Before Review
오늘도 Video Summarization 관련 논문을 리뷰해도록 하겠습니다. 저번에 리뷰했던 [IEEE 2015] Adaptive key-frame Selection for video Summarization 논문은 Neural Network 기반은 아니고 Submodular-Optimization 방법으로 Video Summarization을 진행했습니다.
오늘 가져온 논문은 Learning 기반으로 Video Summarization을 진행하며 Unsupervised 방식으로 진행이 됩니다. 평소에 리뷰했던 논문과 조금 다른점은 Reinforment Learning 과 LSTM이 적용된다는 점입니다.
전체적인 맥락은 저번에 리뷰했던 논문과 비슷하지만 다른 점은 강화학습의 framework를 통해 Video Summarization에서 중요한 Representativeness와 Uniqueness를 보상함수를 통해 최대화하는 구조를 취하고 있습니다.
사실 강화학습은 아예 공부를 해본적이 없어서 논문에 나오는 용어(Agent , Policy Gradient)들에 대해서는 깊이 이해를 하지는 못했기 때문에 컨셉적으로만 접근을 하였습니다.
Introduction
비디오 콘텐츠 시장의 성장으로 인해 비디오를 이해하는 연구들이 관심을 갖게 되었습니다. 다만 비디오를 이해하는데 있어 비디오는 너무 많은 정보량을 가지고 있습니다. 이러한 흐름속에서 Video Summarization의 목표는 말 그대로 비디오를 효율적으로 이해하기 위해 중요한 정보들(key-frame)이 무엇인지 알아내는 것입니다.
여기서 고려해야할 점은 Supervised 방법론은 적절하지 않다는 것입니다. 애초에 비디오를 효율적으로 이해하기 위해서 본 연구가 진행되는 것인데 , 비디오를 잘 이해하기 위해서 비디오에 대한 사전 정보(Annotation)이 필요한 상황이 아이러니 하기 때문에 저는 Unsupervised 방법론을 주로 찾아보게 되었습니다.
Unsupervised 기반의 Video Summarization은 크게 두가지의 흐름이 존재합니다.
- GAN 기반의 방법론
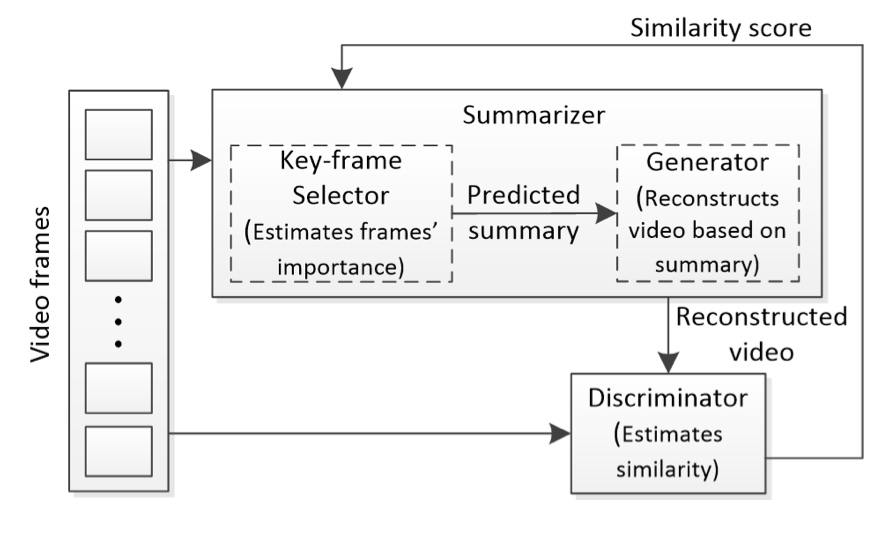
간단하게 요약하면 , Summarization 된 요약본 영상을 가지고 Generator가 그럴듯한 원본 영상을 Reconstruction을 해줍니다. Discriminator는 본인에게 들어온 영상이 정말 원본 영상인지 Generator가 만들어준 그럴듯한 Reconstruction 영상인지 구분하게 됩니다. 결국 이 경쟁을 통해서 Discriminator를 속일 수 있을 만큼의 영상을 만들 수 있는 Summarization을 얻을 수 있게 됩니다.
- Reinforcement Learning 기반의 방법론
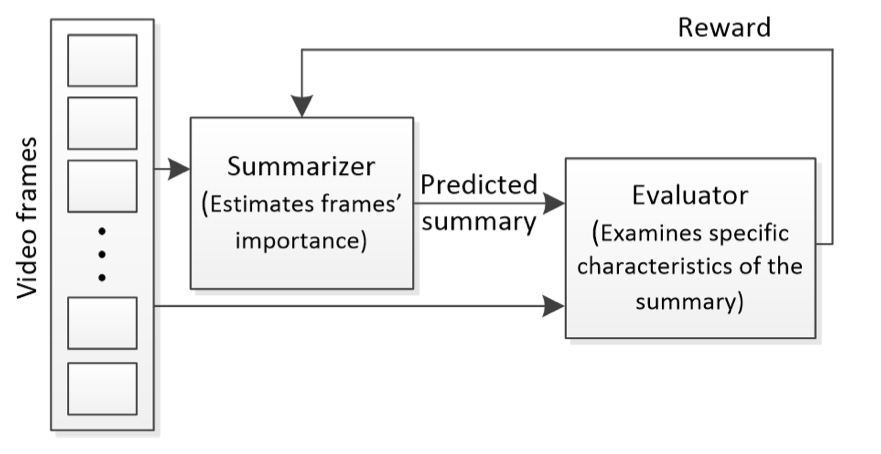
RL기반의 방법론은 익숙하진 않아서 개념적으로만 설명을 드리겠습니다. Summarizer라는 Network가 frame의 importance를 고려해 Summarization을 진행하면 Evaluator라는 녀석이 만들어진 Summarization을 가지고 Reward(보상)을 계산하게 됩니다. 이 보상을 가지고 Summarizer가 학습이 진행되고 결국 Summarizer는 더 많은 보상을 얻을 수 있도록 Summarization을 만들어내는 그런 구조입니다.
본 논문에서 사용하는 Framewok는 RL 기반의 Summarization이고 Unsupervised 기반의 Video Summarization 분야에서 처음으로 RL을 도입한 논문이라고 합니다. 사실 코드가 공개 되어있어서 논문을 골랐는데 기반이 되는 논문을 고르게 되었네요.
그렇다면 본 논문에서 제안하는 네트워크에 대해서 이야기를 시작해보도록 하겠습니다.
Deep Summarization Network
Network
본 논문에서 제안하는 Framework의 큰틀은 Video Summarization을 연속적인 decision-making process로 간주한다는 것 입니다. Frame마다 확률을 추정하게 되는데 이 확률은 Frame이 Key-frame으로 간주될 확률을 의미하며 , 확률이 높을 수록 중요하다고 보시면 되겠습니다.
Convolutional Neural Net(GoogleNet)으로 Frame feature를 추출해주고 , 추출된 Feature를 가지고 LSTM network에 전달해주면 확률이 반환되는 구조입니다. LSTM을 사용한 이유는 비디오의 긴 Sequence 정보를 처리하기 위해 사용해준다고 합니다.

LSTM에 포함되는 FC Layer를 통해서 반환되는 확률을 통해 프레임들을 Summary에 포함시키고 만들어진 Summary를 가지고 Reward를 계산해주게 됩니다. 계산된 Reward를 통해 Gradient가 Update 되는데 이과정에서 사용 되는 방식이 Policy-based Gradient라고 합니다. 이 방식을 통해 LSTM만 학습이 진행되고 Feature를 Extraction 해주는 Encoder는 Update 해주지 않습니다. 이렇게 Summarization을 만들고 Reward를 계산했을 때 Reward를 최대화시킬 수 있는 Summary를 만드는 것이 본 Framework의 목표입니다.
Reward Function
우선 우리가 Summarization을 만들었을 때 계산되는 Reward가 어떻게 정의 되는지 부터 알아보도록 하겠습니다. 사실 여기서 다루는 개념은 제가 이전에 리뷰했던 [IEEE 2015] Adaptive key-frame Selection for video Summarization 와 동일합니다.
Video Summarization에서 중요하게 고려되는 요소는 두가지 입니다.
Diversity(Uniqueness)와 Representativeness로 두 요소를 Summarization이 잘 고려해서 Original Video을 최대한 보존할 수 있어야 합니다. 가급적이면 Summarization에서는 중복되는 것 없이 다양한 Frame이 분포했으면 좋을 것이고 , 원래 비디오를 캐치할 수 있게 Representation도 좋아야 할 것 입니다.
- Diversity Reward
결국 Summarization이 다양하게 분포를 하려면 선택된 Frame들이 유사하지 않게 뽑으면 될 것 입니다. 결국 Summary로 채택된 Key-frame들끼리의 dissimilarity를 최대화 시키면 될 것 입니다.
- R_{div}=\frac{1}{\mid Y\mid (\mid Y\mid -1)} \sum_{t\in Y} \sum_{t^{\prime }\in Y} d(x_{t},x^{\prime }_{t}) — (3)
- d(x_{t},x^{\prime }_{t})=1-\frac{x^{T}_{t}x^{\prime }_{t}}{\parallel x_{t}\parallel_{2} \parallel x^{\prime }_{t}\parallel_{2} } — (4)
Diversity Reward를 최대화 하려면 결국 (4)를 최대화 해야하고 , (4)를 최대화 한다는 의미는 두 frame feature vector들끼리의 코사인 유사도가 -1에 가깝도록 (아예 다를 수 있게) 선택해야 하는 상황입니다. 즉 , frame feature끼리의 유사도가 낮을수록 Diversity Reward가 크게 발생하도록 설계 됐다고 보시면 되겠습니다.
여기서 비디오 같은 경우는 단순히 vector 끼리의 유사도만을 가지고는 충분하지 않습니다. 시간적으로도 얼마나 거리가 있는지도 고려를 해야하기 때문입니다. 그래서 두 프레임이 시간적으로 일정 Threshold 이상 떨어져 있다면 그냥 dissimilarity는 1로 최대값으로 고정을 시켜준다고 합니다. Temporal 거리 만큼 weight나 attention을 주는 구조는 아니지만 간단하게라도 temporal distance를 고려해주고 있는 모습입니다.
- Representativeness Reward
다음으로는 Representativeness Reward 입니다. 사실 Original 영상을 잘 표현한다는게 조금은 추상적이긴 하지만 본 논문은 이 문제를 k-medoid problem으로 해결했다고 합니다. k-medoid problem은 K-means가 노이즈에 민감하다는 단점을 개선하기 위해 이상치에 Robust한 중앙값을 가지고 Cluster를 만드는 것을 얘기한다고 합니다.
사실 저는 여기가 이해가 안되는데 그냥 수식으로 보도록하겠습니다.
- R_{rep}=exp(-\frac{1}{T} \sum^{T}_{t=1} \min_{t^{\prime }\in Y} \parallel x_{t}-x^{\prime }_{t}\parallel_{2} )
Representativeness가 최대가 되려면 시그마로 계산되는 summation이 최소가 되어야 합니다.(그래야 exponential이 최대가 되므로) 계산은 어떻게 되냐면 원본 비디오 프레임을 하나씩 읽어와서 Summary에 있는 프레임과 L2-distance를 계산하고 mininum distance만 시그마 연산을 진행하게 됩니다. 근데 여기서 궁금한게 Original frame들을 하나씩 읽어올 때 summary에 포함된 frame까지 읽어오는 지 궁금한데 , 동일한 frame끼리의 거리는 0이 나와버리니 아마 같은 frame끼리는 생략을 하는 것이라 예상이 됩니다.
원본 비디오 프레임간의 거리를 최소화 시키는 key-frame 즉 전반적으로 잘 표현하는 medoid frame을 selection 하는 게 목표라고 합니다.
Training with Policy Gradient
Policy Gradient라는 개념이 등장합니다. 강화학습에 자주 사용되는 방법론이라고 합니다. 제가 이 논문을 읽으면서 강화학습에서는 Optimization을 어떻게 하는지 까지는 읽을 겨를이 없어서 그냥 본 논문에서 어떻게 Gradient를 계산했는 지만 서술해보도록 하겠습니다.
Summarization agent의 목적은 Reward Function을 최대화 시켜주는 Policy Function을 학습하는 것이라고 합니다. agent는 action을 취하는 주체로서 여기서는 그냥 summarization 하는 녀석이구나 라고 보시면 됩니다. 이때 policy라고 하는 것은 agent의 action을 결정하는 규칙이라 보면 되고 결국 강화학습 알고리즘은 이 최적의 policy function을 찾는 것이라고 보면 됩니다.
본 논문에서 사용하는 Policy function은 다음과 같이 정의가 된다고 합니다.
- J(\theta )=E_{p_{\theta }(a_{1}:T)}[R(S)]
이때 1992년도에 제안된 강화학습 알고리즘과 계산 복잡도를 피하기 위해 근사를 취해주면 아래와 같이 Gradient를 계산할 수 있다고 합니다.
- \nabla_{\theta } J(\theta )\approx \frac{1}{N} \sum^{N}_{n=1} \sum^{T}_{t=1} (R_{n}-b)\nabla_{\theta } log\pi_{\theta } (a_{t}|h_{t})
어째서 이런식으로 Gradient를 계산해주는지 까지는 파악하지 못했지만 무튼 강화학습에서는 최적의 Policy Function을 찾는 것이 목적이라고 합니다.
Regularization
지난번에 리뷰했던 논문과 비슷하게 Summary의 크기에 penalty를 주기위해 Regularization을 진행합니다. training을 진행하면서 아래의 term을 minimize해주게 됩니다.
- L_{percentage}=\parallel \frac{1}{T} \sum^{T}_{t=1} p_{t}-\varepsilon \parallel^{2}
여기서 엡실론(\varepsilon)은 몇 퍼센트의 frame을 selection 할지 나타내는 percentage로 0.15라면 전체 프레임중 15퍼만 selection 하겠다는 의미입니다. 저도 이 term이 확 와닿지는 않았는 데 뭔가 Network가 학습하는 확률분포에 penalty를 주어서 Reward를 높이기 위해 무작정 뽑지 못하게 minimize 해주는 작업인 것 같습니다.
- L_{weight}=\sum^{}_{i,j} \theta^{2}_{i,j}
weight parameter가 overfitting 되지 않도록 L2 regularization도 진행을 해준다고 합니다.
Optimization
Optimization은 stochastic gradient-based 방법론을 사용하고 그중에서 Adam Optimizer를 사용해준다고 합니다.
- \theta =\theta -\eta \nabla_{\theta } (-J+\beta_{1} L_{percentage}+\beta_{2} L_{weight)}
Reward function은 최대화를 시켜주기 위해 Gradient ascent를 해주고 있고 나머지 Regularization term은 minimization 하기 위해 Gradient descent를 해주고 있습니다.
Experiments
Dataset은 SumMe와 TVSum이라는 데이터를 사용했다고 합니다. SumMe 데이터셋은 Holiday나 Sport 콘텐츠를 다루는 데이터셋이고 , TVSum은 뉴스나 다큐멘터리를 다루는 데이터셋이라고 합니다. 살짝 아쉬운건 데이터셋을 이 두가지만 사용을 했다고 합니다.
Metric은 Ground Truth summary와 F-score를 가지고 측정했다고 합니다.
- Quantitative Evaluation
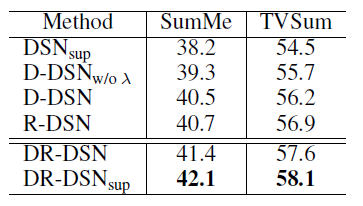
위의 테이블은 본 논문에서 제안된 Network의 Ablation Study입니다.
- D-DSN : Diversity Reward만 고려해준 성능입니다.
- R-DSN : Representativeness Reward만 고려해준 성능입니다.
- DSN w/o λ : temporal threshold를 고려해주지 않은 성능입니다.
- DSN sup : DSN을 조금 변형시켜 Superivsed 방식으로 학습한 성능입니다.
확인해야 할 점은 역시 Diversity와 Representativeness를 모두 고려해야 높은 성능이 나오고 있고 , temporal threshold를 적용하지 않으면 성능 하락이 조금 발생한다는 점입니다.
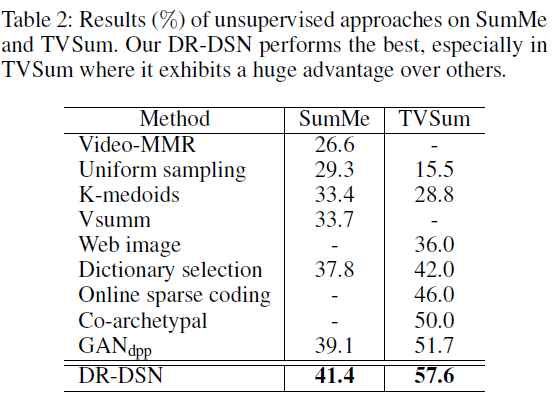
위의 테이블은 Unsupervised 기반의 방법론들과 성능 비교 테이블이며 SOTA를 달성하고 있는 모습입니다. TVSum Dataset에 대해서는 특히 큰 Gap을 보여주고 있습니다.
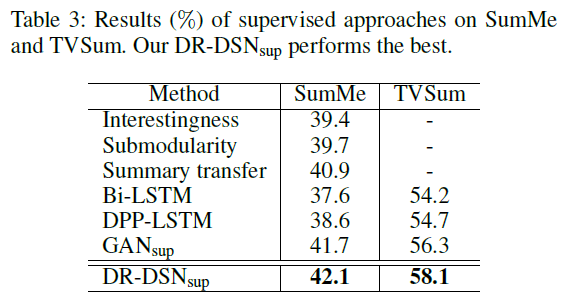
마지막으로 supervised 기반의 방법론들과 성능비교를 하고 있는 데 우선 DR-DSN을 supervised 방식으로 학습 시킨다면 supervised 내에서 SOTA를 달성하고 있습니다. 하지만 DR-DSN의 unsupervised 성능 또한 (SumMe : 41.4 , TVSum : 57.6)으로 상당히 높은 성능을 보여주고 있습니다.
정성적 평가는 논문에서 다루기는 하지만 제가 직접 ActivityNet을 가지고 뽑아본 Summarization이 있어서 세미나 시간에 같이 살펴보는 것으로 하겠습니다.
Conclusion
우선 본 논문을 읽으면서 새롭게 알아가는 지식이 많았던 것 같습니다. 강화학습은 흥미로웠지만 , 어려웠습니다. 가끔 비디오 논문 읽기 싫어지면 강화학습 논문도 종종 읽어봐야겠습니다.
제가 직접 본 논문의 코드를 가지고 ActivityNet을 학습을 시켜봤는데 세미나 시간에 Summarization이 어떻게 됐는지 Sample 영상 몇개를 보여드리도록 하겠습니다.
리뷰 읽어주셔서 감사합니다.
좋은 리뷰 감사합니다! GAN 기반 방법론이 있다는 것이 신기하네요.. 해당 모델은 생성자와 판별자가 충돌하는 부분도 많고 데이터 크기도 커 학습이 좀 어려울것같은데 혹시 이에대해 어떻게 생각하시는지 혹은 논문에 언급이 있는지 궁금합니다! 기존 방식이 학습이 어려워 RL 방법으로 설계된 것인가요?
우선 GAN 가지고 제가 직접 해본 것은 아니지만 서베이 논문에는 확실히 GAN 기반의 summarization은 안전성이 떨어진다는 언급이 있습니다.
본 논문에서는 GAN의 단점을 보완하기 위해 RL을 도입한것은 아니고 , 기존의 RL 가지고 superivsed 기반의 summarization을 보완하여 unsupervised 방식으로 제안한 것 입니다.