행함으로써 P+1개의 confidence map을 예측합니다. 이를 stage t = 1에서의 분루기는 아래와 같이 정의 됩니다.
++P+1에서 +1은 배경에 속합니다.
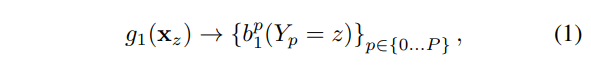
예측자 g1은 영상 위치 x_z에서의 각 키포인트에 대한 score를 예측합니다. 이를 H*W 번 반복 수행함으로써, confidence map b를 예측합니다. 스테이지 1>t 에서부터는 이전에 예측한 스코어 맵을 추가하여 영상 특징을 추론합니다. 일정 크기의 window를 가진 특징 연산자 \psi 를 통해 주변 콘텐츠 정보를 사용합니다.
++ Pose Machine에서는 Random Forest를 분류기로 사용합니다.
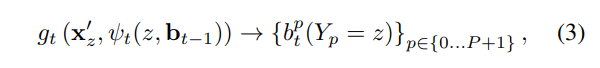
각 스테이지에서의 confidence map b는 아래와 같이 정의됩니다.
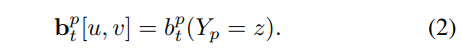
모든 픽셀에서 주변 정보를 가져면서 P+1에 대한 확률 정보를 스테이지가 증가함으로써 개선시키고 이를 토대로 키포인트를 추론하는 방법을 이용합니다.
Convolutional Pose Machines
CPM은 매우 간단합니다. PM에서 사용한 예측자와 특징 연산자가 CNN으로 변경됩니다.
Fig 2 (C)의 X에 해당하는 부분이 특징 연산자에 해당하며, (b)의 X 이후의 컨볼루션이 예측자에 해당합니다. 스테이지 t>1 에서도 (c)와 동일한 cnn으로 대체된 특징 연산자를 사용합니다. 다른 특징은 (c)에서 연산된 특징을 그대로 사용하지 않고, 새롭게 영상으로부터 연산된 값을 t>1 이후에서 반복해서 사용합니다. (d)에서는 11*11 conv를 이용하여 스테이지 1과 다르게 보다 넓은 콘텐츠 정보를 수용하도록 합니다.
좀 더 직관적으로 보자면 아래와 같습니다.
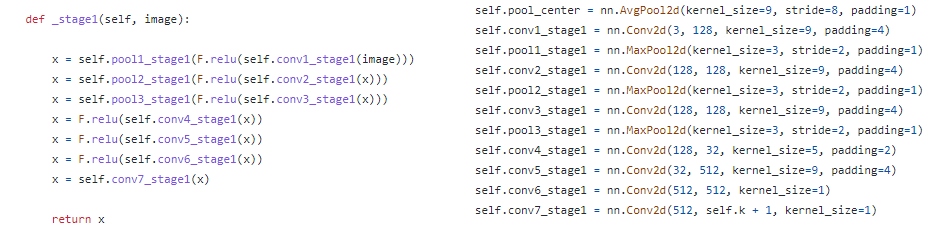
스테이지 1인 경우, 특징 연산자와 예측자가 대체된 CNN으로 구성된 FC로 구축됩니다.
++특징적인 부분은 영상 크기를 유지하기 위해서 padding과 stride를 조정한 것을 볼 수 있습니다. 이는 이후의 스테이지에서도 동일하게 적용됩니다.
스테이지 t>1 에서부터는 예측자가 대체된 CNN으로만 구성됩니다. 또한 이전에 예측된 confidecne map에 해당하는 conv_stage1_map을 concat 하는 것을 볼 수 있습니다. pool3_stage_map은 t>1 부터 사용되는 공통된 특징 연산자에 해당합니다.

공통된 특징 연산자는 다음과 같이 구성됩니다.

++ 각 스테이지에는 논문에서는 표현되지 않은 pool_center_map이 있었습니다. 해당 값은 입력 영상과 동일한 크기를 가지고 중심을 기반으로 생성한 가우시안 분포에 해당합니다. 추측으로는 가우시간 기반의 confidence map을 생성하기 위해 초기화 값으로 넣어준 걸로 보입니다. 추후 기회가 된다면 해당 값을 빼고 학습한 경우를 비교해보는 것도 좋을 것 같습니다.
최종적으로 다음과 같은 값이 출력값으로 연산됩니다.
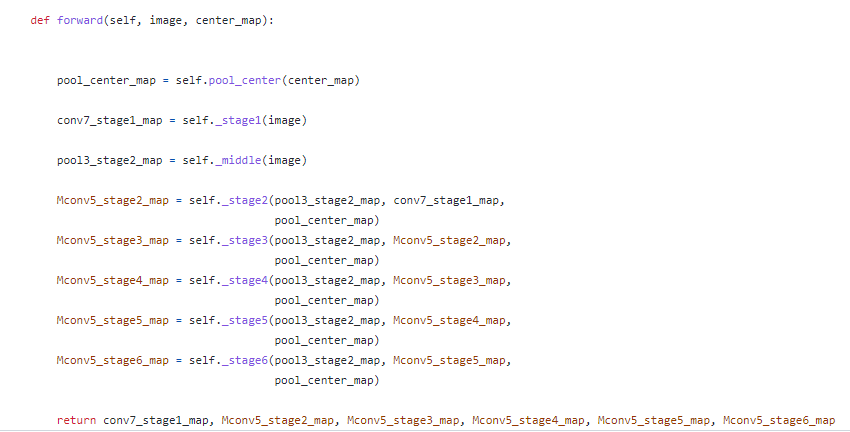
보이는 바와 같이 각 스테이지들은 이전 스테이지의 출력값과 입력 영상 특징 값을 기반으로 연산이 이뤄짐으로써, 점진적으로 receptive field를 늘려가는 특징이 있습니다.
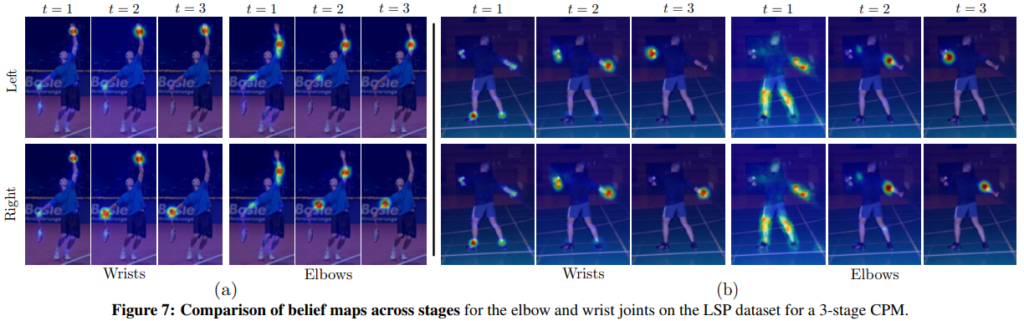
정성적인 결과에서도 스테이지가 증가함으로써 바라보고자하는 특징들이 명확해지는 것을 볼 수 있습니다.
Loss
해당 방법론의 특별한 특징은 Loss에서도 볼 수 있습니다. 저자는 gradient vanishing 문제를 해결하기 위해서 각 스테이지 별로 loss를 구하여 학습함으로써, local~global한 측면에서 보다 강인하게 만듬으로써, 정보 손실을 줄입니다.
상단의 코드에서 보시다싶이 각 스테이지에서의 출력값(heat map)을 모델의 forward을 리턴값으로 뱉습니다.
각 값들은 아래와 같이 개별적으로 loss를 연산하고 loss를 합쳐 backpropagation을 수행합니다.

loss는 MSE Loss를 이용합니다.
그럼 여기서 사용하는 GT인 heatmap_var은 각 키포인트 위치를 기반으로 생성된 가우시안 분포를 이용합니다. 키포인트 + 1개의 가우시안 분포를 생성하고 이를 GT 값으로 이용합니다.
최종적인 output은 코드에서 보시다시피 [H, W, 키포인트+1] 크기의 heat map으로 구성됩니다.
Experiment
평가는 LSP, MPII, FLIC에서 진행되었습니다. 각 데이터 셋에 대한 설명과 평가 방법에 대해서는 이전 리뷰를 참고해주시기 바랍니다.
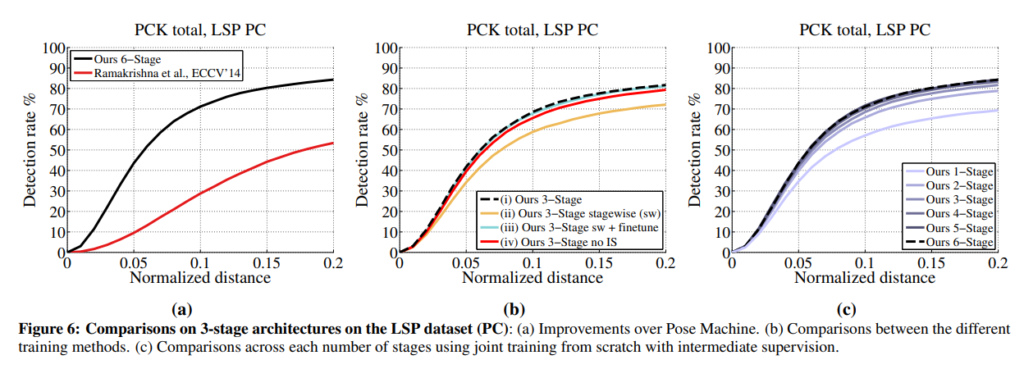
Fig 6의 (a)에서는 이전 방법론과의 비교에 해당합니다.
Fig 6 (b)에서는 여러 학습 방법을 사용하며 비교한 결과에 해당합니다. (i)는 제안한 방법인 모든 loss를 합친 global loss 사용했을 떄, (ii)는 스테이지 별로 학습하고 결합했을 때, (iii)는 (i)와 동일하지만 (ii)의 weight로 초기화한 방법, (iv)는 (i)와 동일하지만 스테이지 별 loss를 사용하지 않고 최종 loss만 이용한 방법에 해당합니다.
Fig 6 (c)는 스테이지를 증가시키면서 성능 향상을 보이고 있으며, 이를 통해 인식 공간을 증가시키는 것이 성능 향상에 영향을 준다는 것을 증명합니다.
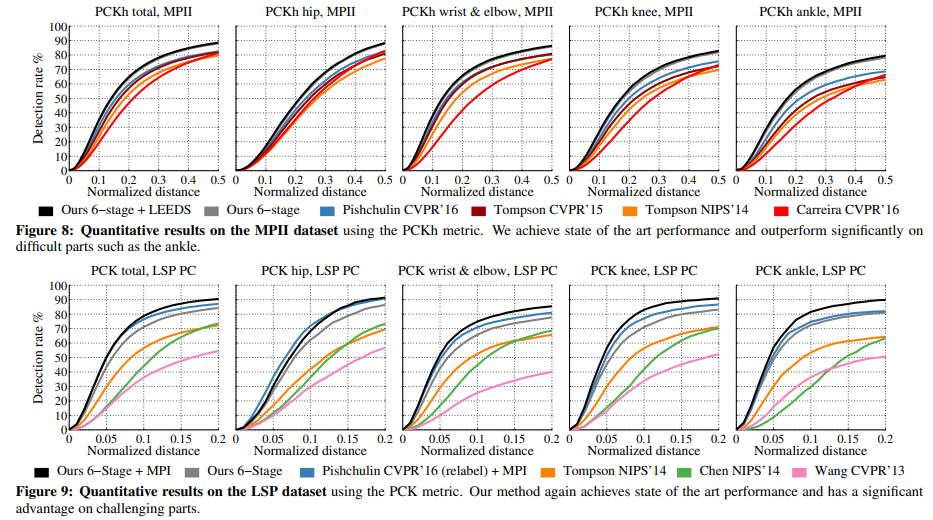

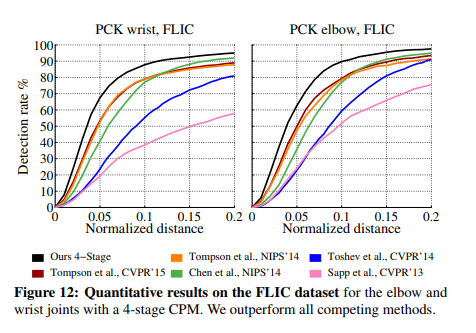
===========================================================================
추론된 feature를 결합하는 방법은 현재에는 흔하게 사용되는 기법에 해당한다. 그렇기에 사용되는 이유를 가볍게 지나치기 쉬웠는데 해당 논문을 통해 각 receptive field를 점진적으로 바라보는 효과가 있다는 것을 처음 깨닫게된 계기였다.
좋은 리뷰 감사합니다. 제가 최근 얼굴 관련 논문을 읽는데, pose estimation에서 영감을 얻어 흡사한 방법론을 사용했다라는 문구를 많이 접하면서 pose estimation 에 대해 궁금했는데 최근 세미나에서도 잘 정리해주셔서 도움이 되고 있습니다.
다만 궁금해지는 것이 풀링을 계속 태우다보면 align에 대한 문제는 발생하지 않나요?
Q. 다만 궁금해지는 것이 풀링을 계속 태우다보면 align에 대한 문제는 발생하지 않나요?
A. 어떤 align 문제가 발생한다는지 모르겠습니다.