Towards Diverse and Robust High-level Scene Understanding (권인소 교수님)
컴퓨터 비전의 초기에 사람의 시각적 인지에 대한 연구를 통해 시각적 인지에 영향을 미치는 세 가지가 제시되었다.

우선 같은 양의 정보라 해도 Local Visual Properties에 따라 object를 인지할 수 있는 지가 결정된다.

하지만 일부분의 시각적 패턴만 이용한다면 제대로 장면을 이해하지 못할 수 있다. 따라서 contextual relations이 인간의 시각 시스템에서 중요하게 작동한다.
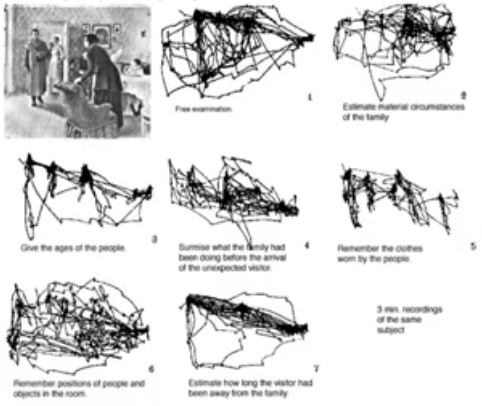
마지막으로 질문에 따라 사람이 장면에서 집중하는 것이 달라진다는 Figure-Ground understanding이다.
CBAM을 이용해 local visual properties에 attention을 주었다. 이때 local한 정보 뿐만 아니라 global한 정보도 함께 사용할 수 있도록 제안하였고 CBAM 모듈을 추가하면 더 정확하게 attention을 할 수있다. 하지만 contextual relation을 찾기는 어려웠다. 이를 해결하기 위해 relational captioning을 제안하게 되었다.
contextual relations을 모델링하고 학습하여 주변과 객체의 관계를 이해해 주변의 객체와 해당 객체애 대한 인식 정확도를 높였다. scene graph를 모델링하고 학습하여 relation classification문제로 접근하여 LinkNet을 제안하였다. 해당 방법론은 self-attention을 통해 relational embedding을 하였고, global contextual information 이용하기 위해 global context encoding을 하였다. 또한 geometric layout encoding으로 상하, 좌우, 어디 위에 있다와 같은 정보를포함시켰다. 이러한 방식은 bench mark 데이터에서 잘 작동하였고 Visual Genome dataset(VG)에서 SOTA를 달성하였다. 하지만 VRD (vision과 language를 결합하여 이용하는 방법론)에서 language를 이용하였음에도 recall이 낮았고 이 이유에 대해 밝히기 위해 연구를 진행하였다.
분석 결과 image captioning을 하면 더 다양한 attribution을 가진 표현을 얻을 수 있어 개선이 이뤄지기는 하나 많이 좋아지지는 않았다. 영상에 있는 다양한 정보를 활용하기 위해 fine-granined detail을 뽑아내기 위해 multiple sentences를 찾아내고 그 사이에 adaptive한 관계를 스스로 찾아내고 grounding시킬 수 있도록 하기 위해 MTTSNet을 제안하였다. 이를 통해 다양하고 정확한 caption을 얻을 수 있는 Dense Relational Captioning이라는 work를 제안하였다.
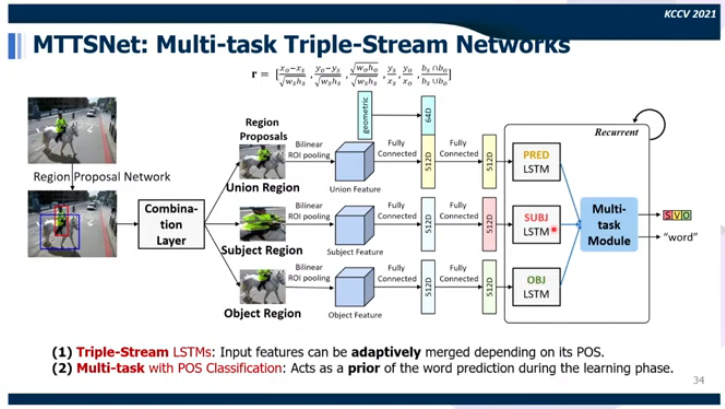
union, 주어, 목적어로 나뉘는 언어의 특성을 이용하여 모델링 하였다. 연관있는 geometric 정보를 알기 위해 만든 embeding feature vector와 각 feature들을 concat하여 remapping을 하였다. 이를 통해 union region에서는 relation을 학습하고 subject, object region에서 각각에 대한 학습이 이뤄졌다. 이후 multi-task module을 통과시켜 language의 구조와 word-level의 prediction을 얻었다. relational captioning에 사용할 dataset이 없었고 dataset을 얻기 위해 Visual Genome의 relationship dataset에 있는 attribute 정보(각 object에 대한 상세 정보)를 이용하여 relational captioning dataset을 만들어 사용하였다.

실험 결과 좋은 성능을 얻기는 했으나 학습에서 사용된 relation 정보에 한정된다는 generalization issue를 가지고 있었다. 또한 이미지당 필요한 sentence들을 얻기 어렵다는 data hungry issue도 있었다. 이를 해결하기 위해 이미지와 sentance를 따로 모아 만든 unpaired caption data를 이용하여 Semi-supervised 방식으로 학습하는 방식을 고안하였다.
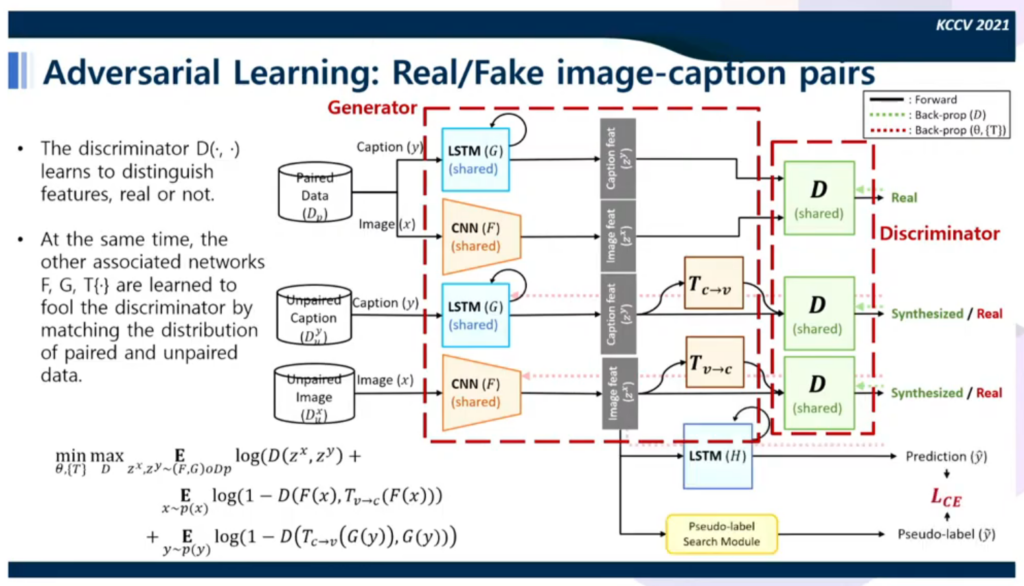
unpaired caption 데이터가 들어오면 대응하는 image를 생성해 discriminator가 구별하기 어렵도록 학습하고, unpaired image가 들어오면 caption을 예측하도록 하여 real과 fake를 구별하도록 학습시켰다. 그 결과 1%의 paired data를 이용해도 높은 수준의 성능을 얻었다.
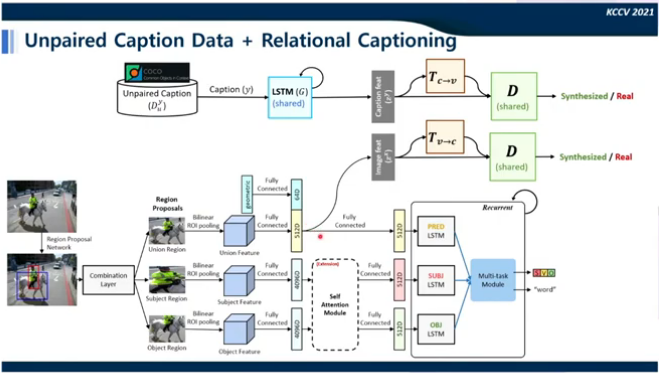
이후 unpaired dataset을 이용하는 방식과 relational captioning 모델을 결합하였고 이를 통해 더 높은 성능을 달성하으며 알려주지 않은 caption을 unpaired text로부터 학습하여 예측에 사용하였다. 이러한 방식을 다시 object detection과 결합하였고 이를 통해 contextual한 정보를 이용하여 detection을 할 수 있다는 것을 확인하였다.

결과가 정말 contextual 정보를 이용한 것인지 확인하기 위해 self-attention을 보았고 그 결과 예를 들어케이크에 대한 detection이 이루어질 때 접시로부터 케이크를 연관지어 예측해낸 것임을 확인할 수 있었다.
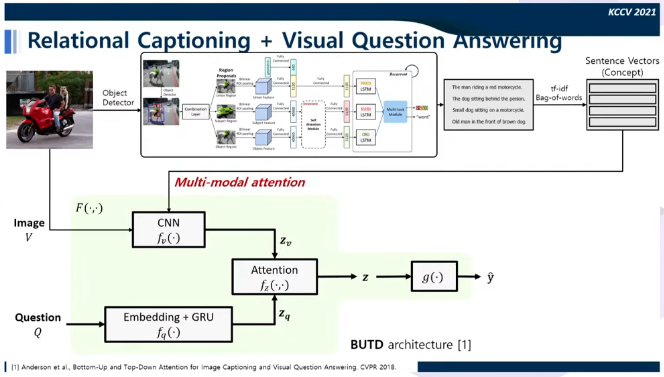
이후 Figure-Ground understanding을 위해 기존의 VQA 모델과 relational captioning을 융합하여 실험하였고 그 결과 기존 모델에서 틀렸던 질문에 답을 맞췄고 attention을 이용해 확인한 결과 적절한 곳을 보고 적절한 대답을 한 것을 확인할 수 있었다.

++ 좋은 발표가 많았지만 해당 발표가 기억에 남는 이유는 새롭게 문제를 디자인하고 연구가 이루어진 과정에 대해 알 수 있었다는 것과 인간의 시각 시스템에 대한 분석이 인상 깊었기 때문입니다. 문제를 정의하고 해결하고 다시 분석을 통해 문제를 정의하는 연속된 과정을 다시 확인할 수 있었고 분석의 중요성에 대해 다시 생각해볼 수 있었습니다.
느낀 점
이번의 학회 참가는 새롭고 값진 경험이었습니다. 낯선 분야와 용어가 많아 모든 내용을 이해할 수는 없었지만 연구실에서 연구 중인 분야 외에도 다양한 분야에 대해 접해보고 어떤 연구가 이루어지고 있는 알 수 있어서 좋았습니다. 그리고 다양한 형태(형태 혹은 목표) 발표를 접해볼 수 있어서 좋은 경험이었습니다. 학회는 발표자 분들의 연구,혹은 논문에 대한 내용 발표라고만 생각하고 있었습니다. 논문에 대한 설명에 초점을 둔 발표도 있고 어떠한 흐름으로 연구가 이루어졌고 있고, 어떤 연구가 이뤄지고 있는 지를 설명한 발표도 있었습니다. 학회란 어떤 것이고, 연구 내용을 교류한다는 것이 어떤 의미인지 조금은 이해할 수 있었습니다.
아쉬운 점도 있었습니다. 학회에 참여하기 전에 관심이 있는 발표들의 논문 등을 미리 읽어보면 도움이 될 것이라는 연구실 선배님들의 충고에도 여러가지 일을 핑계로 미루다 발표를 듣게 되어 한번에 이해하지 못하고 나중에 다시 보느라 오히려 시간이 더 들었던 것 같습니다. 이번 학회가 온라인으로 진행되었고 스트리밍 영상을 제공해 주었기 때문에 발표를 다시 볼 수 있었던 것이 정말 다행이라 생각합니다. 다음에는 관심있는 내용에 대해서는 디테일하게 모든 것을 이해하지는 못하더라도 대략적인 내용은 우선 파악하고 참여할 수 있도록 해야겠다고 다짐했습니다.
그리고 영어 발표는 놓친 게 너무 많아서 아쉬웠습니다. 틈이 날 때 마다 영어 공부를 할 게 아니라 일주일에 정해진 시간을 정해진 시간마다 해야겠다고 느꼈습니다.