
이번에 리뷰할 논문은 Semantic segmentation 논문입니다. 계속 depth estimation 관련 논문만 다루다가 갑자기 Segmentation이라니 ?!?! 하실 텐데요, depth estimation과 Segmentation은 둘다 pixel level 에서 predict을 한다는 점에서 서로의 방법론을 차용할 수 있는게 많기 때문에 유심히 보고 있습니다. 이 논문은 위 그리고 같이 boundary를 더욱 좋아지게 하는 방향으로 학습을 제안합니다. 이러한 방법론은 제가 하고 있는 Self-supervised monocular depth estimation에도 적용할 수 있어서 읽었고 여러분에게도 소개해드릴려고 합니다.
- Introduction
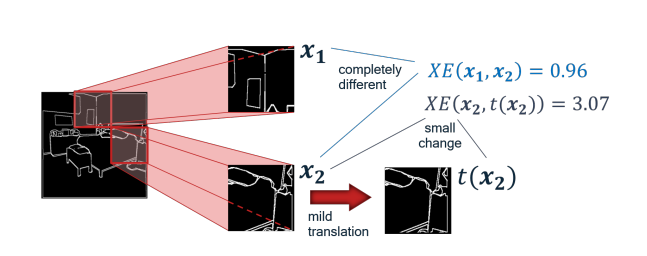
기존 Semantic Segmentation에서 예측된 값을 GT와 비교할때 Cross Entropy Loss를 사용합니다. 이 Cross Entropy loss를 class를 분류할때 보통 사용되며 pixel당 class를 가지는 Segmentation에서는 유용한 loss였습니다. 하지만 이 로스의 경우 단순히 label 값만을 보기 때문에 공간적인 정보는 학습할 수 없습니다. 그 예로 아래 그림과 같이 X1과 X2의 Loss값 보다 X2와 t(X2)의 Cross Entropy 값이 큰 것으로 보아 전체적인 물체의 모습은 Loss가 담아 내지 못하는 것을 알 수 없습니다.
위와 같은 문제를 해결하기 위한 이 논문의 컨트리뷰션은 다음과 같습니다.
- Semantic Segmantation 의 엣지를 살리기 위한 InverseForm module을 제안함
- Inverse Form module은 Plug and Play 방식으로써 다양한 백본에 붙힐 수 있는 방법론임
- 성능 .
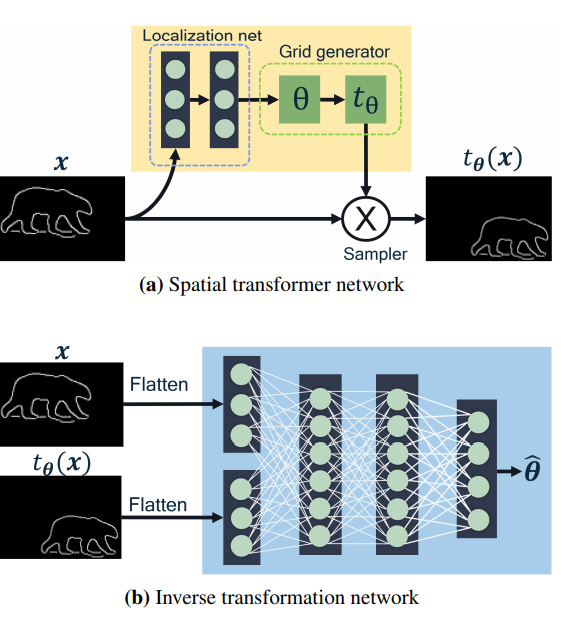
InverseForm은 위 그림 (b) 를 사용하는 방법론입니다. (a)는 그 유면한 Spatial Transformer Network로 이미지 X를 값 세타를 이용해 영상 X로 이동하는 방법론입니다. 이를 역으로 만들어서 생성된 영상과 GT의 Boundary의 쎼타가 줄어드는 방향으로 학습 할 수 있도록 하여 두 영상의 공간적 거리를 줄여 전체적인 Structure를 보완해줍니다.
2.Method
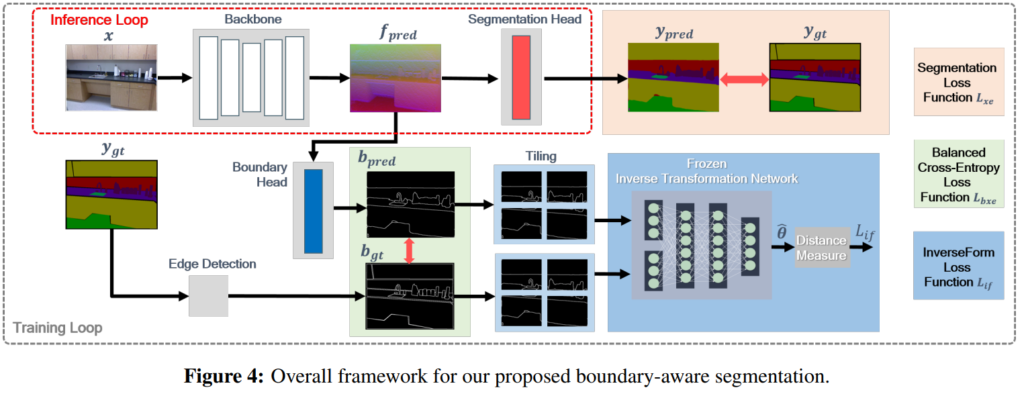
전체 파이프라인은다음과 같습니다 Inference Loop가 기존 Segmantation 방법론들의 파이프라인이고 그것에다가 킽에 과정을 추가하면 됩니다. 어느 백본 모델에다가도 붙힐 수 있는게 특징입니다.
Inverse Transform Network를 이용해 두 영상을 비교하기 에 앞서 각 영상을 조각내줍니다. 이는 보다 Local 한 성능을 올려준다고합니다. Inverse Transform Network는 Segmantation 학습할 때는 Freeze하는데 그럼 Inverse Transform Network는 어떻게 학습하냐 하면 위 Spatial Transform Network를 이용해 GT를 생성해서 학습한다고 합니다.
두 영상에서 예측된 쎄타를 아래 식을 통해 Loss로 변경합니다.
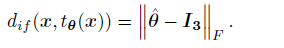
두 영상이 움직인 영상이 아니길 원하는 것이므로 쎄타는 identity matrix 랑 비교합니다. 이외에는 두 Boundary 부분의 Cross Entropy를 구하는 loss와 기존 Cross Entropy를 합쳐셔 성능을 내게 됩니다.
3.Result
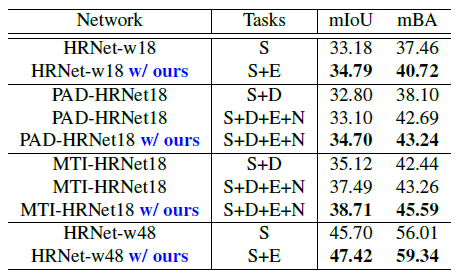
NYU-Depth-v2 데이터셋에서 성능 평가 입니다. 어떠한 백본에다가 넣던간에 성능이 올라가는 것을 확인 할 수 있습니다.
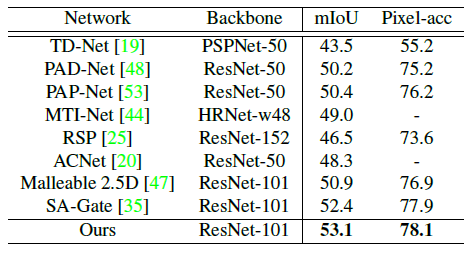
또한 다른 방법론과 비교해보아도 좋은 성능을 확인할 수 있습니다.
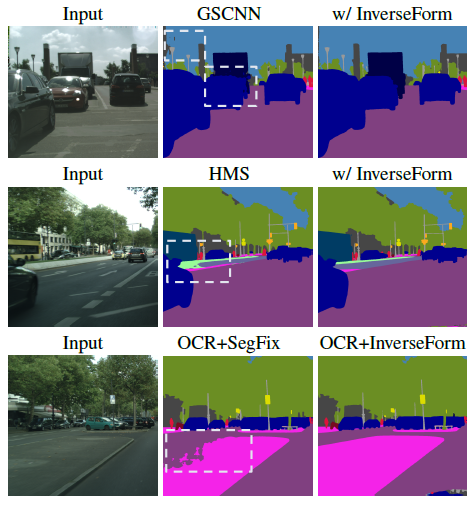
정성적 결과가 인상적인데, Boundary가 GT와 같이 예측하는 것을 볼 수 있습니다.
리뷰 잘 읽었습니다. Inverse Transformation Network에서 flatten하여 사용하는거 같은데, 제 생각에는 해당 과정에서 공간정보의 소실이 어느정도 발생한다고 생각이 되는데 혹시 Flatten부분을 CNN레이어 및 Global Pooling으로 대체하는거에 대해선 어떻게 생각하시나요?
리뷰 잘읽었습니다. 소개해주신 방법론은 정말 범용적으로 사용할 수 있을거 같습니다. 유용한 논문 리뷰해주셔서 감사합니다.
근데… inference 할 때, 어떻게 사용한다는 이야기인지… 이해를 못하겠습니다. 그림을 보고 유추해보면 Inverse Transformation Network를 잘 정렬되도록 유도하는 방식으로 back propagation하는 것만으로도 효과가 있다는 것 같은데 맞나요?
To 형준
저도 해당 논문을 읽어보지는 않아서 확실한 대답이 아닐수는 있지만.. 제가 생각하기에 Flatten을 사용한 이유는 해당 논문에 Spatial Transform Network의 방법론에서 영감을 얻었기 때문에 Flatten을 그대로 사용한 것이 아닌가 싶습니다.
결국 구하고자 하는 세타는 FC layer를 타고 나온 어떠한 transformation matrix일테니깐요. 또한 영상 전체를 flatten하는 것이 아니라, 영상의 패치 단위로 flatten하여 각 영역 별 세타를 구하는 것이기에 flatten을 하더라도 지역적인 정보를 비교할 수 있다고 생각이 듭니다.