저는 지난 학기동안 캡스톤에서 얼굴 이미지로 체중 변화를 알아내는 것에 대해 알아보았습니다. 저희가 얼굴 이미지로 체중 변화를 어떻게 예측하였는지 간단하게 설명하자면 그 과정은 다음과 같습니다: (1) 서로 다른 시간에 촬영된 두 개의 얼굴 이미지에서 3D Face Landmark 를 추출 (2) 추출한 두 랜드마크를 비교하여 체중 변화 여부를 예측

방법 (1)에서 사용된 3D Face Landmark 추출에는 mediapipe가 제공하는 face mesh 라는 툴을 사용하였습니다. face mesh 는 일반 2D 얼굴 이미지를 넣으면 face landmark 를 각 부위의 상대적 깊이정보가 반영된 3D mesh(그물망) 형태로 반환한다고 하여 mesh 라고 합니다. 그러나 mediapipe 에서는 landmark 추출에 사용되는 모델의 상세한 정보를 공개하지 않았기에, 구체적으로 어떻게 추출하는지에 대해서는 알 수 없었습니다. 따라서 이번 기회에 2D 그리고 3D face lanㅁdmark 를 비롯하여 관련 데이터셋까지 알아보기 위해 논문을 읽어보았습니다.
How far are we from solving the 2D & 3D Face Alignment problem? (and a dataset of 230,000 3D facial landmarks) – [ 바로가기 ]

Contribution
- 2017년 기준 2D Face Alignment SOTA 아키텍처와 SOTA Residual 블록을 결합하여 매우 strong 한 Baseline 구축 및 합성된 대규모 2D facial landmark 데이터셋으로 train 후 평가
- 3D face alignment dataset 의 부족함을 극복하기 위해, 2D 랜드마크를 3D로 변환하도록 현존하는 모든 데이터를 통합하여 얻은 가장 크고 가장 challenging 한 3D face landmark dataset(약 23만 이미지)인 LS3D-W를 만드는 가이드(2D-to-3D-CNN) 제안
- 3D Face Alignment 를 위한 train 및 새롭게 만든 LS3D-W 데이터셋에 대한 평가
- large pose, 초기화 및 해상도와 같은 face alignment 성능에 영향을 미치는 모든 “전통적인” 요인들이 어떤 영향을 미치는지 살펴보고 “새로운” 요인인 네트워크의 크기에 대해 소개
- 2D 그리고 3D face alignment 네트워크가 saturating에 가까운 정확도를 달성
Introduction
당시 heatmap 기반의 CNN 방법론이 pose estimation task 에 큰 성능을 가져왔고, 그와 동시에 end-to-end 학습이 가능해졌습니다. 본 논문에서는 heatmap 을 사용한 방법론을 face alignment 에 적용하기 위한 네트워크 구축 및 학습방법에 대해 제시하고, 기존의 모든 2D 데이터셋과 새로 도입된 대규모 3D 데이터셋에서 포화 상태에 가까운 성능을 얻으려면 얼마나 걸릴지 처음으로 알아보았다고 합니다.
아래 영상은 해당 방법론을 적용한 결과입니다. 본 논문이 해결하고자하는 문제가 무엇인지 직접적으로 이해할 수 있을 것 같아 첨부합니다.
Method
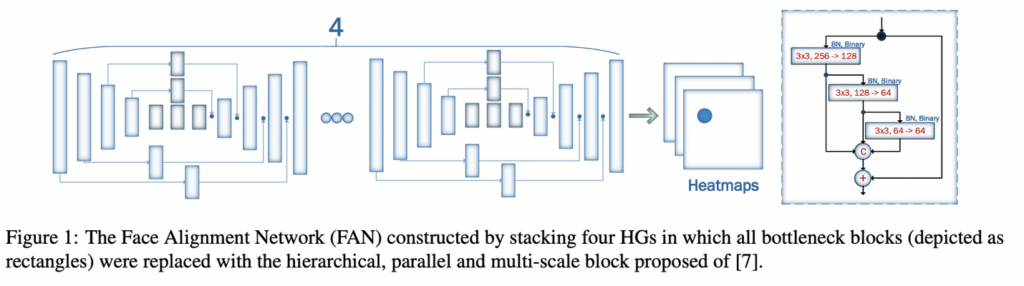
본 논문에서 제안하는 모델인 Face Alignment Network (FAN)은 introduction에서도 언급하였듯, pose estimation에서 주로 사용되는 backbone인 heatmap 기반으로 구성됩니다. 그렇기 때문에 pose estimation의 SOTA 중 하나인 Hour Glass (HG) 네트워크를 그림 1과 같이 4개를 연달아 놓이는 구조를 가집니다.
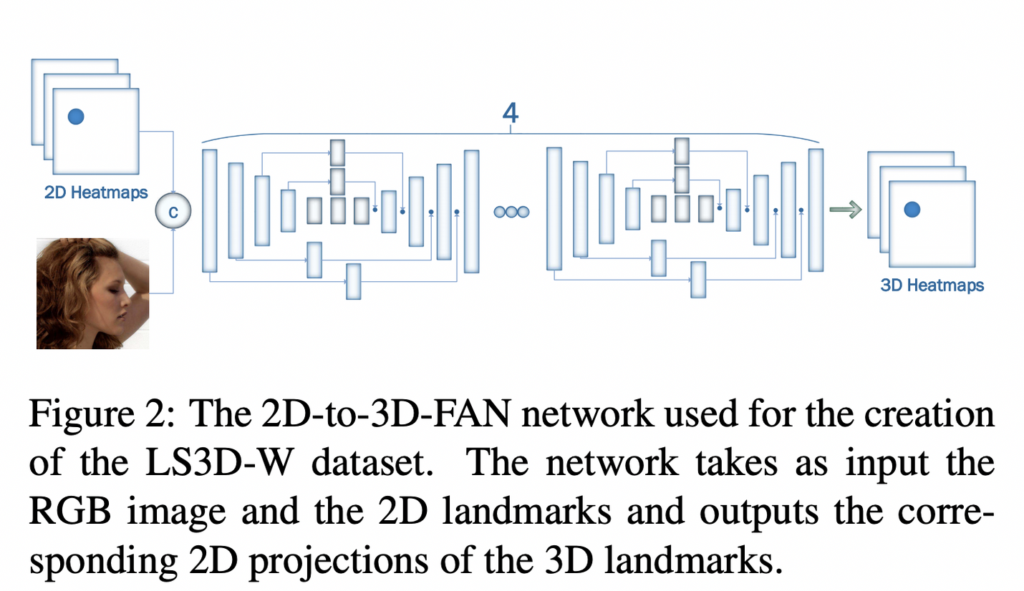
이 논문의 contribution 중 하나는 바로 초대형 3D 데이터셋 LS3D-W 구축입니다. 부족한 3D face landmark 데이터셋 구축을 위해 2D 랜드마크에서 3D 를 예측하는 네트워크를 제안하였는데요 그것이 바로 “2D-to-3D-FAN” 입니다. 2D 이미지의 랜드마크가 주어지면 해당 네트워크는 2D 랜드마크를 3d 로 변환합니다. 이 네트워크를 학습하기 위해 동일한 이미지에 대한 2D, 3D GT가 있는 300W-LP를 사용합니다.
2D face alignment
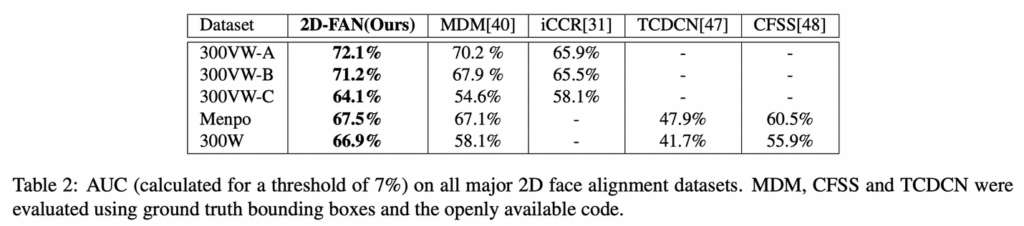
300-W-LP2D 데이터셋으로 학습한 2D-FAN을 300-W test set, 300-VW 그리고 Menpo (frontal subset)으로 평가하며 총 평가 데이터의 개수는 대략 22만개 이상입니다.
평가에 앞서 알아둬야할 데이터셋 특징은 다음과 같습니다:
- 300-W-LP-2D 데이터셋은 다양한 각도가 포함되지만, 300-W 전면 이미지를 합성하여 만든 각도기 때문에, 리얼 데이터 부족 문제는 여전히 존재
- 2D-FAN이 학습된 300-W-LP-2D의 2D 랜드마크는 테스트 데이터셋의 랜드마크와는 조금 다르다는 문제 (이로 인해 300W 트레이닝 셋으로 fine-tunning 했지만 본질적인 해결책은 아님)
- 지난 몇년간 LFPW 정면 데이터셋에 대한 성능 개선이 거의 없기 때문에 가장 최신 방법론인 MDM이 LFPW를 saturate 한다고 가정.

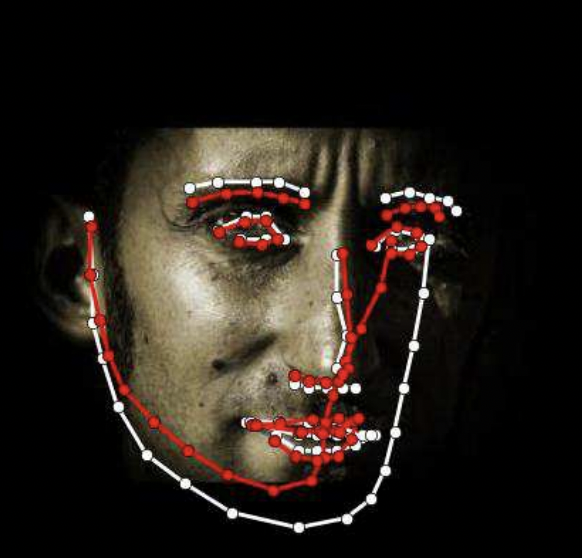
해당 그림의 빨간색 랜드마크가 GT, 그리고 하얀색 랜드마크가 FAN의 예측 결과입니다.
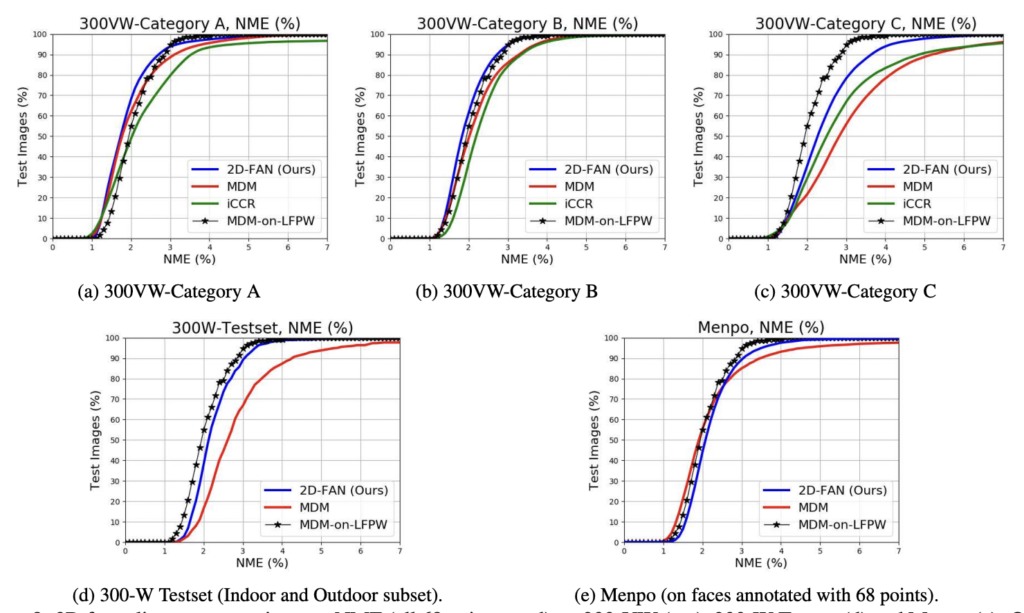
위 곡선이 바로 2D 실험에 대한 cumulative error curves입니다. 300-VW의 C를 제외하고, 2D-FAN은 모든 데이터셋에서 문자 그대로 동일한 성능을 달성하며, MDM 및 ICCR 를 뛰어넘으며, 특히 MDM-on-LFPW의 성능과 일치합니다. 여기서 300-VW의 Category C에 대해, 성능 저하의 주된 원인이 반자동 방식의 annotation 으로 인해서 다시말해 GT가 잘못됐기 때문이라고 합니다.
결론: 2D-FAN이 MDM-on-LFPW의 성능과 일치한다는 점을 고려하여, 2D 데이터셋에서 거의 포화 상태에 가까운 성능을 달성한다고 할 수 있음. (성능 저하는 GT 가 잘못된 것이다…)
Large Scale 3D Faces in-the-Wild dataset
앞서 2D-to-3D-FAN을 통한 대규모 데이터셋을 구축했다고 언급하였습니다. 그러나 2D-to-3D 평가는 pair 한 GT 가 부재하기 때문에 어렵습니다. 그나마 wild 한 데이터셋에서 사용가능한 3D 랜드마크 GT는 AFLW2000-3D 뿐입니다. 따라서 데이터셋 AFLW2000-3D에 2D-to-3D-FAN을 태운 뒤, 아래 그림 5에 나타난 오류를 계산하였다고 합니다. (이 때, normalization을 위해 bbox가 사용됩니다) 그 결과, 몇 개의 이미지에 대한 불 일치가 있었지만 그 불일치 역시 GT가 잘못된 것이었다고 합니다. 아래 그림 6이 바로 불일치가 높은 (에러가 높은/GT가 잘못된) 이미지들을 나타낸 것입니다
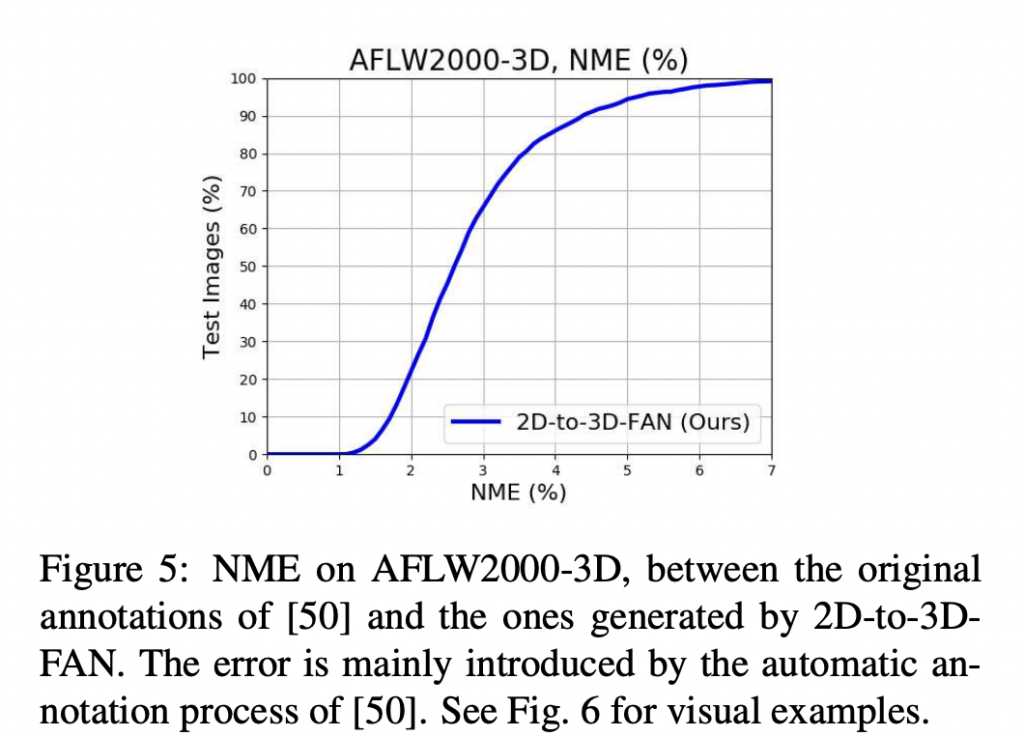

따라서 300-W의 테스트셋, 300-VW, 그리고 Menpo에 대한 2D-to-3D-FAN으로 발생한 3D 랜드마크와 AFLW2000-3D를 포함하여 총 23만 개의 이미지에 3D 랜드마크 GT가 있는 논문이 쓰여진 당시까지 가장 큰 3D face in the wild datasetLS3D-W)을 만들 수 있습니다.
3D face alignment
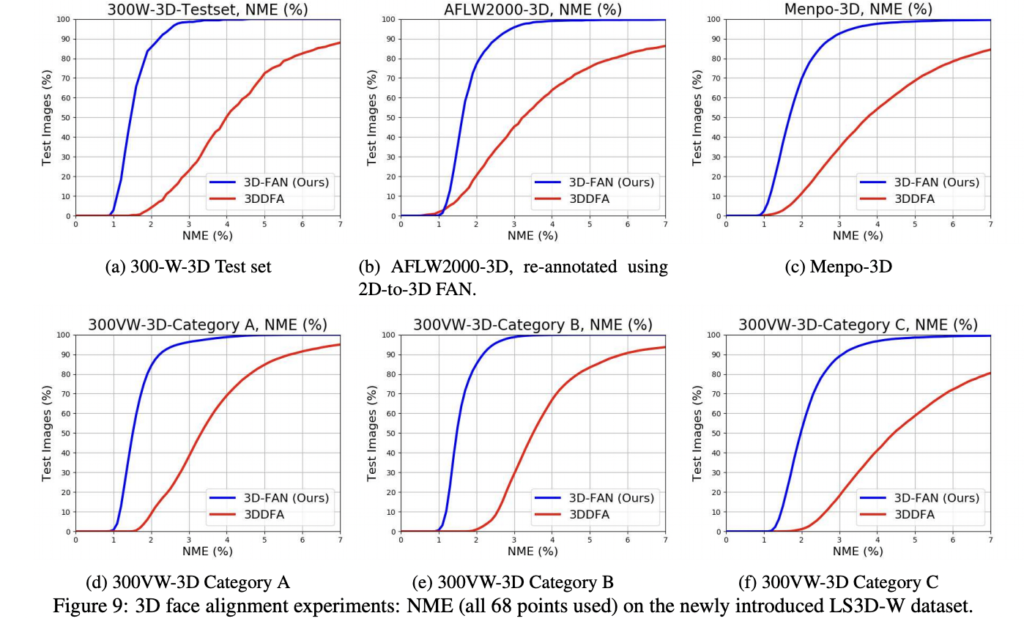
300-W-LP3D으로 학습된 3D-FAN을 앞 장에서 만든 LS3D-W로 평가한 결과입니다. 2D 와 비교했ㅇ르 때, 보다 더 large pose 를 가진 이미지가 사용됩니다. 그 결과는 그림 9와 같습니다.
3D-FAN은 기본적으로 3DDFA를 크게 능가하는 모든 데이터셋에서 거의 동일한 정확도를 달성합니다. 이 accuracy는 2D-FAN이 달성한 정확도에 비해 약간 높아졌다고 합니다.
Dataset
3D annotation은 2D annotation이 아닌 pose 전반에 걸친 내용이 포함되기 때문에 더 선호된다고 합니다. 여기서 pose 란 각도라고 생각하면 이해하기 좋을 것 같습니다.
Training Dataset
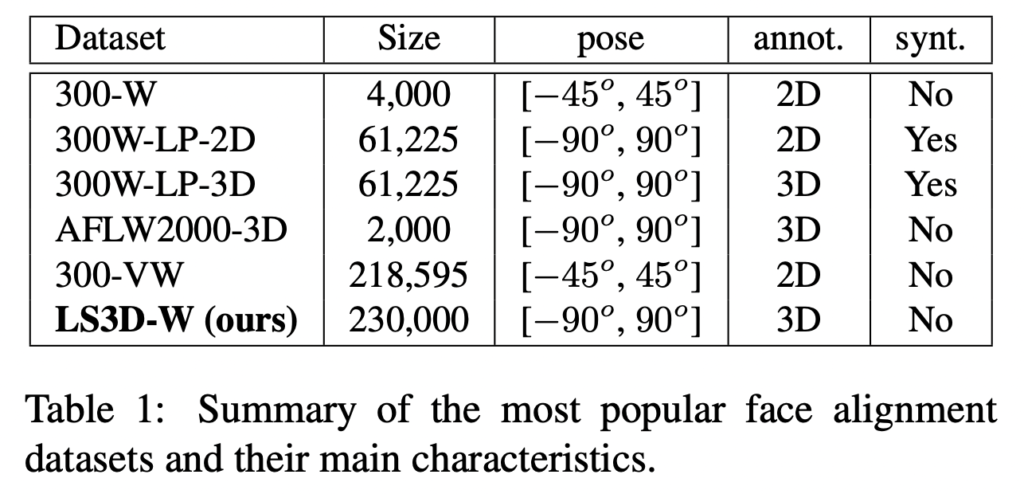
- 300-W-LP는 300-W를 가공하여 확장한 데이터셋으로 이를 train에 사용했다고 합니다. 해당 데이터는 2D와 3D landmark를 모두 제공하여 두 가지 실험이 가능하다고 합니다.
- 300W-LP-2D 그리고 300W-LP-3D 는 300-W를 더 큰 각도(-90 ~ 90도) 로 합성하여 만든 데이터셋이고, 61,225개의 2D-3D 랜드마크 annotation이 존재
Test Dataset
- 2D datasets
- 300W test set. 300-W Challenge의 평가목적으로 사용되는 600개의 이미지로 구성. 실내와 야외 이미지로 구성되며 모든 이미지에는 68개 점의 2D 랜드마크 annotation 존재
- 300VW. 114개의 비디오와 총 218,595개의 프레임을 포함하는 대규모 face tracking dataset. 테스트 영상은 세 가지 카테고리(A, B, C)로 구분되며, 마지막 카테고리(C)가 가장 까다로움. 예를 들어 매우 낮은해상도 혹은 화질이 안좋은 얼굴이 포함되어 있음. 반자동 annotation 방법으로 인해 annotation에 대한 정확도는 떨어짐. 그리고 다양한 포즈에 대한 annotation 부제 역시 정확도 저하의 원인 중 하나
- Menpo. FDDB와 ALFW의 약 9000 얼굴에 대한 랜드마크가 포함된 데이터셋. 정면 얼굴은 300-W와 동일하게 68개의 점을 가진 2D 랜드마크지만, 측면에는 39개의 점을 가진 랜드마크 annotation 이 있음
- 3D datasets
- AFLW2000-3D. AFLW 데이터셋 중 처음 2000개의 이미지를 300W-LP-3D 와 동일한 방식으로 re-annotation을 진행하여 구성한 68 개의 점을 가진 3D 랜드마크 데이터셋. 해당 데이터셋은 다양한 각도 및 표정, 그리고 조명을 가진다는 특징이 있지만, 각도가 크거나 가려진 얼굴의 경우 일부 annotatoin 이 정확하지 않음 (아래 그림 빨간색 랜드마크가 바로 해당 GT )
Metric
기존에 face alignment 에 사용되던 지표는 정규화된 랜드마크에 대한 point-to-point 유클리드 거리였습니다. 그러나 이 평가 메트릭은 눈 사이 거리가 매우 작을 수 있는 측면 얼굴에는 적합하지 않기에, 다음과 같은 NME를 사용.
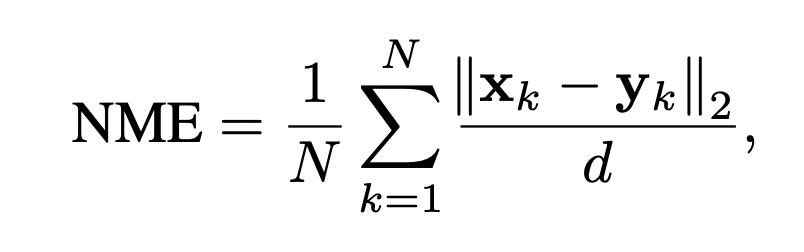
여기서 x 는 GT, y는 예측값, 그리고 d는 GT bbox의 square-root (즉, 루트(w*h))입니다. 2D 그리고 3D 모두 동일한 bbox를 정의하여 사용하였기 때문에 정확도를 쉽게 비교 가능.
아무래도 이번주에는 논문 선정에 심혈을 기울이다보니 정작 리뷰할 수 있는 시간이 줄어들었던 것 같습니다. 따라서 너무 겉핥기로 본 논문을 리뷰한 것 같은데, 평일 중에 다시 한번 디테일한 정보를 캐치한 후, 제가 궁극적으로 해결하고자 하는 랜드마크 간 비교를 다룬 논문이 있는지 찾아보고자합니다. 어설픈 리뷰였습니다. 읽어주셔서 감사합니다.