이번 리뷰는 Transformer에 관한 주제입니다. Transformer가 거품이다?라고 생각하시는 분들은 한번쯤 읽어보시면 좋을 것 같습니다.
Introduction
Convolutional Neural Network(CNN)가 오랫동안 사랑받아 왔지만 너무 많이 사용했던 것일까요? 사람들은 CNN을 대체할 새로운 무언가를 찾고자 했으며 떠오르는 유망주로 Transformer가 제안되었습니다.
잘 아시다시피 Transformer는 기존에 NLP 분야에서 처음 제안되어왔지만, Computer Vision 분야에서도 Transformer를 활용하고자 하는 움직임이 있었으며 결국에 Vision Transformer(ViT)를 시작으로 다양한 Transformer 네트워크들이 컴퓨터비전에서 제안되어왔습니다.
이러한 Vision Transformer들 논문들은 하나같이 입을 모아 말합니다. Receptive Filed가 제한적인 CNN과 달리 ViT는 multi-headed self-attention을 통해 global한 정보들을 처리하고 학습한다는 것을 말이죠.
그래서 한창 Transformer에 대한 기대감과 함께 너도나도 할 거 없이 Transformer를 활용한 방법론들이 막 나왔습니다만… 막상 써보니깐 기대했던 것 만큼 막 좋은 것 같지는 않습니다.
ViT의 가장 큰 문제 중 하나는 모델을 학습할 때 optimizing하는 것이 너무나 까다롭다는 것입니다. 우리가 흔히 사용하는 SGD optimizer를 사용하게 되버리면 학습이 잘 되지 않아 성능이 감소해버리고 그나마 AdamW 라는 optimizer가 잘 동작하여 대부분의 ViT들이 AdamW를 사용합니다.
또한 ViT는 그 외에도 네트워크의 Depth, training schedule length, learning hyper-parameter 등등 다양하면서도 사소한 옵션들로 인해 학습이 잘 되지 않거나 성능이 감소해버리는 문제들이 발생합니다.
하지만 CNN은 어떠한 optimizer를 사용하던지 간에 대부분 준수한 성능들을 보여주었으며 간단한 data augmentation, standard hyper-parameter 값을 가지고도 쉽게 optimizing이 되었기 때문에 수 많은 분야에서 오랜 시간 동안 사용해왔습니다.
그렇다면 도대체 CNN과 ViT의 차이는 무엇이길래 이러한 차이점이 발생하게 된 것일까요? 논문의 저자는 ViT가 앞 단계에서 수행하는 “Patchifies”가 주된 원인이라고 조심스래 예측합니다.
ViT는 입력 영상을 p x p 크기의 겹치지 않는 패치들로 쪼갠 다음 Transformer 인코더의 입력으로 사용합니다. 이러한 patch는 stride가 p 인 p x p 컨볼루션을 통해서 구현할 수 있으며 보통 p는 16이라는 값을 사용한다고 합니다.
이러한 큰 커널 사이즈와 큰 스트라이드를 가지는 컨볼루션은 전형적인 CNN 모델들과는 꽤나 반대되는 설계 방식입니다. 전형적인 CNN 모델들은 주로 3 x 3 커널 사이즈에 stride도 1~2정도로 작은 값들을 가졌기 때문이죠.
저자는 이러한 자신의 가설이 맞는지 확인해보기 위해, ViT의 초기 단계를 살짝 수정하였습니다. 바로 기존에 겹치지않는 p x p 패치로 쪼개는 작업 대신에 그림1과 같이 일반적인 컨볼루션 레이어를 아주 조금만 쌓는 것이었죠.(대충 5개의 컨볼루션 레이어를 사용하는 듯 합니다.)
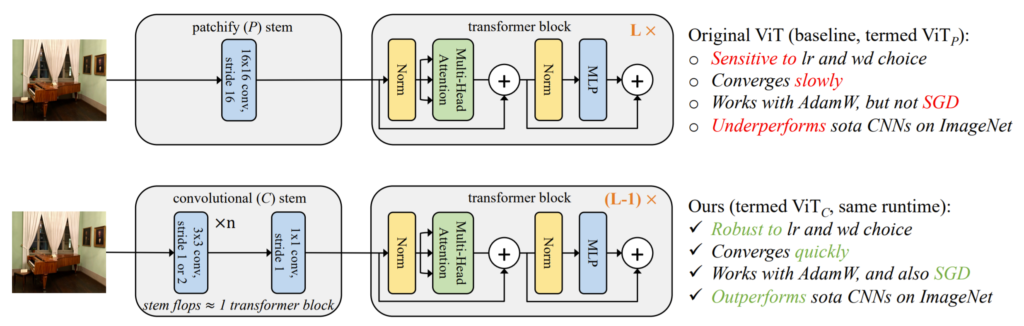
기존에는 그냥 컨볼루션 레이어 하나로 영상을 패치 단위로 쪼개기만 했다면 논문에서 제안하는 방식은 컨볼루션 레이어를 5~6개 정도 사용하여 feature를 생성하는 모습입니다. 그러다보니 기존 방식과 비교하여 Flop가 조금 늘어났으며 이를 보완해주기 위해 기존 ViT의 transformer block이 n개라면 n-1개만 사용합니다.
저자는 단순히 patchify stem을 convolutional stem으로 바꾸엇다는 것 만으로 1) ViT모델의 converge가 더 빨라졌으며, 2) AdamW 뿐만 아니라 SGD를 사용하더라도 모델의 성능 드랍이 발생하지 않고 3) learning rate나 weight decay가 기존 CNN 모델들과 유사하더라도 ViT의 안정성을 확보할 수 있었으며 마지막으로 ImageNet top-1 에러 값을 1~2 퍼센트 더 줄였다고 합니다.
Vision Transformer Architectures
그럼 ViT에 대해서 간략히 리뷰를 하고 그 다음에 저자가 설계한 convolutional stem에 대해서 알아봅시다.
일단 ViT는 입력 영상을 겹치지 않는(non-overlapping) p x p 패치로 쪼갠 다음에 학습되는 weight들을 통하여 각 패치를 d차원의 feature vector로 투영시킵니다. 이때 패치 사이즈는 보통 p = 16으로 설정하며 입력 영상은 224 x 224를 사용합니다.(아마 ImageNet에서 분류를 하다보니 이렇게 하는 듯 하네요.)
아무튼 이렇게 투영된 패치 임베딩 벡터들은 계속해서 transformer encoder를 통과하다가 마지막에 classification head를 통과하여 클레스 레이블로 생성됩니다.
이 때 저자는 기존 ViT에서 transformer 블록 이전에 단계를 network’s stem이라고 명칭하였으며 여기서 기존 ViT의 stem은 stride-p, p x p kernel을 가지고 있기에 patchify stem 이라고 명칭합니다. 마지막으로 논문에서 제안한 small stride & kernel size를 가지는 multiple CNN은 convolutional stem이라고 명칭합니다.
Convolutional stem design
저자는 3 x 3 컨볼루션을 쌓고 마지막에 1 x 1 컨볼루션을 통하여 d 차원의 트랜스포머 입력을 만듦으로써 최소한에 convolutional stem을 디자인하였습니다.
이러한 stem은 224 x 224 입력 영상을 overlapping stride를 통해 14 x 14 feature로 생성하게 되는데, 이는 기존 ViT가 사용하는 patchify stem에서의 결과와 동일한 숫자의 입력입니다. (224 x 224를 16 x 16 kernel size & 16 stride를 가지는 컨볼루션을 태우면 14 x 14 feature가 생성됨.)
컨볼루션 설계 방식은 매우 간단합니다. 모든 3 x 3 컨볼루션은 stride를 2를 가지고 있으며 output 채널은 2배를 가지거나, 또는 stride가 1이며 output 채널이 기존과 동일한 경우로 구성되어 있습니다.
Measuring Optimizability
사실 이 논문은 분석이 더 중요하며 비중이 높은 논문입니다.(그야 논문에서 제안하는 방법이 기존 ViT에서 컨볼루션 5개 붙인거 밖에 안되기 때문이죠.) 자 그러면 저자가 실험에서 보고자하는 평가 요소에 대해서 먼저 알아봅시다.
Training length stability
기존에 ViT 모델들은 학습 에포크가 300~ 400 에포크로 제법 큰데, 이는 기존의 CNN 방식들처럼 100에포크 정도만 학습시키면 top-1 성능이 2~4퍼센트 정도 하락했기 때문입니다. ImageNet을 학습시킬 때 저자는 400 에포크에서의 top-1 정확도를 대략적인 최종 성능으로 정의하였으며 이는 더 길게 학습시켜봤자 top-1 성능이 향상되지 않았고, 모델의 정확도를 50, 100, 200 에포크에서와 비교하고자 그랬다고 합니다.(800 에포크를 실험하려면 많이 힘들긴 하죠ㅋㅋ)
여기서 저자는 training length stability를 대략적인 수렴 정확도의 차이라고 의미하며 이는 직관적으로 convergence speed를 측정한다고 합니다. 수렴 속도가 더 빠른 모델은 분명히 실용적이며 특히 많은 모델을 학습할 때 효율적일 것입니다.
Optimizer stability
기존의 ViT 방법론들은 대부분 AdamW를 optimizer로 사용하였습니다. 왜냐하면 SGD의 결과가 일반적으로 좋지 못하였으며 특히 이미지 넷 Top-1 accuracy가 7% 가량 떨어졌다고 합니다. 이러한 ViT와 달리 CNN 기반 모델들은 SGD를 쓰나 AdamW를 쓰나 모두 비슷비슷한 성능을 보이며 좋게 학습이 되죠?
SGD는 AdamW 보다 더 적은 하이퍼 파라미터를 가지고 있기 때문에 보다 실용적인 측면에서 효율적이라고 볼 수 있으며 50% 더 적은 optimizer state memory를 필요로 하여 확장에 용이합니다. 저자는 AdamW와 SGD를 사용하였을 때 성능의 갭을 optimizer stability라고 정의하였습니다.
Hyperparamter (lr, weight decay) stability
Learning Rate(lr)과 Weight decay(wd)는 모델을 최적화하는데 있어서 가장 중요한 하이퍼파라미터 들입니다. 새로운 모델과 데이터 셋들은 종종 이러한 하이퍼 파라미터들이 어떻게 선택되어지는지에 따라 엄청나게 드라마틱한 성능 결과를 가져옵니다.
일반적으로 넓은 범위에서 lr과 wd 값을 사용하더라도 좋은 결과를 가져오는 모델과 옵티마이저가 바람직하겠죠? 저자는 이러한 하이퍼파리미터 안정성을 찾기 위하여 error distribution functions(EDFs)를 비교하였다고 합니다.
Peak performance
마지막으로 Peak performance입니다. 얘는 뭐 간단하게 요약하자면 400 에포크 동안 모델을 학습시키면서 생성된 결과 값 중 가장 좋은 성능을 보인 결과를 의미합니다. 대충 learning rate나 weight decay 또는 optimizer 등등 여러가지 요인들이 바뀌면서 동일 에포크에서 성능을 비교하면 무엇이 더 좋다라고 하기에 애매하니, 400 에포크 중 가장 좋은 성능을 하나 찝어서 비교하겠다는 것 같습니다.
Experiments
그럼 본격적으로 실험 결과에 대해 알아봅시다. 먼저 저자는 ImageNet-1k 데이터 셋을 이용해서 실험을 진행하였습니다. 실험 비교 대상으로 사용된 모델들은 각각 patchify stem을 사용하는 ViT_{P}, convolutional stem을 사용하는 ViT_{C}, 마지막으로 CNN 기반 SOTA 모델 RegNetY입니다.
Training Length Stability
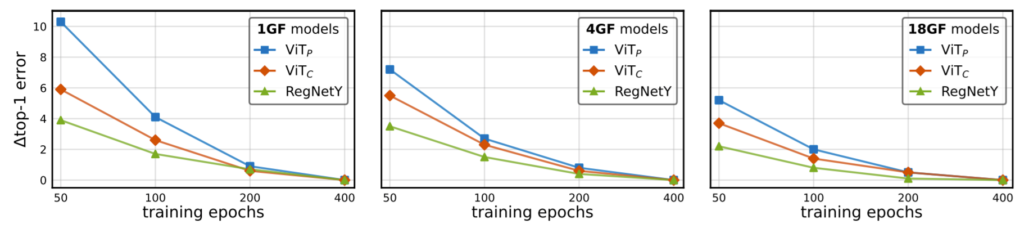
먼저 각각의 네트워크들이 얼마나 빠르게 수렴하는지를 알아봅시다. 저자는 대략적으로 에러가 수렴하는 정도를 관측하기위해 400에포크를 최대 스케줄로 설정하였으며 이는 200~400 에포크 사이에서 모델들이 수렴하기 때문이라고 합니다. 또한 ViT 모델들은 AdamW, RegNetY는 SGD를 사용함으로써 optimizer에 상관없이 학습 길이에 따른 안정성을 비교하고자 하였습니다.
결과는 그림2에서 확인하실 수 있습니다. 먼저 9개의 모델에 대하여 각각 50, 100, 200, 400 epoch일 때 성능이 나타나있는데 한눈에 보더라도 ViT_{C}가 ViT_{P}보다 더욱 빠르게 수렴하는 것을 확인할 수 있습니다. (50 epoch에서 top-1 error가 대략 4%정도 차이나는 것을 확인할 수 있음.)
아 여기서 깜빡하고 GF에 대한 설명을 안드렸는데 그냥 간단하게 말씀드리면 숫자가 더 클수록 네트워크가 더 깊다고 생각하시면 될 것 같습니다.
Optimizer Stability
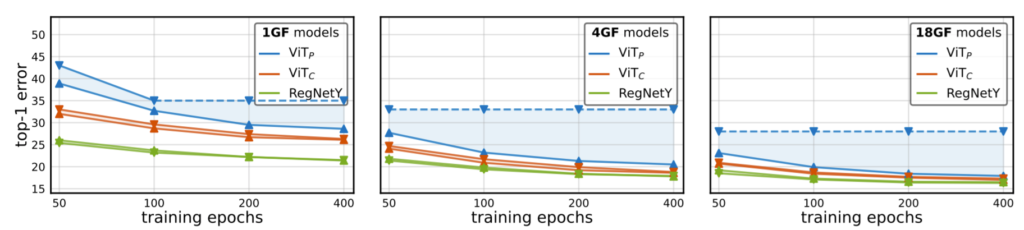
다음으로는 AdamW와 SGD optimizer의 차이에 대한 결과입니다. Stem의 종류(P, C) X GF 크기(1, 4, 18) X 에포크 길이(50, 100, 200, 400) X 옵티마이저 종류(AdamW, SGD)로 총 48개의 그리드에 대한 결과를 확인하였습니다.
결과는 그림 3에서 보시는 바와 같이 베이스라인으로 설정한 RegNetY의 경우 SGD를 사용하나 AdamW를 사용하나 별 차이가 성능의 큰 차이가 존재하지 않는 모습입니다.(SGD가 0.1~0.2% 정도 더 좋다고 하네요.)
반면 ViT_{P}의 경우 매우 큰 성능 감소가 발생하게 되는데 400 epoch, 18GF 기준 약 10% 정도 성능 드랍이 발생합니다. 하지만 convolution stem을 가지는 ViT_{C}의 경우는 SGD와 AdamW 차이가 대부분의 에포크에서 크게 차이나지 않는 것을 확인할 수 있으며 대략 0.2% 정도 차이나는 듯 합니다. 바꿔말하면, RegNetY와 ViT_{C}는 SGD 또는 AdamW를 통해 보다 쉽게 학습이 가능하다는 것이겠네요.
Learning Rate and Weight Decay Stability
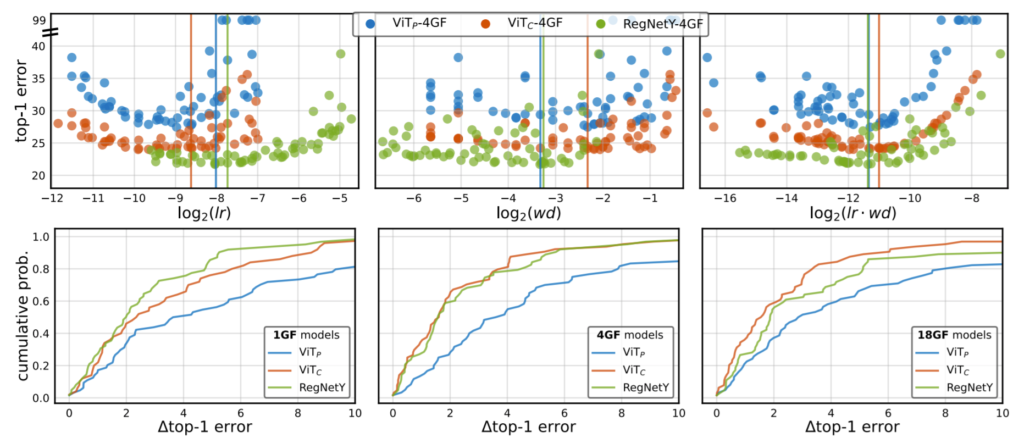
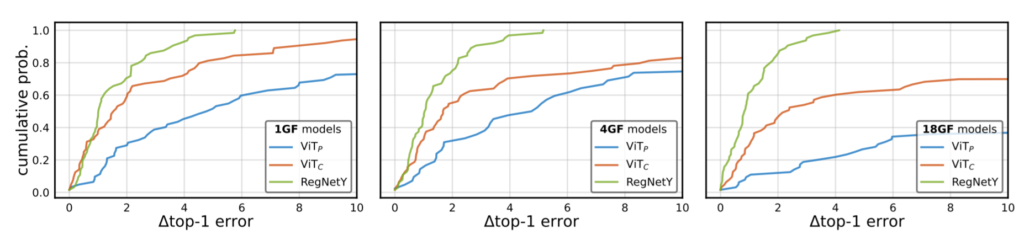
다음으로 여러 모델들이 learning rate와 weight decay 변화에 따라서 얼마나 예민한지를 알아보는 실험입니다. 이를 정량적으로 나타나기 위해서, 위에서 말했듯이 Error Distribution Functions(EDFs)를 사용하였습니다. EDF는 low부터 high error의 결과를 정렬한 다음, 에러가 상승했다는 것을 누적 비율로 plot한 것입니다.
저자는 lr과 wd의 함수로 모델의 EDF를 생성하였는데 이는 직관적으로 만약 모델이 이러한 하이퍼 파라미터 선택에 강인하다면, EDF가 가파를 것이며 반면에 모델이 민감하다면, EDF가 얕게 plot 될 것이라고 말합니다.
먼저 그림 4는 AdamW를 통해 학습도니 모델의 EDF를 scatterplot으로 나타낸 것이며, 그림 5는 SGD에 대한 결과입니다. 모든 케이스에서 ViT_{C}의 lr & wd 안정성이 AdamW, SGD에서 모두 ViT_{P}보다 더 향상된 것을 확인할 수 있습니다. 이것은 lr 과 wd가 ViT_{C}를 ViT_{P}보다 더 쉽게 최적화한다는 것을 보여준다고 하는데… EDF가 생소하다보니 사실 어떻게 봐야할지 논문을 읽어도 모르겠네요.
Peak Performance
마지막으로 Peak Performance입니다. 저자는 공평한 비교를 위해 먼저 모든 모델들이 400 에포크를 학습하도록 했으며 weight EMA를 사용하고, regularization과 augmentation method 역시도 동일하게 사용했다고 합니다. 모든 SGD를 통해 학습된 모든 CNN은 lr을 2.54, wd 는 2.4e-5를 사용하였습니다.
모든 ViT 모델의 경우 AdamW를 사용하였으며 이 때 learning rate는 1.0e-3, weight decay는 0.24를 사용하였으며 36GF model을 사용하지 않았다고 합니다. ViT 모델들의 경우 입력 영상의 크기는 224 x 224를 그대로 사용하였으며 CNN 네트워크만이 최적화된 resolution을 사용했다고 합니다.(왜그런지는 잘 모르겠네요?)
Peak Performance에 대한 결과는 그림 6과 같습니다.
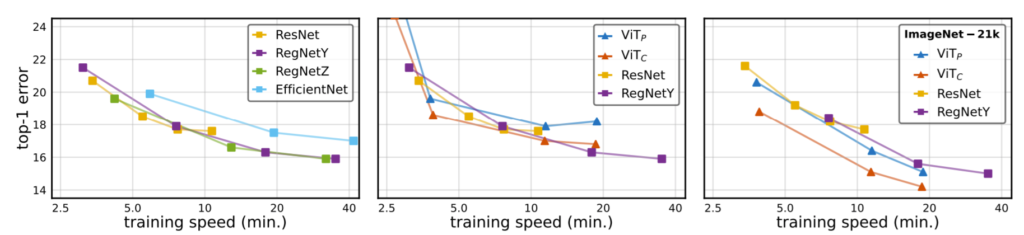
제일 좌측은 Sota에 해당하는 CNN 모델들의 결과를 나타낸 것이며, 가운데는 ViT와 CNN 모델들을 비교한 것이고 제일 우측은 ImageNet-21K로 사전학습시킨 모델들의 비교입니다. 가운데에서 ViT 기반 모델들이 CNN 모델들에 비해 성능이 조금 모자란 모습을 보이는데 이는 ImageNet-1k training data만을 사용하여 학습시켰기 때문으로 보이며, 우측에 21k 데이터 셋으로 학습할 경우 역시나 Transformer 방법론들이 더 큰 성능 향상을 보이고 있습니다. 또한 convolution stem을 사용하였더니 기존 patchify stem보다 더 좋은 성능을 보이는 모습이며 학습 속도는 동일한 모습입니다.
결론
Transformer에 대한 사람들에 기대감은 매우 컸지만 생각보다 까다로운? 모습 + 성능 향상이 매우 극적이지 못함을 이유로 다시 CNN으로 넘어오는 사람들이 많은 것 같습니다. 해당 논문은 이러한 Transformer의 문제점을 보완하고자 아주 간단한 CNN 레이어 5개만을 사용하였는데, 풀고자 하는 문제가 무엇인지를 정확히 인지하여 설계를 하니 이렇게 간단하면서도 좋은 결과를 보인 듯 합니다. 문제를 잘 정의하는 것의 중요성을 다시 한번 깨닫고 가네요…
어디 논문인가요..? 꽤 분석이 잘되있는 것 같네요.. 이러한 문제는 단순힌 ViT에만 있는 것이 아닌고 그 후속작 모두에 있을 것 같은데 … 제가 쓰고 있는 모델도 검증해봐야하나… 싶네요
Facebook AI Research에서 낸 논문이고 어디에 accept 됐는지는 잘 모르겠네요
Classification task가 아닌 Detection이나 Retrieval과 같은 다른 task에 적용했을 때 제안한 방법의 성능에 대한 다른 실험이 있을까요!?
음 해당 논문에서는 classification 만을 다뤘고 다른 분야에 대해서는 다루지 않은 듯 합니다.
아마 여러 안정성을 증명하는 과정에서 대략 100개 이상의 경우의 수로 실험을 진행하다보니 다른 분야까지는 실험하지 못한 듯 합니다.