언제나 매주 그래왔듯이 Self-supervised 방식의 깊이 추정 방법론을 또다시 들고오게 되었습니다. Depth estimation은 많은 연구자들이 연구하고 있는 핫한 분야이면서 Self-supervised 는 생각보다 많은 연구가 되고 있지 않은데요. 2019년도의 Monodepth2 이후로는 아직 어떠한 혁신을 이끌만한 연구는 없는 것 같습니다. 혁신은 없지만 그래도 Monodepth2의 설계 아래에서 어떻게하면 조금 더 좋은 성능이 나올지 혹은 어떻게 하면 좋은 형태의 깊이를 추정할지가 모든 연구의 방향성인 것 같습니다. 제가 들고 왔었던 논문들이 다 그렇구요. 이번 논문 또한 그렇습니다. Monodepth2 의 설계 밑에서 inverse depth generator에 어떻게 하면 좋은 정보를 줄 수 있을까에 대한 고찰이 담겨 있고 요즘 정말 다양한 논문에서 사용되고 있는 Self-attention이 들어간 논문 리뷰하도록 하겠습니다.
위에서 소개했듯이 이번 논문은 Monodepth2 기반에 generator를 강화한 논문입니다. 성능을 강화하기 위한 contribution은 다음과 같습니다.
- 다양한 스케일의 RGB 영상의 texture 정보를 학습 시에 전달 해주므로써 예측되는 깊이 영상의 디테일을 살려 성능을 향상 시켰습니다.
- VGG-19 의 feature을 self-attention을 겨쳐서 깊이 영상에 전달해주므로써 semantic한 정보를 강화해주었고 이는 영상의 왜곡에 강인성을 높여주는 효과를 보였다고 합니다.
- 스케일에 강인한 smooth loss를 서계하여 예측되는깊이영상의 semantic정보와 structure를 더욱 살렸다고합니다.
- Method
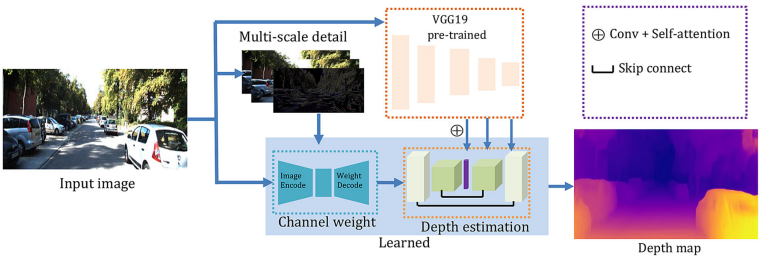
이 논문에서 제안하는 inverse depth generator의 전체 아키텍쳐이다. 두가지의 특징을 볼 수 있는데, Multi-scale detail과 VGG19이다. 그 중 multi-scale detail은 단순히 영상만을 사용하는 것이 아닌 영상의 저주파와 고주파를 adaptive하게 추가하는 것이다.

위 그림 에서 B는 아래 식 1 과 같이 첫 RGB 영상에 bilateral filter를 씌워서 저주파로 만든 것이고 S는 저주파를 통해서 얻는 고주파 성분이다.
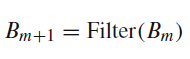
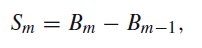
고주파와 저주파는 각각 의미하는 바가 크게 다른데, 고주파 성분은 영상의 texture 정보를 담고 있어 물체의 경계와 같은 부분을 명확히 해줄 수있는 정보이며 저주파 성분은 texture가 없는 영역의 smoothness를 강화해줄 수 있는 역할을 한다.
이러한 추가적인 정보로 활용할 수 있는 영상을 아래 식 3 과 같이 기존 입력 영상과 합쳐서 사용하는데 그냥 합치는 것이 아닌 각 성분의 영상에 학습 파라미터를 추가해 합쳐서 학습을 통해 더억 모델이 원하는 주파수를 adaptive하게 결정할 수 있도록한다.
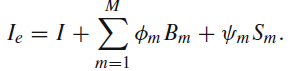
이 와같은 방법으로 생성되는 깊이 영상의 엣지와 smootheness를 강화해주었다.
다음은 vgg19를 이용한 semantic information 추가 이다. 학습을 용이하게 하고 깊이 추정의 기하학적 왜곡을 완화하기 위해 이 방법을 추가했다고 한다. 방법은 그림 1 과 같이 영상을 VGG19에 태운후 그 정보를 기존 Depth estimation model에 추가하는 것이다. 단순히 feature를 더하지는 않고 feature를 conv를 태운 후self-attention 모델에 태운후 decoder feature와 합친다.
마지막으로 기존 Smoothness loss를 변경했다고 한다.
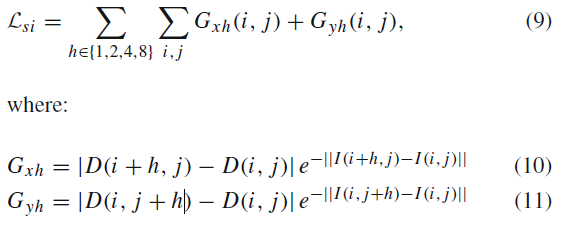
변경된 식이 다음과 같은데, 기존에는 식보다는 보다 직관적으로 식을 구성한 것 같다. 다만 의있이 이걸 짠 것 같지는 않다. (따로 설명이 없음, 결과가 좋다고만 되있다. )
2. Result
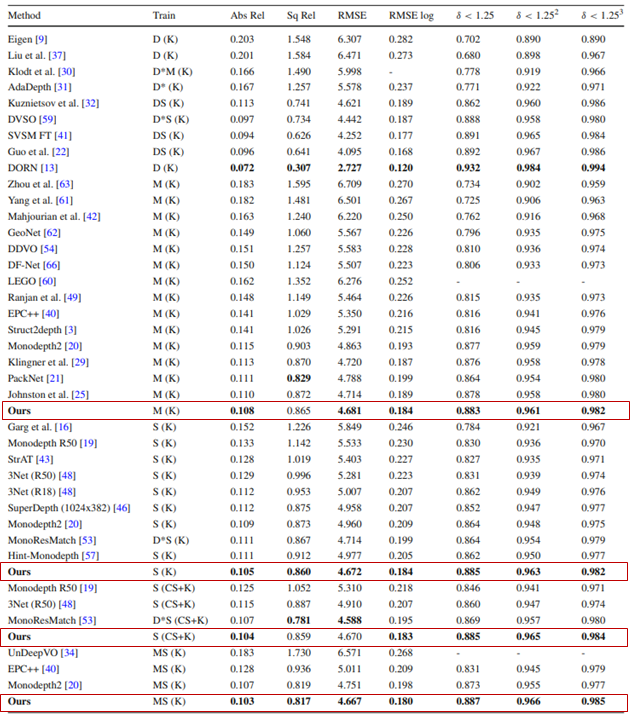
KITTI에서 결과를 보면, 꽤 준수한 성능을 보인다. 하지만 아쉬운 점은 DDV나 Featdepth 와 같은 논문의 성능이 비교가 안됐다는 것 정도가 있겠다.
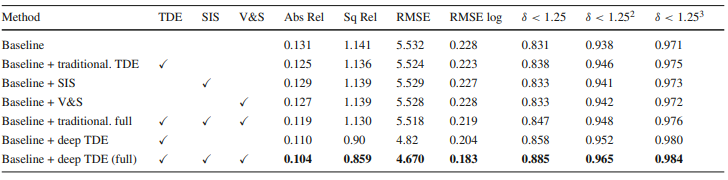
Ablation study인데, 일단 base line을 너무 낮게 잡은게 아닌가 싶다. Monodepth2가 일단 Abs_rel이 0.115가 나오는 상황인데 0.131이 베이스라니.. 크흠…
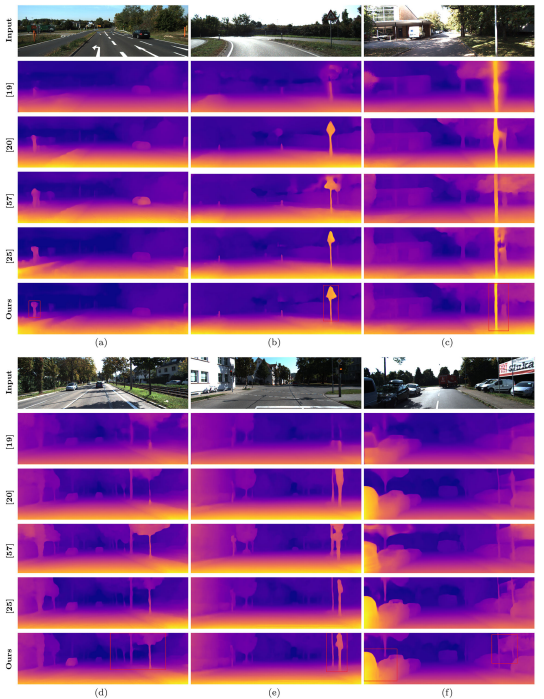
그래도 정성적인 결과를 보면 꽤 sharp 한결과를 내보였다.