이전 리뷰에서 사람의 키포인트를 이용한 3차원 위치 인식 방법론들에 대해 소개하였습니다. 사실 이전에 소개드린 방법론들에는 치명적인 단점이 있습니다. 입력 값으로 사용되는 Human Pose Estimation(HPE)의 성능에 큰 영향을 받는다는 점입니다. 이번 리뷰부터 치명적인 단점을 극복하기 위해 차근차근 HPE의 핵심 논문들을 리뷰할 예정입니다.
DeepPose는 딥러닝 기반의 HPE를 처음 제안한 방법론입니다. 방법론 자체는 매우 간단한 형태를 가집니다. 하지만 매우 단순한 접근으로 Top-Down 같이 많은 연산량이 필요한 방법론에서 사용되는 방법론에서도 인용되어 사용되기도 합니다. 하지만 제안한 방법론에서는 각 관절마다 개별적으로 예측하는 모델을 둔다는 단점이 있습니다. 이는 이후 Mask-RCNN에서 단일 모델로 예측하는 방법으로 개선되어 제안됩니다.
++ Top-down : 사람을 찾은 후~(bbox), single human pose estimation을 수행
++ Bottom-up : 영상 내, 모든 사람들의 키포인트를 추출 후, 키포인트간 연관성을 추론
Intro

HPE는 딥러닝 이전에 몇 가지 풀기 어려운 문제가 있었습니다. 대표적인 예시로 Fig 1이 해당합니다. Fig 1의 왼쪽 사람의 양쪽 팔은 몸통에 가려져 있지만, 우리는 감각적을 어느 위치에 있는지 파악이 가능합니다. 이와 동일하게 오른쪽 사람의 왼쪽 몸통이 어떤 식으로 구성되어 있는지 유추가 가능합니다. 이처럼 이전의 머신러닝에서는 가려짐 문제로 인해 어려움을 가지고 있었습니다. 하지만 AlexNet(2012)이 등장함으로써 사람과 유사하게 전체적 문맥을 이해할 수 있다는 가능성을 보였습니다. 대단하게도 저자는 이런 흐름을 빠르게 읽고 HPE에 CNN을 적용함으로써 가려짐 문제를 해결하고자 하였습니다.
Method
제안한 방법에서는 각 pose keypoint들의 일반화된 표현을 위해 bbox에 맞혀 정규화된 pose vector로 만들어주는 작업을 합니다. 이는 영상의 일부분만 보는 경우에도 절대적인 위치를 표현할 수 있다는 장점이 있습니다. 이는 아래의 수식으로 표현됩니다.
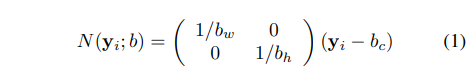
b는 bbox의 좌표 값에 해당하며, b_w, b_h, b_c는 bbox의 width, height, center에 해당합니다. y_i는 i번째 pose keypoint y에 해당합니다.
++ bbox에 맞게 pose vector를 정규화하는 방법은 추후, 각 관절에 해당하는 부분을 다시 예측할 때, 유용하게 사용됩니다. 또한 다른 Top-down 방법론에서도 유용하게 사용됩니다.
Pose Estimation as DNN-based Regression
DeepPose는 AlexNet을 이용합니다(VGG가 2014년에 처음 제안됨). 최초 입력 영상은 220×220으로 resize되어 입력되어집니다. 출력 값은 pose vector를 예측합니다. 각 값들은 정규화된 GT pose vector와 L2 loss를 이용하여 최적화됩니다. 각 모델들은 learning rate : 0.0005, Batch size : 128, DropOut : 0.6을 사용하여 학습됩니다 .
해당 방법론만의 제안은 여기서부터 시작됩니다.
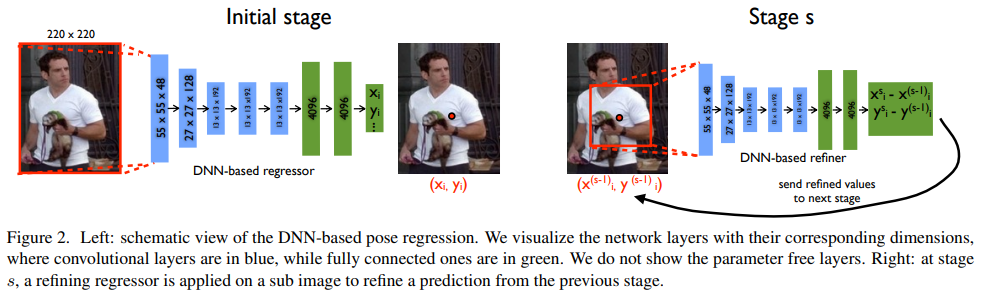
단순하게 CNN을 이용한 pose 회귀 문제로 해석하는 것이 아니라 coarse-fine grained 방법을 제안합니다. Initial stage에서는 coarse하게 모든 key vector에 대해 예측을 합니다. 하지만 이럴 경우 영상의 부분을 보지 못하는 비효율적인 연산이 수행됩니다. 저자는 이를 해결하기 위해 각 부위에 대한 bbox를 예측하고 bbox에 해당 부분만 이용하여, 즉 특정 부위에 대한 CNN을 이용한 pose 회귀 문제로 풀이합니다.
앞서 설명드린바와 같이 DeepPose는 여러 stage들로 구성됩니다. 각 stage에 대한 설명은 Fig 2에서도 확인이 가능합니다. 각각의 stage들은 위에서 소개한 동일한 모델을 이용하며, 개별적인 파라미터를 가집니다.(별도로 학습한다는 이야기) 또한 예측된 관절을 기반으로 하여 자른 영상을 입력으로 사용합니다. 이를 통해 각 부위에 대해 보다 자세하게 바라보고 학습함으로써, 이전보다 높은 성능을 가져올 수 있게 됩니다.
++ 쉽게 말하자면, 처음에는 k개의 pose vector를 모두 예측하여, 전체 문맥적인 feature를 추출하고 이를 토대로 각 부위마다의 bbox를 추정하고 각 부위에 따라 자른 영상으로 각 부위에 대해 다시 예측하는 모델을 이용하여 추론하는 방식을 이용하다는 이야기입니다.

수식 5와 같이 첫 stage 1에서는 원본 영상 b^0에서 모든 pose vector을 예측하고, 해당 예측 지점에 대해 다시 원본 영상에 맞는 pose vector \bold{y^1} 를 생성합니다.
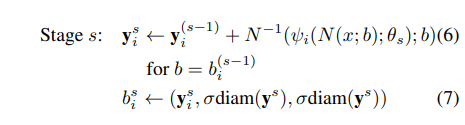
S개의 cascade stage s들은 수식 6, 7를 이용하여 join bounding box b_{i}^{s} 추론하고 이를 원본 영상에 맞도록 y_{i}^{s} 추론합니다. 수식에 대해 설명하자면 수식 7은 각 추론된 키포인트를 중심으로 일정 비율만큼의 박스를 생성하는 것을 의미니다. 수식 6에서는 stage s의 bbox에서 추론된 키포인트를 원복 영상에서의 좌표로 복원하는 수식에 해당합니다. 위의 수식을 통해 cascade하도록 추론된 값들을 연계해서 사용할 수 있게 됩니다.
Training
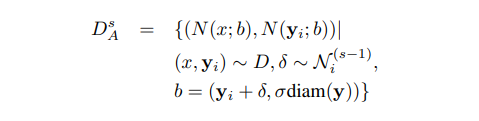
각 stage는 위의 수식을 통해 데이터를 증강하여 학습합니다. 이전 스테이지의 예측을 묘사하기 위해서 각 키포인트의 정규 분포 형태의 y를 랜덤하게 뽑아 데이터를 증강합니다.
각각의 스테이지는 위에서 설명한 바와 같이 L2 Loss를 통해 학습을 합니다.
Experiment
Dataset
(1) Frames Labeled In Cinema(FLIC)
– 4000 장(train), 1000 장(test)의 할리우드 영화에서 캡처한 영상으로 구성됨. 10 이하의 관절 포인트로 구성.
(2) Leeds Sports Dataset + extension(LSP)
– 11,000(train), 1,000(test)의 운동 영상으로 구성됨. 각각의 사람들은 14개의 관절 포인트로 구성.
Metric
Percent of Detected Joints(PDJ) : GT 키포인트간 거리 임계값 안에 들어온 추론된 관절 키포인트의 비율
++ 해당 방법론에서는 각 관절에 대해 따론 평가를 수행하였습니다.
해당 방법론에서는 추론 이전에 데이터 전처리를 수행합니다. FLIC에서는 face detector를 이용하여 일정 스케일의 body bbox를 추론하여 초기 bbox 정보로 사용하니다. LSP에서는 사람에 대한 bbox가 제공되기 때문에 해당 정보를 초기 bbox 정보로 사용합니다.
두 데이터셋에서는 3개의 stage를 사용하며, 스케일은 1.0 , 2.0을 이용합니다. 또한 개선을 위해 stage 2이후부터는 위에서 소개한 데이터 증강을 이용합니다. LSP를 예를 들면, bbox를 랜덤하게 이동한 40가지 경우와 14 관절에 대해 데이터를 증강합니다. 즉, 11,000(원본) x 40(bbox 이동) x 2(stage 2, 3) x 14(각 관절 포인트)로 데이터를 증강하여 모델을 학습합니다. 이는 큰 모델에게 필요한 기법이라고 주장합니다.
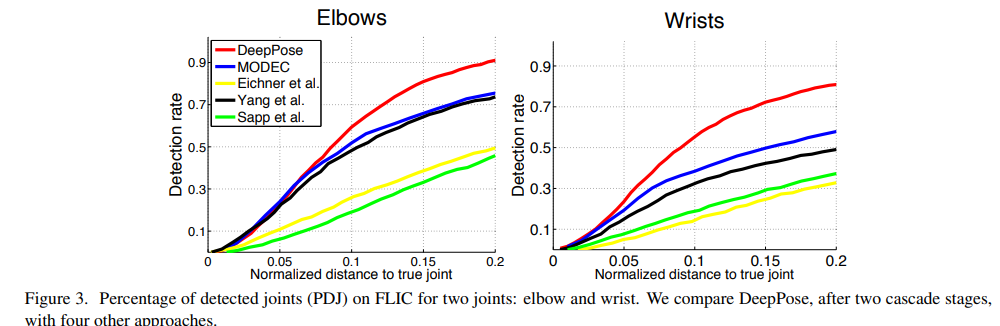
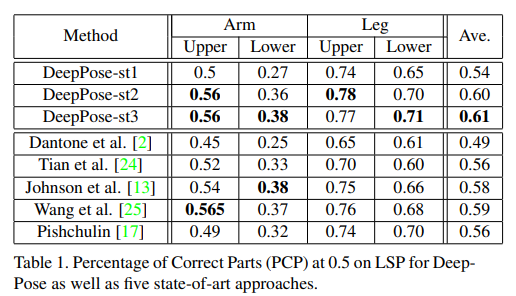
Fig 3, Table 1에서 보이는 것과 같이 정통적인 기법 보다 좋은 성능을 가져오는 것을 확인할 수 있습니다. 또한 stage가 증가함으로써, 성능이 개선되는 것을 통해 coarse-fine grained 방법이 성능 향상을 가져온다는 것을 증명합니다.

또한 Fig 6와 같이 stage가 개선됨으로써 GT(초록선)에 가까워지는 것을 볼 수 있습니다.


=========================================================================
해당 방법론은 처음 딥러닝을 적용한 방법론에 해당합니다. 하지만 별도의 모델인 stage를 나눠 자세히 봄으로써 각 관절에 대한 연관성을 학습할 수 없다는 한계점을 가지고 있습니다. 하지만 처음 시도한 점과 모델의 한계를 풀기위해 적용한 아이디어가 나름 신박하다고 생각합니다.