해당 논문은 pixel-level로 Contrastive learning을 하는 방식을 제안한다. 기존의 unsupervised learning에서 Contrastive learning은 이미지 전체인 instance level로 이루어지곤 했다. 이러한 학습 방식은 image classification task에서는 유용했지만 pixel level 의 예측을 필요로하는 object detection, semantic segmentation task에 이용하기에 적합하지 않았다. 해당 논문은 pixel-level로 Contrastive learning을 진행하여 object detection, semantic segmentation과 같은 task에 전이학습하였을때 sota를 달성했다.
논문에서는 학습된 모델의 표현력의 종류를 spatial sensitivity 와 spatial smoothness로 분류하였는데, Pixel Contrast는 spatial sensitivity만을 위해 설계되었고, Pixel-to-Propagation Consistency를 통해 두 표현력을 모두 강화시키기 위해 설계되었다. spatial sensitivity란 공간적으로 가까운 픽셀사이의 분별력을 강화시켜 예측 경계를 찾아야 하는 task를 위한 속성이며 spatial smoothness는 같은 label에 속하는 유사 pixel을 더 유사하게 하여 표현력을 높이기 위한 속성이다. 이어서 아키텍처에 대해 encoder와 pixel-contrast, pixel-to-propagation Consistency에 대해 이어 설명하겠다.
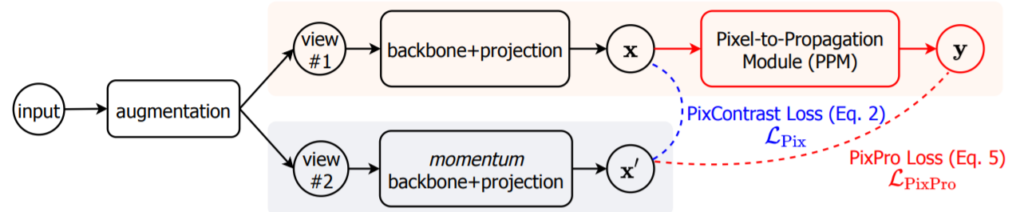
- Encoder
하나의 이미지에서 얻어진 동일한 해상도의 두 views(e.g. 224×224)에 대해서 encoder network를 통해 feature map(e.g. 7×7)을 추출한다. encoder network는 backbone과 projection head로 구성되어있으며 이후 backbone의 output feature가 transfer learning에 사용되는 feature이다.
2. Pixel Contrast
먼저 두 view의 각 픽셀사이 거리를 계산한다. 두 view의 각 픽셀 i,j에 대하여 거리 dist(i,j)는 이미지의 대각선 길이로 정규화된 값이다. 이때 T(타우, 대문자)=0.7. 이로 계산된 값은 픽셀사이의 negative, positive를 구분할 때 사용된다.

이후, contrastive loss를 통해 모델을 학습시킨다. 수식2의 τ(타우, 소문자)=0.3 이다. 수식 1로 정의된 negative, positive를 이용하여 픽셀의 각 feature representation을 contrastive loss로 학습시킨다. (가까운, 동일한 픽셀의 표현력은 유사하게, 먼 픽셀의 표현력은 다르게)
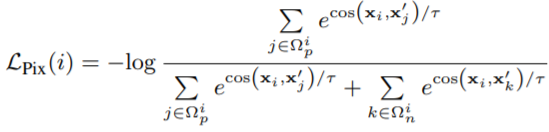
3. Pixel-to-Propagation Consistency
이는 앞서 말했듯이 제안하는 feature가 spatial smoothness에 대한 표현력도 얻기 위해 설계되었다. 이를 위해 먼저 pixel propagation model을 사용하는데 이는 feature를 denoising/smoothing시켜 pixel-level task가 더욱 안정적인 성능을 갖게 한다. 다음으로 비대칭적 아키텍처 설계이다. 그림 2를 보면 확인할 수 있듯이 두 가지 중, 하나의 가지만 pixel-propagation module을 포함하고 있다. 이러한 비대칭적 구조로 negative pair없이 positive pair만으로 학습 할 수 있었다. feature를 denoising 시키는 pixel propagation module (PPM)의 구조는 다음과 같다. x가 입력이며 y가 denosing된 feature이다. g(*)는 1개의 linear layers이며 s(*,*)는 수식 3처럼 정의된다.
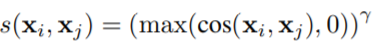

위와같은 방법으로 denoising된 feature y(x의 변환)와 x’는 서로 positive pair로 loss는 다음과 같이 정의된다.
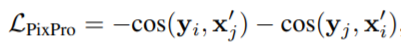
실험으로는 모델의 장점인 여러 downstream network에 전이학습 하는것과 , instance contrast와 결합하여 학습하는 것이다. 먼저 다양한 task에 전이학습의 결과는 다음과 같다. 기존의 instance level의 변형으로 학습한 모델로 feature를 표현하였을 때에 비해 모든 task에 대해 가장 좋은 성능을 달성하여, pixel level task를 위한 좋은 표현력을 지녔음을 예측할 수 있다.
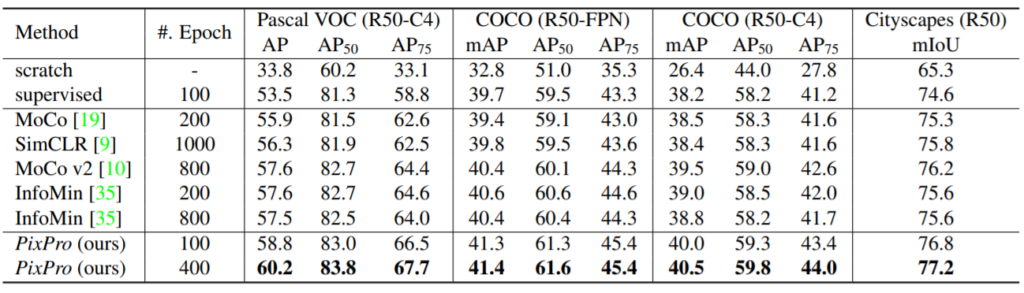
다음으로 instance level method와 함께 적용하여 두 method를 병렬적으로 사용할 수 있음을 보였다.
이 외에도 파라미터에 대한 실험과 pixpro와 pixcontrast 에 대한 비교 실험이 존재한다.
좋은 리뷰 감사합니다. 단계별로 순차적으로 설명해주셔서 이해가 쉬웠습니다. 질문이 하나 았다면 처음 인코더 부분에서의 “ 하나의 이미지에서 얻어진 동일한 해상도의 두 views” 라고 하면 데이터 augmentation을 통해 얻어진 두 개의 이미지가 맞나요?
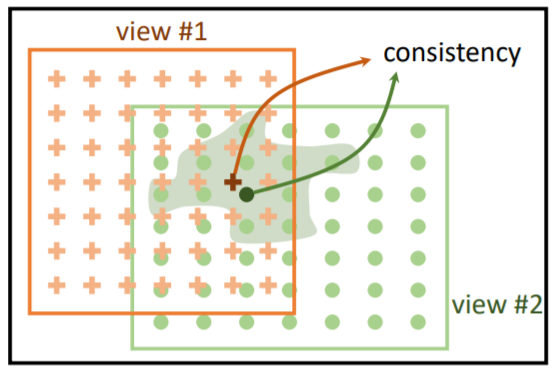
네 맞습니다. 추가 설명 해드리자면, 기존의 instance level의 augmentation을 통해 pair 를 만드는것이 아닌 그림1처럼 한 이미지에서 서로 다른 영역을 가지고 두 view를 생성합니다.