안녕하세요 이번에 가지고 온 논문은 2021년 IEEE Transactions on Neural Networks and Learning Systems에 나온 멀티스펙트럴 기반 보행자 인식관련 논문 입니다. AR-CNN의 확장판이라고 보시면 됩니다.
기본적으로 읽게된 이유는 Alignment 문제를 다루는 논문을 찾던 중 IF지수가 꽤 높은 저널에 Early Access로 등록이 된 논문이었기 때문입니다. 사실 AR-CNN의 확장판인건 그 이후에 알았습니다. 결론적으로 말씀드리자면… AR-CNN 논문을 읽어보신 분들에게는 추천드리지 않는 논문입니다. 저는 사실 AR-CNN을 예전에 속성으로 빠르게 읽어보긴 했지만 정독한적이 없었어서 이번에 소개드리는 논문을 읽고 큰 불만은 없었지만, 김지원 연구원말을 들어보면 AR-CNN과 비교했을때 큰차이가 없는거 같습니다.

먼저 해당 논문에서 이슈라이징 하고자하는 문제는 바로 Alignment 문제입니다. 아시다시피 멀티스펙트럴 센서를 사용하면 성능면에서는 이점을 가지지만, RGB영역의 카메라와 Thermal 카메라를 정확하게 Align 시키는데는 제약이 따릅니다. 보통 이렇게 Alignment 문제는 Resolution Difference 나 FOV 차이 때문에 생기게 됩니다.
이러한 Alignment를 해결하기 위해서 pixel-level 로 warping하여 강제로 Alignment를 맞추는 방법도 있지만, 아무래도 정확하다고 할 순 없습니다. 해당 문제점을 좀 더 개선하기 위해 카이스트 데이터셋에서는 beam splitter를 사용하여 광학축을 맞추어 theraml과 RGB 영상의 alignment를 맞추었습니다. 이러한 노력으로 카이스트 데이터셋은 다른 멀티스펙트럴기반 데이터셋들에 비해서 image pair가 좀 더 aligned 되어 있다고 할 수 있지만 여전히 문제점이 완벽하게 해결된 것은 아닙니다.
카이스트데이터셋은 이론적으로 perfectly-overlapped image pairs를 가지고 있어야 하지만 실질적으로 취득된 데이터셋은 그러하지 못합니다. 원인을 분석하기위해 데이터셋을 살펴보면, 코너링을 한다거나, 과속방지턱을 넘는 등 격동적인 액션이 차에서 발생할때, alignment가 깨지는 현상이 발견됩니다. 또한, bbox를 annotation 하는 과정에서도 사람의 실수에 의해서 mis-alignment problem이 발생할 수 있습니다. 해당 페이퍼에서 주장하는 메인 컨셉은 바로 이 alignment를 해결하자 입니다. 위의 Fig. 1은 카이스트 데이터셋에 존재하는 misaligned image pairs를 보여줍니다.
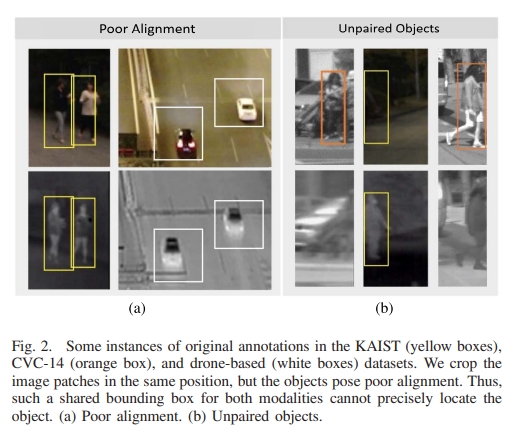
그리고 Alignment 문제를 넘어서 unpaired 케이스도 존재한다고 언급을 하는데요. 여기서 말하는 unpaired의 정의는 두개의 모달리티중에서 한개의 모달리티에만 pedestrian 이 나타나는 경우 입니다. 용어는 페이퍼마다 다르게 쓰이는 경향이 있어서 정의하고 넘어갈 필요성이 있어 보입니다.
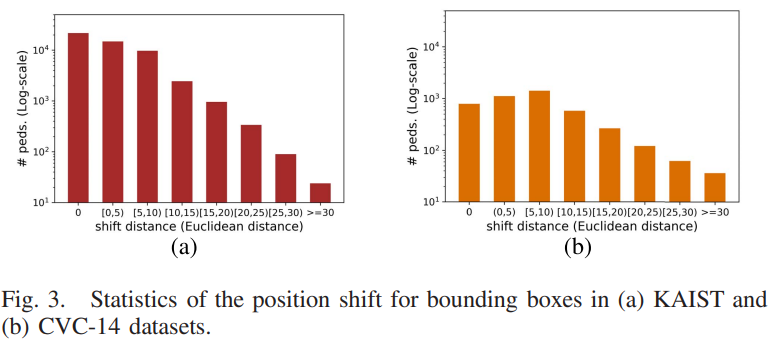
데이터셋을 분석해보니 확실히 CVC-14보다는 카이스트셋이 shift distance가 낮은 경향이 있는걸 확인 할 수 있습니다. CVC-14는 extrinsic parameter error, resolution difference between sensors, misaligned bboxes 등의 이유로 shift problems가 더 많이 존재합니다.
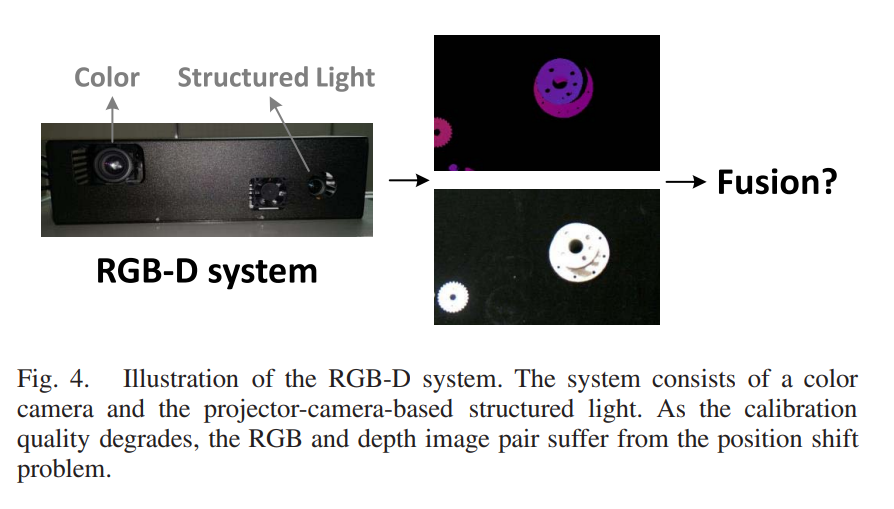
추가적으로 RGB-D 시스템으로 데이터셋을 수집하여 RGB하고 Depth Sensor간에 발생하는 shift problem에 관한 실험도 진행하는데 그 때 사용하는 센서 시스템 구성입니다.
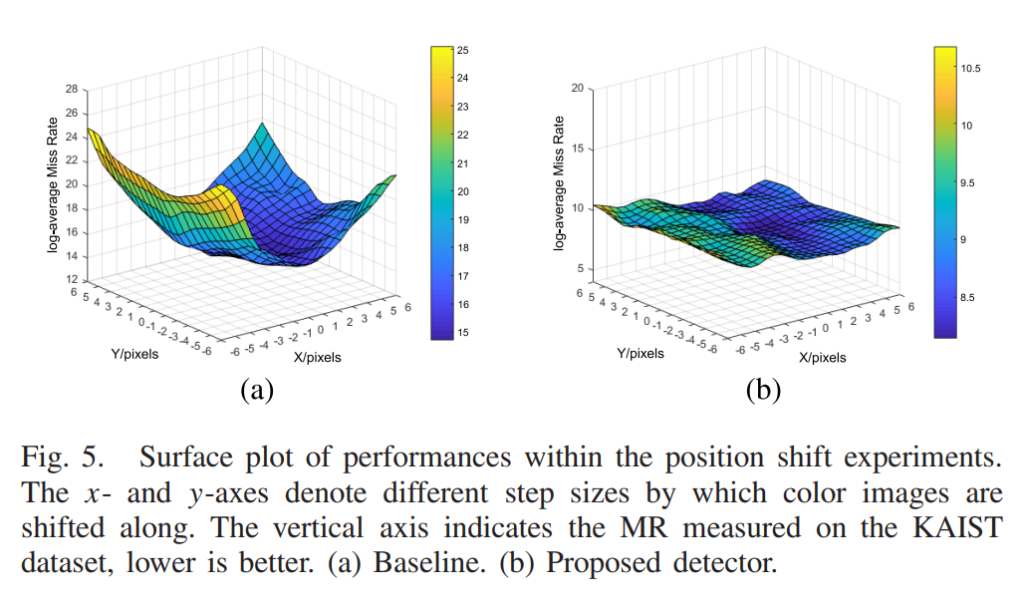
위의 그림은 X하고 Y 축으로 shift가 발생했을 때의 miss-rate를 3차원으로 plot 한 것 입니다. 직관적이고 보기 편한게 성능을 보여주기 좋은 방법이라고 생각이 됩니다.
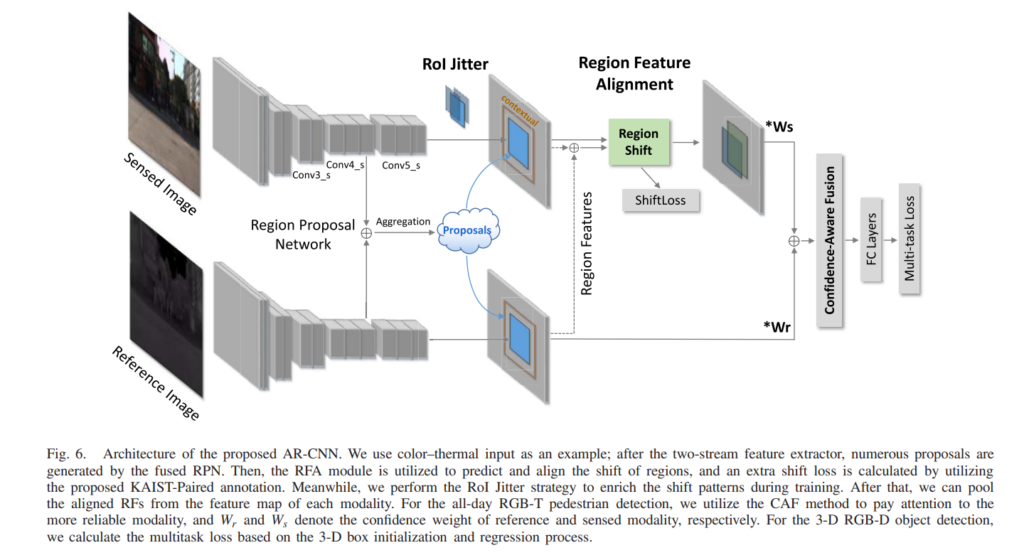
그리고 shift problem을 해결하기위해 제안한 전체적인 파이프라인 입니다. RoI Jitter 하고 RFA 모듈이 핵심적인 것이고, 사실상 아키텍쳐는 Faster-RCNN을 중간레벨 피쳐에서 Merge하는 Halfway fusion 과 같습니다. 기존 KAIST 데이터셋의 Annotation은 Thermal을 기준으로 bbox를 쳤으며, RGB는 해당 bbox를 그대로 사용합니다. 그러나 해당 모델에서는 shiftLoss 텀을 두어서 RGB와 Thermal간의 shift에 대한 GT가 있어야 하므로 추가적으로 paired annotation을 만들어서 제공합니다.
사실상 성능이 오른 이유는 model에 좀 더 많은 정보를 사람이 manual하게 주었기 때문이 아닌가 라는 생각이 드는데요. 어찌됐든 annotation을 다시 하였고, 해당 과정에서 labour cost가 발생했기 때문에 결국에 최선책은 아니라고 생각이 드는데요. 그래도 한번에 모든 문제를 해결할 수는 없기 때문에 좋은 시도라고 생각이 됩니다.

모델에서는 위와 같은 알고리즘 과정을 거치면서 Region shift를 구합니다. 사실 앞의 부분은 Halfway fusion과 동일한데 뭔가 알고리즘이라고 하며 장황하게 써두어서 괜히 어려워 보이네요. 내용은 Halfway Fusion 에서 각각의 모달리티로 부터 feature를 뽑아내고 중간단계의 피쳐맵에서 Concatenate한 다음 해당 피쳐에서의 RoI를 뽑아내게 되게 됩니다. 그리고 그 RoI를 다시 각각의 모달리티에 할당하고, 피쳐단에서의 shift를 구하게 됩니다. 최종적으로 각각의 모달리티에 CAF모듈을 통해 구한 weight를 곱한 후 confidence-aware fusion을 통해 스코어 퓨전을 한뒤 이 후의 과정은 Faster RCNN과 동일합니다.
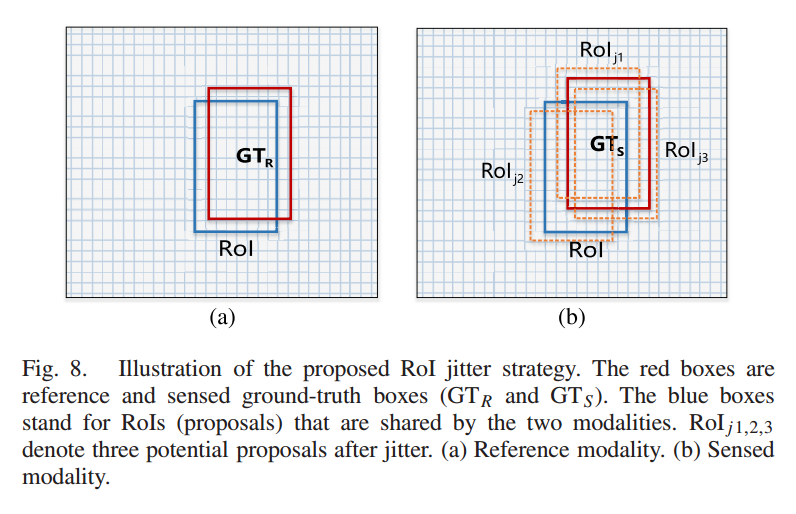
위 과정에서 RoI jitter라는 방법을 사용하는데 해당 방법은 shift에 좀 더 다양한 pattern을 주고자 RoI에 shift를 랜덤으로 좀 더 다양한 패턴으로 바꾸어 주는 것 입니다.
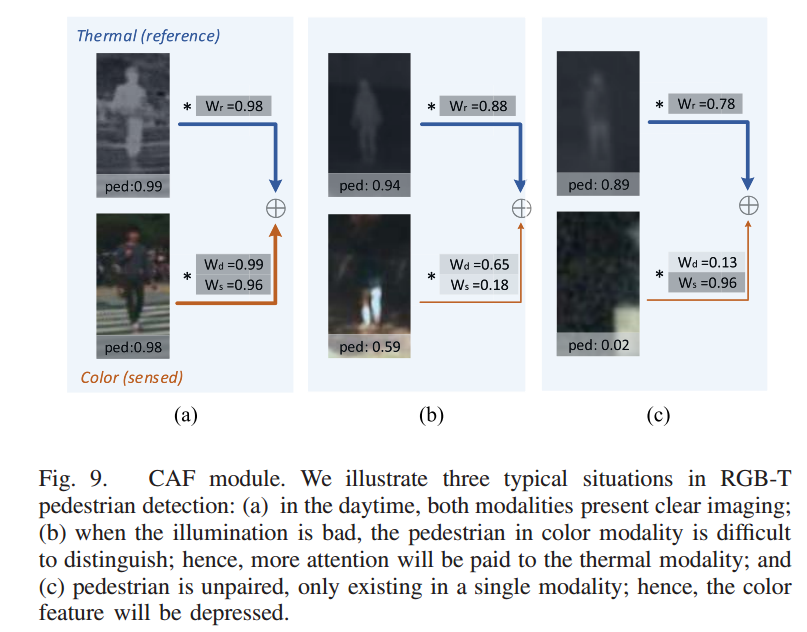
위에서 언급했던 각각의 모달리티에 weight를 주기 위해 사용한 CAF 모듈은 위와 같은 형태로 working합니다.

좀 더 자세히 해당 모듈은 위의 설명에서 말하듯 foreground와 background의 prob. 를 빼고 절댓값을 씌워서 해당 값을 confidence weight로 사용합니다.
평가
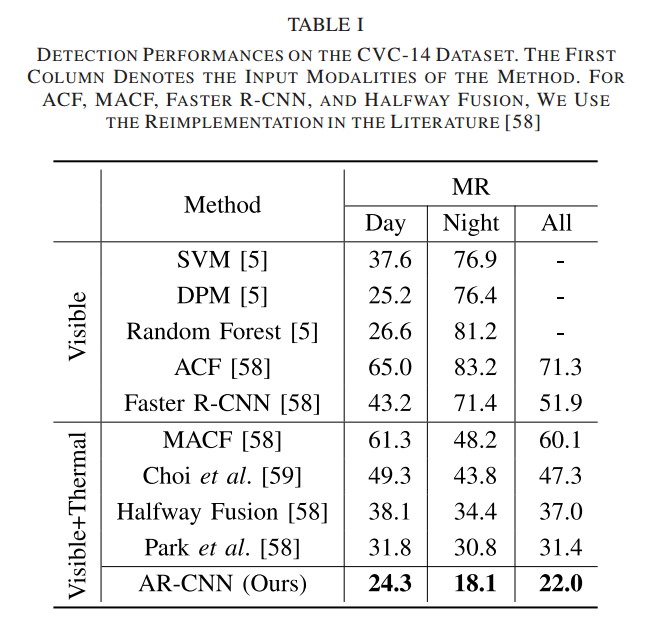
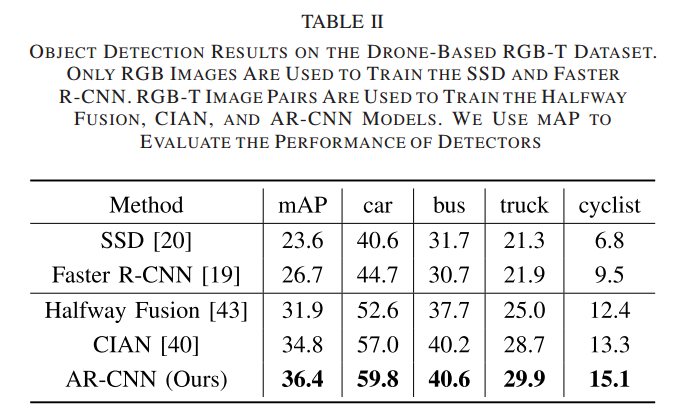
각각 CVC-14와 drone 데이터셋에서의 평가입니다.
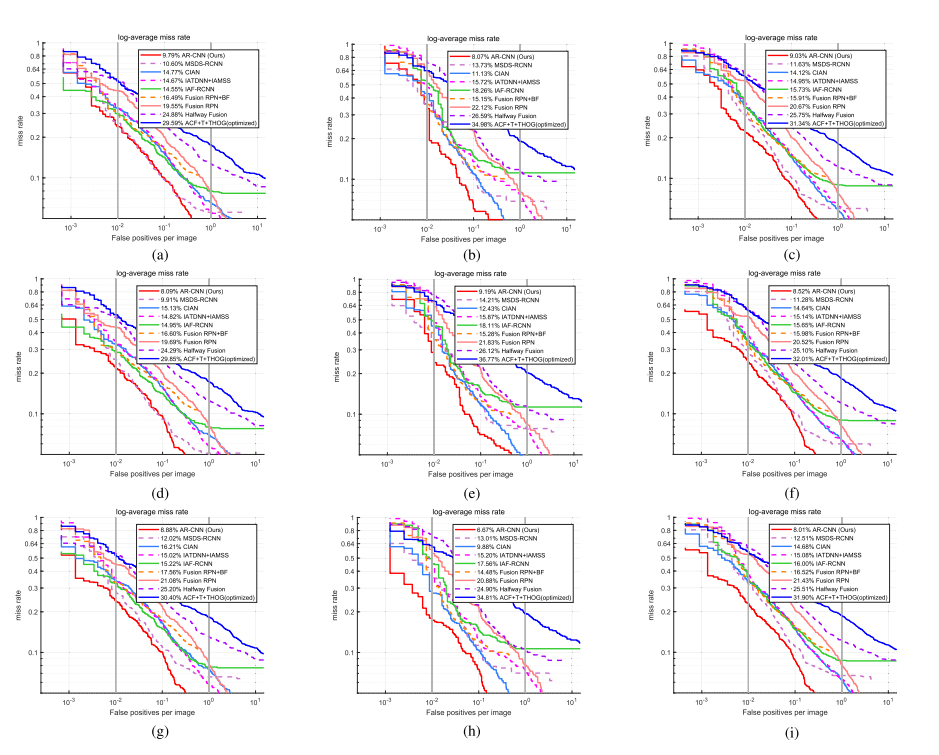
위에는 카이스트 데이터셋에서의 평가입니다. CVC-14와 카이스트에서 소타를 달성했다고 하는데 실제로는 더 좋은 성능을 보이는 논문들도 존재하는데 잘못된 표현인거 같습니다. 해당 논문은 AR-CNN 논문 확장버전이기 때문에 AR-CNN논문이 나올 당시에는 소타였을진 모르겠는데 해당 논문이 나오는 시점에서는 소타가 아닌데 수정이 필요해보이네요.
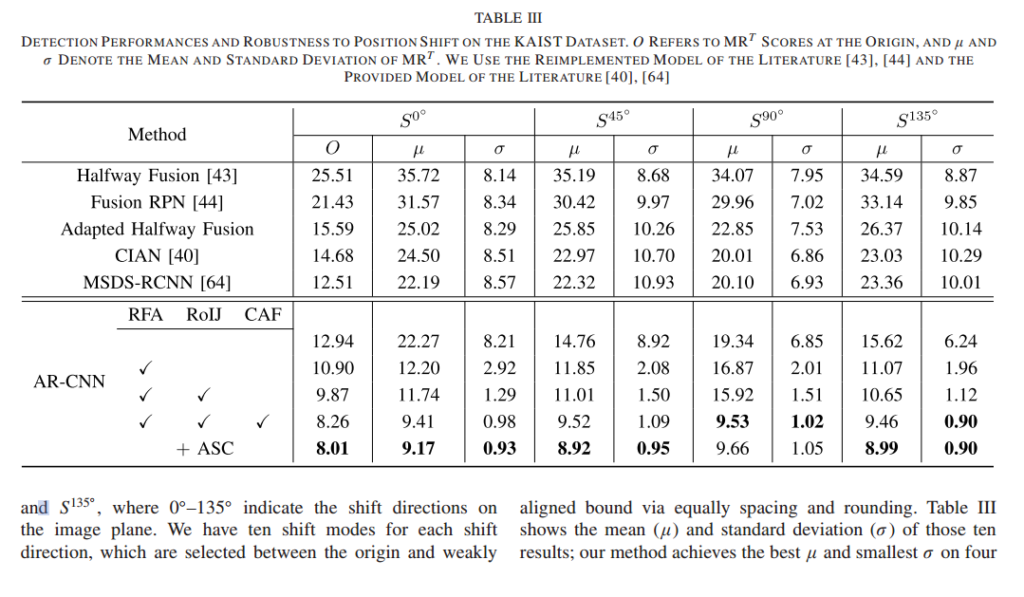
Ablation study와 shift 실험이 동시에 되었네요. S는 shift direction에 대한 지표이고, RFA, RoIJ, CAF는 해당 논문에서 제안한 3가지 방법론들 입니다. 시그마랑 뮤는 표준편자, 평균을 의미합니다.
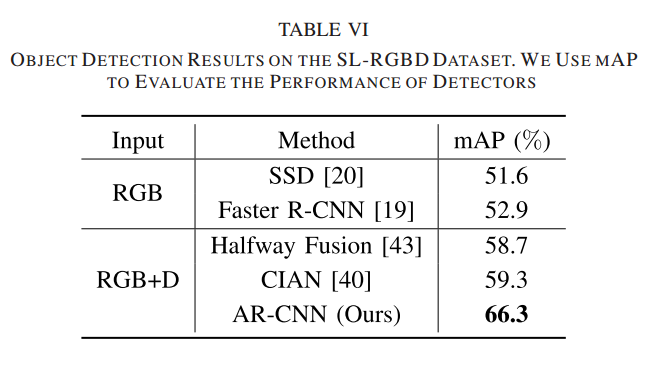
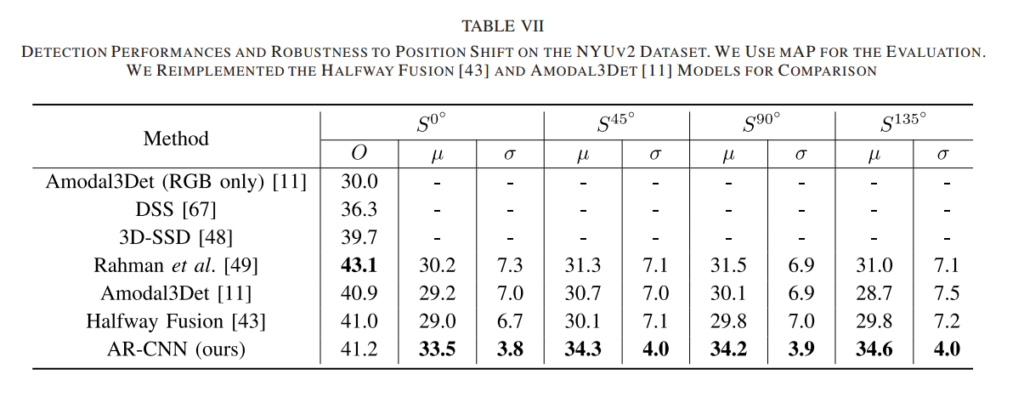
추가적으로 RGB-D 에서도 성능이 잘 나왔다고 합니다. 데이터셋은 SL-RGBD와 NYUv2를 사용하였네요. NYUv2는 개인적으로 처음보는데 SL-RGBD는 YCB 데이터셋을 서브샘플링하여 만든거 같습니다. NYUv2는 popular하지만 challenging한 데이터셋이라고 소개를 하네요. RGB-D에서도 마찬가지로 shift실험을 하였고 shift에 좀 더 robust하다는 결론을 이끌어냈다는건 의미가 있다고 생각하네요.
결론
AR-CNN을 읽었으면 읽을 매리트가 딱히 없는 논문이나 Paired annotation의 탄생배경이나 어떤식으로 활용하였는지 등의 모티브를 얻기에는 좋은 논문.
최근에 YOLO-V4를 이용하여 SOTA논문을 원복하는 실험을 하고있는데 그 과정에서 training annotation에 대한 설명이 논문에 빠져있는것을 발견하였습니다. 일단 트렌드에 맞게 paired annotation을 사용할 생각인데 paired를 사용하면 thermal만 사용할 것인지 color만 사용할 것인지 둘다 사용할 것인지에 대한 고민에 빠졌습니다. 그러한 궁금증을 해소하기 위해 이 논문을 읽기도 하였는데 결론적으로는 일단 thermal에 대한 annotation만을 가지고 가는게 나을거 같네요. 이유는 YOLO-V1를 백본으로 사용하는 SOTA논문에서는 shiftloss와 같은 term 이 없기 때문입니다.
RGB-D 외에 드론으로 촬영한 데이터셋에도 적용한것으로 아는데, 드론 데이터셋의 경우 misalignment 문제가 더욱 클것으로 예상되는데, 마지막에 mAP 성능만 보여지고 있어서 많이 아쉬움이 남습니다. 해당 방법론에 대해서 논문에서는 더 자세한 설명이 나타나 있을까요?
아쉽게도 말씀하신 부분은 논문에서 다루고 있지 않네요.
리뷰 잘 읽었습니다.
리뷰 마지막 정리글에 Paired annotation의 탄생 배경을 알 수 있다고 하셨는데 저는 아직 이해가 잘 안됐네요ㅠ. unpaired라는 용어가 한쪽 도메인에는 사람이 있고 다른쪽에는 없는 경우라고 하셨는데, 그렇다면 paired annotation은 두 쪽 모두 사람이 있을때만 GT box가 쳐져있는 것을 의미하는건가요??
기존에 카이스트 데이터셋은 thermal만을 기준으로 bbox를 쳤었는데 paired annotation에서는 thermal과 RGB모두에 바운딩 박스를 칩니다. 그리고 bbox가 배경을 포함하지않고 사람만들 포함하도록 annotation을 하였습니다. 결국엔 shiftloss를 설계하기위해 GT가 필요하니 annotation을 두개의 모달리티에 한 것 입니다.
확장 논문을 작성하면서 이전에 사용한 그림들을 살렸나보네요. 그래서 그런지 리뷰를 읽으면서 익숙한 그림들이 많이 보이네요.
RGB-D 실험에서 입력값을 RGB와 Depth map을 이용한 건가요?
맞다면 굳이 Depth map을… 흐음… 재밌는 셀링 방식이네요.
그리고 NYUv2 비교할 때, 3d detection 방법론과 비교를 진행하였는데 비교는 2d detection 성능을 비교한 걸로 보입니다. 흠… 비교가 좀 잘못된 거 같아 아쉽네요
RGB-D 실험에서 입력값을 RGB와 Depth map을 이용한 건가요?
네 맞습니다.
2D 와 3D를 비교한게 아쉽다고 하셨는데 해당부분은 논문에서 명확히 설명하는게 아니라서 정확하지는 않지만, 아마도 2D bbox prediction을 이용해서 3D bbox regression을 한게 아닐까 싶습니다. 바로 direct하게 하면 성능이 많이 안좋을거 같긴한데 디테일한 방법이 설명이 안되어있습니다.