인트로
안녕하세요 이번 리뷰에서는 카이스트 데이터셋에서 SOTA를 찍은 논문을 리뷰해보겠습니다. MDPI 저널 Sensors에 나온 논문이구요. 상당히 높은 성능으로 압도적 SOTA를 찍었는데 어떤 획기적인 방법을 사용한 것일까요?
아마도 연구원분들 모두 카이스트 데이터셋에서의 보행자 인식은 해본 경험이 있을거라고 생각이 되는데요. 그래서 해당 논문에서의 성능이 얼마나 높은 수치인지 체감이 될 겁니다. 무려 miss-rate기준으로 4.91%를 달성했는데요. 무슨 방법을 썻길래 이리 높은 성능을 보였는지 같이 살펴봅시다.
먼저 해당연구는 중국의 베이징 대학교에서 한 연구이구요. 역시나 중국에는 잘하는 사람이 많은거 같습니다.
논문 설명

논문의 흐름대로 설명드리고자, 첫번째 피규어를 인용해왔습니다. 먼저 논문에서는 다른 멀티스펙트럴 보행자 인식분야 논문에서와 비슷한 흐름대로, 왜 멀티스펙트럴 센서가 필요한지에 대해서 설명합니다. 저희 입장에서는 해당 분야에 익숙하기 때문에 사실은 뻔한 이야기라고 생각합니다. Illumination에 변화에 따른 RGB카메라와 Thermal 카메라가 가지는 특징점들에 대해서 이야기하며 멀티스펙트럴 기반의 연구가 왜 필요한지에 대해서 장황하게 설명합니다. 이러한 부분은 저의 리뷰를 읽고 계시는 RCV 연구원님들에게는 너무 당연한 이야기가 될거 같아서 과감하게 생략하기로 결정하였습니다. 대신 좀 더 방법론적인 면이나 실험적인면에 주안점을 둘 생각입니다. 만약 해당부분에 관심이 가시는분들은 논문의 introduction부분을 가벼운 마음으로 읽어보시길 권장드립니다. (사실 해당부분에 관심이 가시는분들은 KAIST 데이터셋 원 논문을 읽어보시는게 더 나을거 같긴 합니다.)
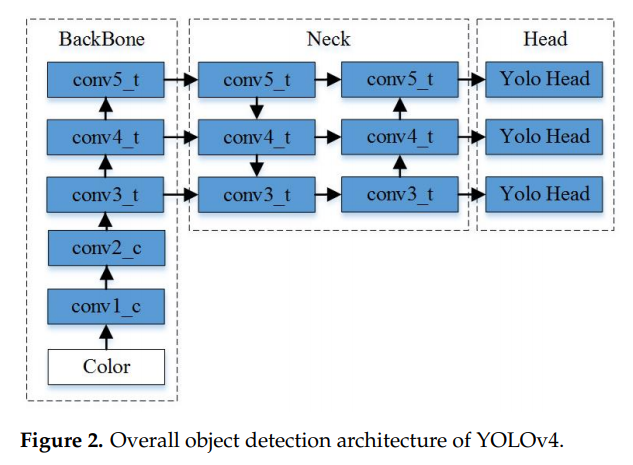
앞에서 얘기했듯이 군더더기 내용을 다 생략하고 리뷰를 진행할 예정인데 그러다보니 벌써 논문의 6페이지에 왔습니다. 그전까지는 거의 Related works및 multispectral pedestrian detection의 필요성에 대해 이야기합니다.
거두절미하고 위의 Figure 2에 대해서 설명드리자면 아마도 익숙하신 분들도 있을거라고 생각이되는데 YOLO4 아키텍쳐 입니다. 개인적으로 YOLO시리즈랑은 친하지 않아서 해당 논문을 보며 알게된점이 많은데요. 저와 같은 분들을 위해서 간략하게 설명해드리겠습니다. 먼저 해당 YOLO 아키텍쳐의 핵심은 Spatial Pyramid Pooling, path aggregation network를 사용 했다는 점과, Backbone으로 CSPDarknet-53을 사용했다는점에 있습니다. Yolo v4가 세상에 공개된 시점 Resnet이 지배하던 시대였던점을 감안하면 Darknet쪽 백본을 사용하는 시도는 Resnet을 대체할만한 백본을 찾기위한 시도였던거 같네요. 그리고 Detection Head에 있는 YOLO head에서는 각각의 3개의 anchor boxes를 사용하기 때문에 총 9개의 서로 다른 scale 을 가지는 anchor bboxes를 사용합니다. 또한 개인적으로 생각하기에 특이 했던점은 각각의 bbox를 logistic regression으로 예측을 했다는건데, 그냥 softmax를 사용하지 않고 logistic regression을 여러개 사용한게 차이점이지 않나 싶습니다.
여기까지 논문에서 사용한 기본적인 베이스 아키텍쳐인 Yolo v4에 대해서 설명을 드렸습니다.
이제 본격적으로 논문에서 소개하는 아키텍쳐 종류 및 방법론들에 대해서 설명 해드리겠습니다.
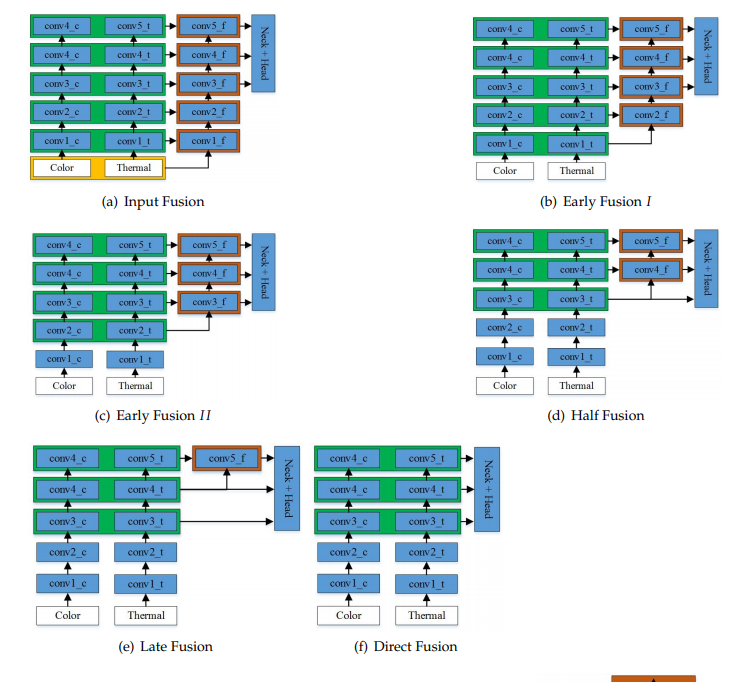
멀티스펙트럴을 사용하여 최초로 보행자 인식을 했던 논문에서는 Faster-RCNN를 베이스 아키텍쳐로 사용을 했는데요. 이때, 서로다른 모달리티가 합쳐지는 위치에 따라서 성능에 차이가 남을 리포팅하였고, 중간레벨의 피쳐에서 합쳐지는 Halfway Fusion이 가장 높은 성능을 기록했다고 하였습니다.
위에서 설명한 내용과 비슷하게 해당 논문에서도 RGB 피쳐와 Thermal 피쳐가 합쳐지는 위치를 기준으로 Input Fusion, Early Fusion, Halfway Fusion, Layer Fusion, Direct Fusion으로 나누고 실험하였습니다. 컨셉은 매우 흡사하지만, 베이스 아키텍쳐가 Yolo v4이기에 약간 차이점이 존재하긴 하네요.
여기에 추가적으로 피쳐를 합치는 과정에서 기존에는 주로 Concatenate한다음 NiN이라고 불리우는 1×1 Convolution layer를 사용하여 피쳐의 dimension을 축소했다면, 해당 논문에서는 이 외에도 다른 방법들을 소개합니다. 그리고 그 내용은 아래와 같습니다.
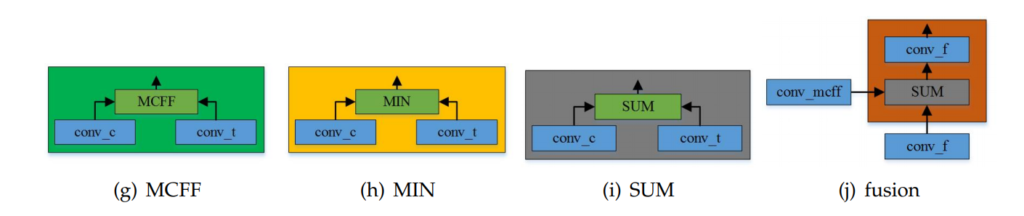
기존에 사용했던 NiN은 위의 그림에서보시면 (h) 이구요. 아마도 MIN이라고 표기되어있는건 제생각엔 오타같은데 글에서도 MIN 이라고 여러번 표기하네요. 또한 그냥 SUM을하는 방식이 (i)이고, 논문에서 제안하는 핵심 방식은 MCFF와 fusion을 합친 방식입니다.
개인적으로 논문을 볼 때, 마음에 들지 않았던 부분은, MCFF가 무엇인지에 대한 설명 없이 계속 MCFF라는 말이 나와서 이해가 안됐었는데 뒤에 방법론쪽에 자세히 설명하여 그 뒤에 이해할 수 있었습니다. 아마 논문 읽어보실 분 있으면 참고하시기 바랍니다.
어쨌든, 논문에서의 핵심은 YOLO V4를 사용했다는 것과 기존 NiN을 MCFF로 대체했다는 것인데요. 그럼 그 MCFF가 대체 무엇이냐? 에 대해서 알아봅시다.
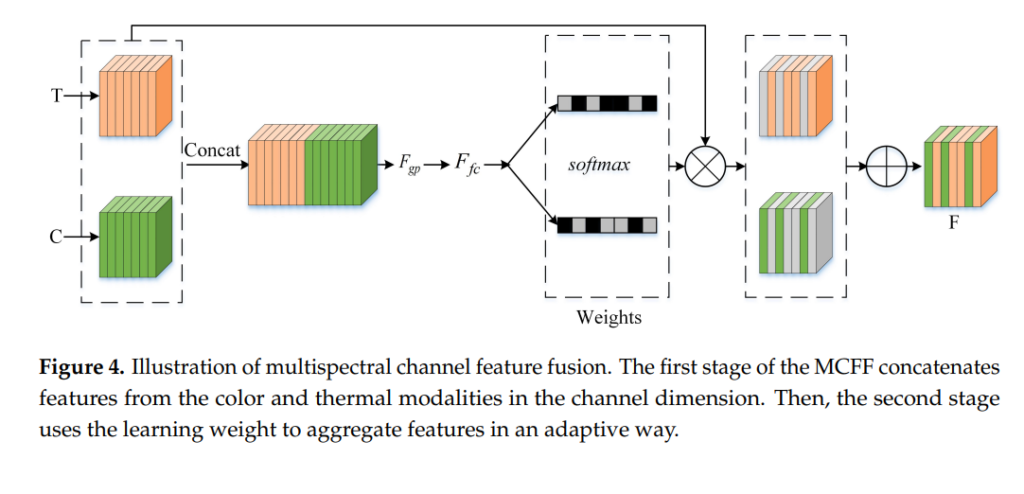
위의 그림이 바로 MCFF가 어떤식으로 이루어지는지 설명하는 그림입니다. 먼저 NiN과 마찬가지로 두개의 모달리티로부터 얻은 피쳐맵을 channel axis 기준으로 concat합니다. 여기까진 NiN과 다른바가 없는데 뒤에부터 약간의 차이점이 있습니다. 결론적으로 말씀드리면 illumination의 스케일에 따른 attention 기법이라고 보면 되는데요 과연 어떤 과정으로 이루어지나 설명해드리겠습니다. 아마 위의 그림보다 수식으로 이해하는게 좀 더 직관적이라고 생각이 되기 때문에 논문에서 사용한 수식들을 인용해서 설명해드리겠습니다. 해당 설명들과 위에 피규어4를 매핑하며 이해해보시는 것을 추천드립니다.

먼저 i번째 conv레이어에서 얻은 Color 에 대한 피쳐맵과 Thermal에 대한 피쳐맵은 Channel방향으로 Concat되어 F_i라는 피쳐맵으로 바뀝니다. 여기 까지는 기존 방법론들과 같으며, 그냥 채널방향으로 이어 붙혔다고 생각하시면 됩니다.
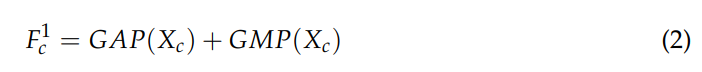
이후 Concat된 피쳐에서 Global Average Pooling과 Global Max Pooling을 각각 계산한 후, 이의 합을 구해줍니다. 이 값은 뒤에 FC레이어의 인풋으로 사용됩니다.

위의 수식 (2)를 통해 얻은 값을 FC 레이어를 통과시켜 z라는 1D vector 를 얻습니다.
식 (3) 번 까지 계산을 하였으면 피규어4의 아래와 같은 부분까지 계산이 된 것 입니다.
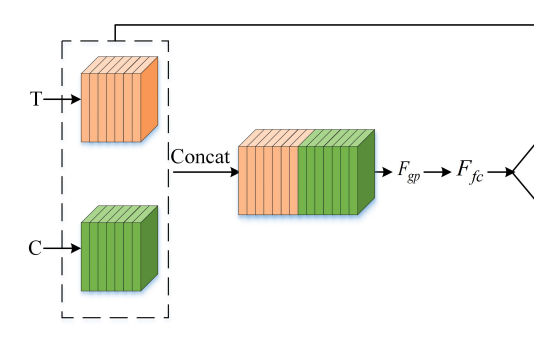
이제 뒤에 부분에 대한 연산을 알아봅시다. 먼저 그림을 보겠습니다.
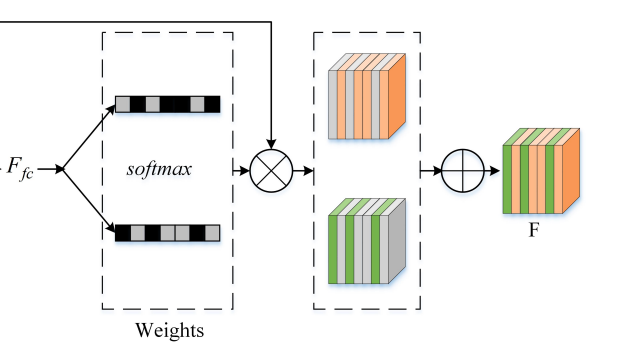
앞에서 구한 식 (3)의 결과값이 위의 그림에서 F_fc 입니다. 해당 F_fc에는 인풋 이미지 피쳐의 채널에 대한 A, B weight값을 가지고 있습니다. 말이 좀 어려운거 같아서 예시를 통해 설명해드리겠습니다.
예를들어 Thermal 이미지와 Color 이미지가 Conv layer들을 통과하며, 둘 다 (1, 80, 80, 256) 의 차원을 가진다고 해봅시다. 여기서 1은 배치사이즈, 80은 각각 w, h, 그리고 256은 channel 사이즈를 나타냅니다. 해당 피쳐들은 위에서 설명한 식 (1), (2), (3)의 연산을 거치며 (1, 1, 256, 2) 차원으로 변합니다. 그리고 이러한 (1, 1, 256, 2)의 차원을 가지는 값이 식 (3) 연산 이후에 나온 z 입니다. z가 의미하는 바는 인풋 이미지의 각각의 채널에 대한 weight 값 A, B입니다. 그리고 이 weight값들은 illumination의 scale에 따라 변하게 됩니다.

해당 weight값들로 구성된 z는 식 (4)번과 같이 softmax 함수를 통해 normalize되고, 0~1사이의 값으로 바운딩 됩니다. 그리고 이 값들을 각각 알파와 베타로 표현하였습니다.
해당 알파와 베타값은 이제 다시 인풋으로 사용된 Color, Thermal 피쳐맵에 곱해진 후, 식 (5)와 같이 더해집니다. 그리고 그 더한 값인 F_c를 최종적으로 사용합니다.
이게 기본적인 MCFF 의 원리이며, 일반적인 attention mechanism과 크게 다르지 않습니다.
실험
실험은 KAIST 보행자셋과 Utokyo 데이터셋에 대해서 진행하였으며, 저희의 주된 관심사인 KAIST데이터셋에 대한 실험 위주로 제가 느꼈을 때, 중요하다고 생각되는 부분을 위주로 서술하겠습니다.
먼저 카이스트 데이터셋은 기본적으로 해상도가 640*480 입니다. 이 이미지를 640*640으로 리사이즈 하여 사용하였습니다. 평가매트릭은 Miss-rate를 사용하였으며, 다른 논문들과 비슷하게 FPPI range를 0.01~1 로 하였고, height기준 55픽셀 이하는 ignore 처리하여 학습 및 평가 하였습니다. 여기서 조금 의문은 일반적인 reasonable 세팅은 50픽셀 이상이라고 설명해놓고서 실험은 55픽셀 이상을 기준으로 하였다는게 조금 이상하긴 합니다만… 기존 논문들에서도 50픽셀과 55픽셀을 혼용하여 사용하고 있고, 실제 성능에 크리티컬하게 영향을 미치진 않을거라 생각합니다. 아마도 50픽셀은 오타이고 실제 실험에서는 55픽셀을 기준으로 평가했을거라 생각됩니다.
카이스트에는 총 4개의 class가 있습니다. person, people, cyclist, person? 여기에 배경까지 포함하면 총 5개가 될 것 입니다. 해당 논문에서는 이 class들 중에 person만을 사용하였고, person이 아닌 클래스는 모두 ignore처리하여 모델을 학습하였습니다.
Annotation은 Original annotation과 improved annotation을 사용하였습니다.
앵커박스 튜닝도 하였는데, 해당내용은 논문을 참고하시기 바랍니다.
그리고 무엇보다도 가장 성능에 크리티컬했다고 생각되는 부분은 제 생각엔 배치사이즈가 아닐까 생각됩니다. 640*640의 멀티스펙트럴 이미지를 사용했음 에도 불구하고 미니배치 사이즈가 무려 80입니다… 해당 부분을 읽고 아마도 잘못읽은게 아닌가 다시 읽어보았는데 뒤에 부분을 읽고 궁금증이 해소되었습니다. 아래는 해당 원문입니다.
To carry out the experiments, an Intel Xeon E5-2620 at 2.1 GHz CPU server with 90 GB of memory and four Tesla P40 (24 GB) GPUs was used.
P40 GPU가 병렬로 4개가 사용이 되었고 총 메모리로만 보면 무려 90 GB네요.
비록 재원이 좋다고 하지만 그래도 실험적으로도 논문에서 소개하는 방법론이 유의미한 결과를 보인건 맞는거 같습니다.
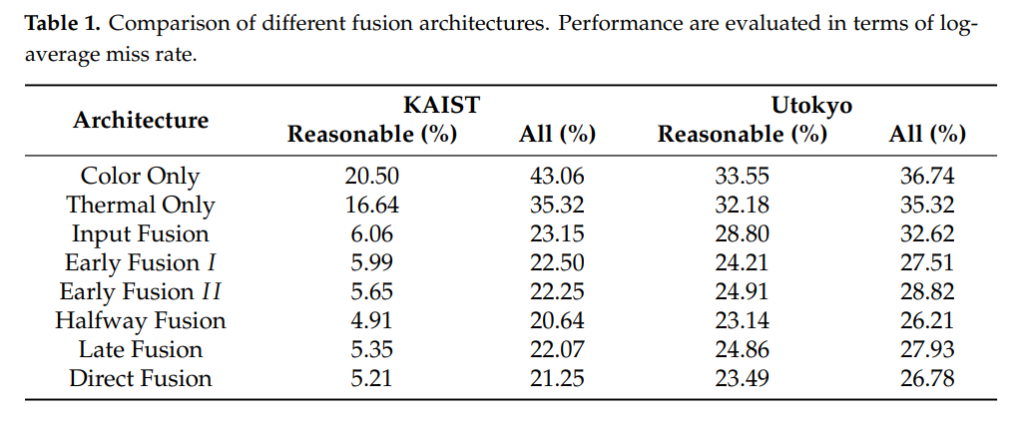
기존의 방법론들과 마찬가지로 Halfway Fusion에서 가장 좋은 성능을 보였으며, 이는 Yolo v4에서도 마찬가지인가 봅니다.

NiN보다 논문에서 소개하는 MCFF방법론을 사용하였을때, 가장 좋은 성능을 보였습니다.

위에는 MCFF이후에 피쳐맵이 어떻게 달라지는지에 대한 정성적인 결과이구요.
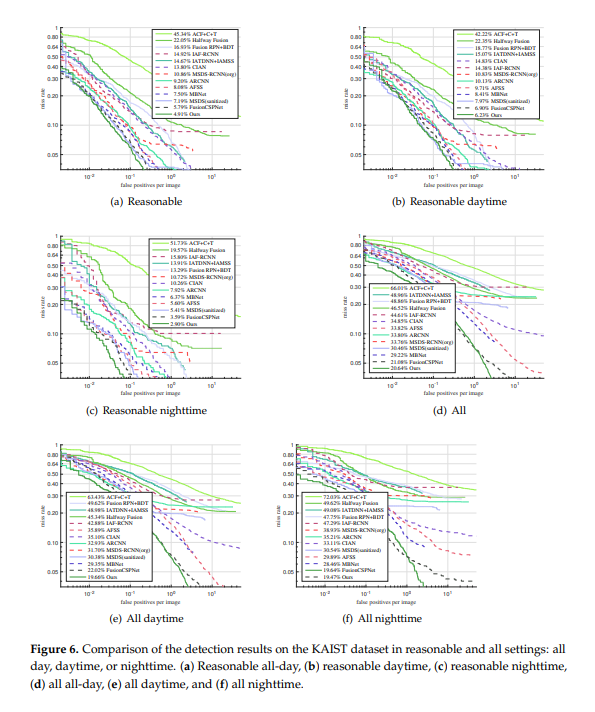
위에는 Miss-rate against FPPI 그래프 입니다. Reasonable 세팅에서 all에 대한 결과는 무려 4.91 % 이네요.

위에는 디텍션 성능에 대한 정성적 결과입니다.
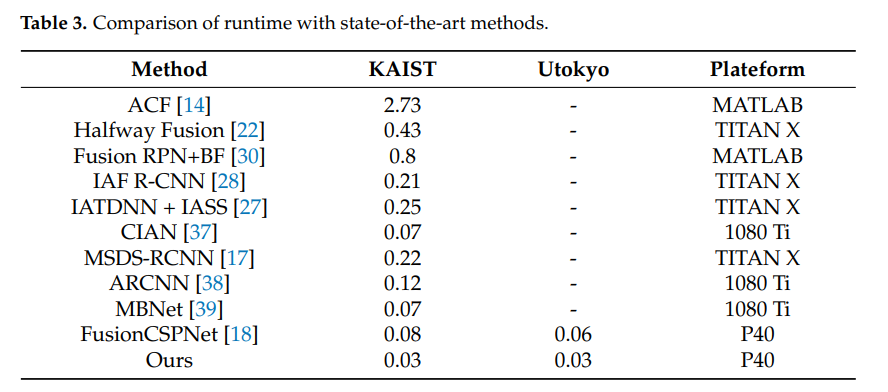
마지막으로 Runtime 비교인데요. 사실상 Platform이 너무 많이 차이나서 비교하는게 의미가 있을지 모르겠지만, Train코드가 공개되어 있지 않은 방법론들이 대부분이라 이해는 가는 부분 입니다. 개인적으로 해당부분은 논문에서 제외시켰어야 하지 않았나 생각이 듭니다.
요약
이번 리뷰에서는 Yolo v4 와 Attention mechanism을 활용하여 카이스트 데이터셋에서 SOTA를 달성한 논문에 대해서 살펴보았습니다.
후기
개인적으로 느끼기에 어려운 방법론이 적용된건 없다고 생각합니다. 다만, 놀라운 성능을 보였고, 이는 방법론적인 이유와 GPU 자원이 좋아서 배치사이즈를 크게 학습시킬 수 있었기 때문에 가능했다고 생각합니다. 무조건적으로 어렵고 복잡한 방법론이 항상 좋은건 아닌거 같습니다.
리뷰 감사합니다. 근데 이런 논문을 보면서 느끼는점은 왜 이미지 사이즈가 640×480일까요..? 오리지널 논문에서도 640×480이던데 저희는 640×512로 했단 말이죠 심지어 MBNet도 640×512로 했습니다. 어떤게 맞는걸까 이제는 헷갈리네요…
음.. 생각해보지 못했던 이슈네요. 저도 잘 모르겠지만 오리지널 논문을 따라가야하는게 아닌가 싶습니다.
리뷰 감사합니다. MCFF가 결과적으로 제안하는 방법론이고, MCFF는 Attention module로 이해하면될까요?
네 맞습니다.