

비디오 연구와 Self-supervised Learning과는 꽤나 연결고리가 있습니다. 연구를 위한 비디오 프레임 수의 경우 적게는 백 장부터 많게는 몇 만장까지 대용량의 데이터를 포함하고 있어 Labeled 데이터를 얻기도 힘들고, Labeling 과정에도 많은 cost가 들게 됩니다. 이때문에 비디오 연구에서 다루는 주제들 중 Unlabeled 데이터를 활용하기 위한 Self-supervised Learning이라는 키워드가 많은 주목을 받고 있습니다. 오늘 리뷰할 논문도 마찬가지로 비디오에서 Self-supervised Learning에 대한 키워드로 연구해, Unlabeled 비디오에서 Label을 얻어내는 방법론 SeLaVi를 소개한 논문입니다.
1. Method

해당 논문에서 해결하고자하는 Unlabeled 비디오에서 Label을 얻어내는 과정은 결국 입력 비디오 x에 대한 labeling function을 찾아내는 것과 같습니다. 이를 찾아내기 위해 본 논문에서는 labeling function이 만족시켜야하는 두 가지 조건을 선정하였습니다. 첫 번째는 어떤 semantic content에 대해 인간의 관점에서 labeling 되어야 한다는 것입니다. 인간의 관점이라는 것은 결국 모든 class가 동일하지 않을 것이며, 이는 Zipf distribution을 따를 것이라고 합니다. Zipf distribution이란 어떤 class가 등장하는 빈도에 따라 나열하였을 때 각 class의 등장 빈도는 순위에 반비례하는 것을 의미하며, 많은 물리 및 사회 과학 분야에서 이와 비슷한 분포를 보인다고 합니다. 이와 같은 조건에 부합하고자 GT Label을 알고 있다는 가정하에 생성된 label을 평가하였다고 합니다. 두 번째는 모든 modality가 주는 정보량이 동일하기 때문에 multi-modal로 문제를 해결하고자 하였다는 것 입니다. 해당 조건 하에 본 논문에서는 비디오에서 visual stream과 audio stream을 동시에 사용하였다고 합니다.
Non-degenerate clustering via optimal transport & Clustering
본 논문에서는 해당 저자가 이전 이미지에서 Labeling을 하기 위해 제안했던 논문 SeLa의 optimal transport 개념을 그대로 가져와 사용합니다. 찾고자하는 labeling function을 y, 입력 데이터 x에서 feature를 추출하는 모델을 Ψ라고 한다면 y(Ψ(x))가 labeling을 얻기 위한 과정을 나타내게 됩니다. 여기서 labeling 과정은 unsupervised-learning으로 풀고자 하기 때문에 clustering 과정으로 풀고자 하며, 전통적인 clustering 알고리즘 들은 clustering function Y의 최적 값을 알아내기 위해 energy function E(Y)를 최적화 하려고 합니다. 이와 같이 적용하면 최적의 labeling function을 얻기 위해서는 E(y, Ψ)를 최적화 하여야합니다. 그러나 단순히 y, Ψ를 각각 최적화하게 된다면, unbalance solution에 빠지게 되기에 해당 저자는 SeLa에서 하였던 것처럼 marginal probability distributions의 제한을 각 cluster 별로 적용하여 Sinkhorn-Knopp 알고리즘으로 optimal transport 문제를 해결하였고, 이 과정에서 최적의 permutation matrix 나타내는 class를 clustering 하였다고 합니다. (Sinkhorn-Knopp 알고리즘의 최적화 과정은 SeLa를 참고 부탁 드립니다. 완벽히 이해를 하지는 못했습니다..) 이후, Clustering된 label을 Self-label로 backbone network Ψ에 주어 학습 시키게 됩니다. 여기서 Self-label을 만들어 가는 과정은 training이 진행되지 않으며 만들어진 Self-label을 활용해 backbone network에 주는 과정은 학습 과정으로 backbone network를 갱신 시킵니다.
2. Experiments
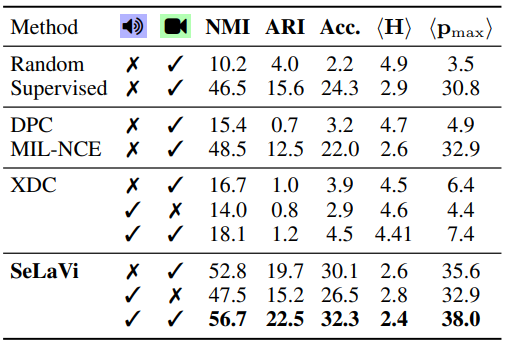
Tabel 1에서 NMI는 Noarmalized Mutual Information의 약자로 Self-Label과 GT Label 간의 Correlation을 판단하는 지표를 의미합니다. 0에서 100으로 갈수록 동일하다는 것을 나타냅니다. ARI는 Adjucted Rand Index의 약자로 Clustering 과정을 평가하기 위한 지표이며, <H>는 Self-Label과 GT Label간의 Entropy를 나타내는 Mean Entropy 지표 이고, <p_{max}>는 Cluster의 quality를 측정하기 위한 Mean Maximal Purity라는 지표 입니다.
제안된 SeLaVi에서는 실제 GT Label과 유사도를 판단한 NMI 지표에서 다른 방법론들에 비해 보다 유사한 점을 보였습니다. 이를 통해 첫번째 가정이었던 인간 관점의 Labeling이 진행되었다는 것을 증명할 수 있었습니다. 또한 제안된 SeLaVi의 경우 visual stream 혹은 audio stream 둘 중 하나만 쓴 것보다 둘 다 썻을 때 성능이 더 좋은 모습을 보여주었다고 합니다. 그리고 해당 논문의 두번째 가정인 모든 정보가 주는 정보량이 동일하다는 것도 visual or audio stream을 각각 썻을 때 Supervised 방식보다 성능이 높은 것으로 증명해내었습니다.
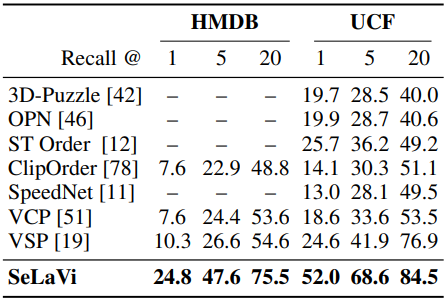
Table 2는 제안된 SeLaVi를 Retrieval task에서 평가한 성능 입니다. Recall@k는 k개의 상위 후보들 내에 하나라도 GT에 해당하는 값이 있으면 1 아니면 0인 평가지표이며, 제안된 SeLaVi가 다른 방법론들 대비 Recall@k의 값이 큰 폭으로 높은 것을 볼 때, 보다 질적인 Self-Label을 생성하고 있다는 것을 의미합니다.
3. Reference
[1] https://proceedings.neurips.cc/paper/2020/file/31fefc0e570cb3860f2a6d4b38c6490d-Paper.pdf
좋은 리뷰 감사합니다. NMI 지표 성능으로 인간 관점의 Labeling이 진행되었다는 것을 증명하였다는 것은 GT labeling을 사람이 진행했기 때문인가요? 인간 관점의 labeling이란 무엇인지 알고싶습니다. 감사합니다
인간 관점의 labeling은 class 별 labeling 빈도가 uniform 하지 못한 distribution을 갖는 것을 의미합니다. 이는 Zipf distribution을 통해 널리 알려져있고 본 논문에서 목적으로 두고 있는 것도 균일한 분포의 balanced labeling이 아닌 마치 인간이 labeling 한 것 같은 unbalanced label을 얻고자하기에, 생성된 Self-label과 기존 인간이 제공한 GT label간의 correlation을 판단하기 위한 NMI 지표를 도입하였습니다.
zipf dist : https://ko.wikipedia.org/wiki/%EC%A7%80%ED%94%84%EC%9D%98_%EB%B2%95%EC%B9%99