이번에는 조금 색다르게? SuperResolution 논문을 가져왔습니다. 근데 이제 Depth map을 곁들인…
Introduction
기존에 존재하는 Color-guided Depth Super-Resolution(DSR) 방법론들은 학습 샘플로 paired RGB-D data가 존재해야만 했습니다. 이름부터가 Color-guided니깐, DSR을 학습하기 위해서는 guide로 사용해야할 RGB pair 영상이 존재해야 하겠죠?
하지만, 이러한 이렇게 pair한 데이터 셋을 취득하려면 반드시 RGB-D 카메라로 촬영된 데이터 셋이 존재해야 했기에 데이터 수급에 어려운 문제가 존재합니다. 그래서 저자는 cross-modality knowledge를 학습시킴으로써 RGB와 Depth modalities 모두 학습하지만 평가시에는 한쪽 modality(Depth)만 있어도 되는 방법론을 제안합니다.
이 저자의 핵심 아이디어로는 먼저 어떠한 네트워크 구조 변경 없이 RGB 영상에서 structural guidance의 knowledge를 DSR task로 전이시키는 것입니다. 또한 RGB 영상을 입력으로 하여 Depth map을 추정하는 Depth Estimation(DE) task를 추가하고, 이를 DSR task와 동시에 학습함으로써 DSR의 성능을 크게 향상시켰다고 합니다.
즉 DSR과 DE task에 대하여 cross-task distillation scheme을 통하여 서로에게 teacher-student role을 함으로써 학습이 진행됩니다. 또한 추가적으로 Structure Prediction(SP) task를 통해 DSR과 DE 네트워크가 보다 더 효율적으로 Depth map에 대한 structure 표현력을 학습할 수 있도록 하였습니다.
Network Architecture
먼저 전체 PipeLine부터 살펴보시죠.
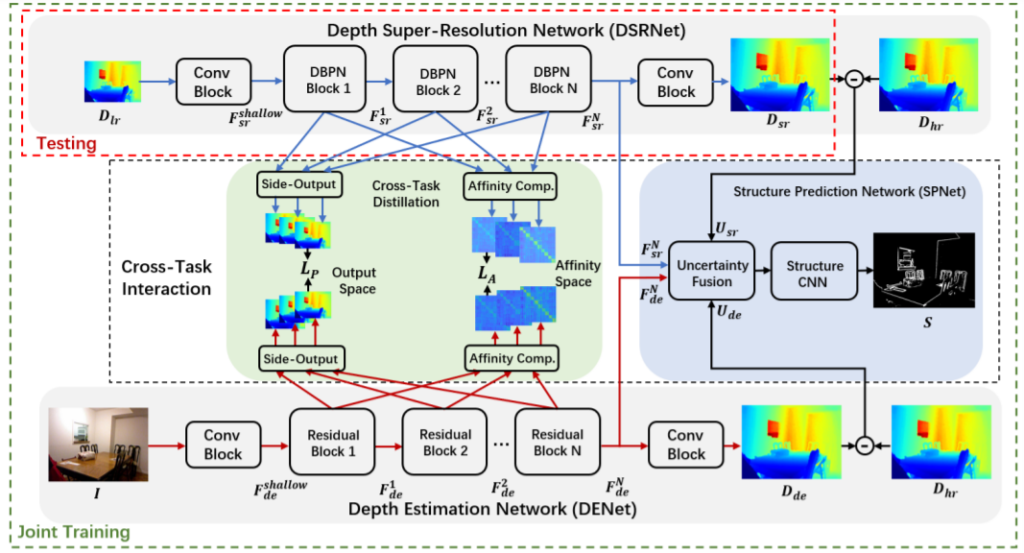
학습 과정에서 메인으로 동작하는 부분은 크게 3가지로 Depth Super-Resolution Network(DSRNet), Depth Estimation Network(DSNet) 그리고 Cross task interaction module 입니다.
D_{lr}, D_{hr}, I는 각각 저해상도, 고해상도 Depth map과 RGB 영상을 의미합니다. DSRNet의 경우 D_{lr}을 입력으로 하여 D_{hr}과 유사한 결과를 만드는 방향으로 학습할 것입니다.
DSRNet은 Deep Back-Projection Network라는 DBPN 네트워크 구조를 그대로 사용했다고 합니다. 해당 네트워크가 HR representation을 LR spatial domain에 반복적으로 투영함으로써 보다 효율적으로 feature 표현력을 좋게한다고 하는데 SR 분야에서 좋은 성능을 보이는 네트워크인 듯 합니다.
아무튼 이러한 DBPN 네트워크 블록을 들어가기 전에 먼저 D_{lr}은 3개의 컨볼루션 레이어를 통과하게 됩니다. 그리고 N개의 DPBN 블록을 통과 후 다시 컨볼루션 블록을 통과함으로써 최종적인 HR map을 reconstruct 합니다.
DENet의 경우 DSRNet과 구조는 거의 유사합니다. 하지만 SuperResolution을 하는 네트워크가 아니기 때문에, DBPN 블록들을 모두 residual block으로 변경해주었습니다.
cross-task interaction module의 경우 DSRNet과 DENet을 이어주는 다리 역할이라고 보시면 될 것 같습니다. 여기서는 양방향으로의 knowledge transfer를 진행하게 되는데, 크게 cross-task distillation scheme과 structure prediction network(SPNet)으로 구성되어 있습니다.
먼저 전자는 각각의 네트워크(DSR, DENet)에서 추출된 multi-scale feature들 사이에 상호작용을 초점을 두었으며 후자는 structure map을 생성함으로써 양쪽 네트워크의 structure를 지도 학습 기반으로 학습시키기 위해 사용됩니다.
Cross-Task Distillation
일반적인 Knowledge distillation은 대부분 한쪽 네트워크(Teacher)가 다른 쪽 네트워크(student)보다 항상 더 좋은 성능을 지니고 있으며 이러한 Teacher network는 freeze 시킨 체 student network를 학습하는데 도와주는 역할로 사용하게 됩니다.
하지만 제안하는 방법론에서는 DSRNet과 DENet이 Teacher-Student 관계가 아닌 서로의 task를 학습하고 비교함으로써 같이 성장?해나가는 collaborative한 성향을 지니고 있습니다. 약간 multi-task learning같은 느낌이라고 보시면 될 것 같네요?
그래서인지 어떤 네트워크가 항상 더 뛰어난 성능을 보이는 것이 아니기 때문에, 이전 라운드에서 성능이 더 뛰어난 네트워크가 현재 라운드에서 teacher 역할을 하는 등 매번 teacher와 student가 그때그때 성능 향상이 되는 정도에 따라 결정된다고 합니다.
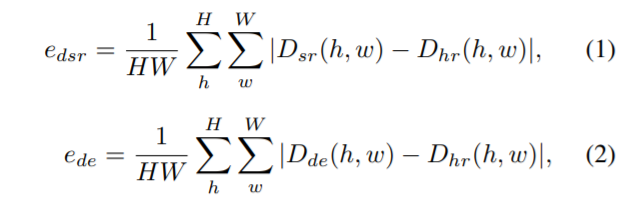
위에 수식들은 각 네트워크에서 추정된 depth map의 평균 픽셀 에러 값을 표현한 것인데, 만약 e_{dsr}이 e_[de}보다 더 작다면, DSRNet이 상대적으로 더 좋은 성능을 보이고 있기 때문에 DENet의 teacher가 되어서 guide를 해주게 되는 것입니다. 물론 그 반대의 경우도 있겠구요.
Output Space Distillation
Depth map 내부에 pixel wise depth value들이 local information을 서로 transfer 했는지를 확인하기 위해 저자는 DSRNet과 DENet으로 부터 side output layer를 적용하여 대응되는 multi-scale depth map을 생성하였습니다.
무언가 말이 조금 어려웠는데 쉽게 말하자면 각 네트워크들에서 나온 multi-scale의 feature map에 side output layer라는 컨볼루션을 태워서 scale별 depth map을 만들었다는 뜻입니다.
그러고나서, output space의 distillation loss를 계산하기 위하여 아래 수식과 같이 DSRNet과 DENet 사이에 feature를 간접적으로 align하도록 설계하였습니다.
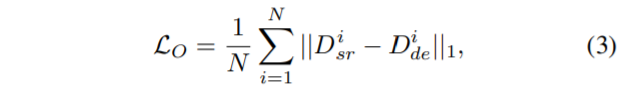
Affinity Space Distillation
Color Image와 이에 대응하는 Depth map은 동일한 scene을 바라본다 하더라도 서로 다른 속성(Texture, color 등)을 가지고 있습니다만 그래도 완벽히 동일한 scene이기에, structural similarity가 매우 유사해야만 합니다.
Feature F의 shape을 w \times h \times c 라고 하고, \mathds{R}(F) 는 feature를 reshape하여 wh \times c로 만든 feature라고 합시다.
그럼 affinity matrix A를 다음과 같이 정의합니다.
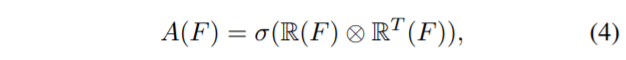
여기서 시그마는 softmax의 해당하구요, feature map들은 서로 행렬곱을 진행하게 됩니다. 그래서 결과적으로 affinity space에서의 distillation loss 계산은 다음과 같이 진행됩니다.
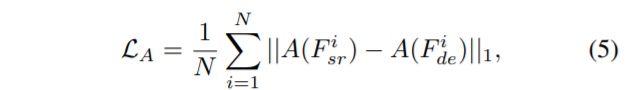
최종적으로 Total Distillation loss는 다음과 같습니다.
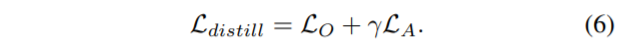
distill loss는 반드시 student에만 적용이 되고 teacher network에는 적용이 되지 않습니다. 그리고 위에서도 설명드렸다시피 이러한 teacher와 student를 정의하는 기준은 평균 error값 e_{dsr}, e_{de}를 통해 결정합니다.
Structure Prediction
마지막으로 SPNet에 대해 알아봅시다. SPNet은 DSRNet과 DENet에서 생성된 제일 마지막 feature map으로부터 structure map S를 추출합니다. 학습 방식은 GT structure map S^{2}_{gt}을 통해 supervision 방식으로 학습하며 이렇게 학습된 SPNet은 DSRNet과 DENet이 보다 structure representation을 잘 학습하게끔 하여 RGB-D structure inconsistency 문제를 해결해준다고 합니다.
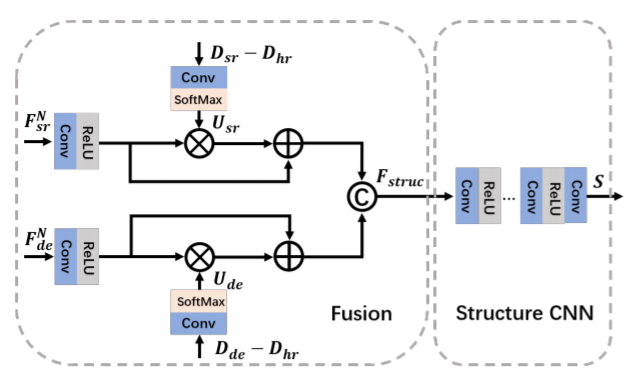
그림2와 같이 SPNet은 fusion module과 structure CNN으로 구성되어 있습니다. 보통 DSR과 DE 네트워크에서 생성된 결과 중 대부분의 오차들은 주로 물체의 경계면 부근 또는 fine structure에서 발생합니다.
그래서 저자는 단순히 F_{sr}, F_{de}를 concat하는 것이 아니라, feature map의 불확실성을 회복할 수 있도록 attention을 줌으로써 보다 structure 정보를 잘 표현할 수 있게끔 모듈을 설계했다고 하는데, U_{sr}, U_{de}라는 uncertainty map을 아래와 같이 계산하여 사용합니다.
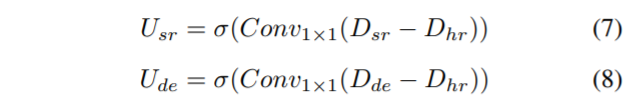
예측된 Depth map과 GT Depth map을 빼준 후 1×1 컨볼루션을 적용해줍니다. 그 다음에 softmax를 적용한 것이 uncertainty map이 되는 것이구요, 이렇게 구한 맵을 통해 Feature map에 가중치를 새로 적용해주기 위하여 아래와 같은 fusion 과정을 거치게 됩니다.
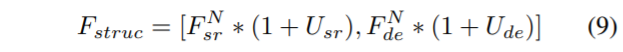
대괄호는 concatenation을 나타낸 연산이며, * 는 element-wise multiplication을 의미합니다. 이러한 SPNet을 학습시킬 때 발생하는 gradient는 DSRNet과 DENet의 파라미터 업데이트에도 영향을 주게 됩니다.
위에 내용들에 대한 학습 과정을 요약하면 다음과 같습니다.
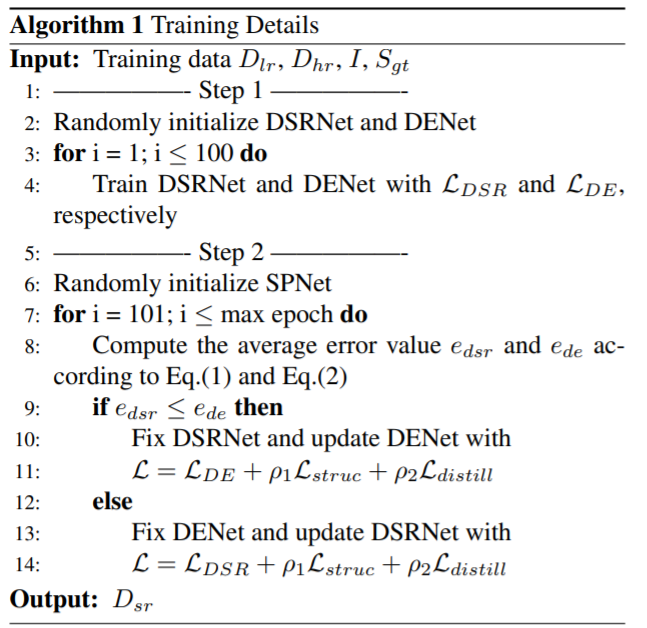
DSR을 학습시킬 때는 단순히 L1 loss를 사용하며, DENet을 학습시킬 때는 reconstruction loss와 structural similarity (SSIM) loss를 섞어서 사용하게 됩니다.
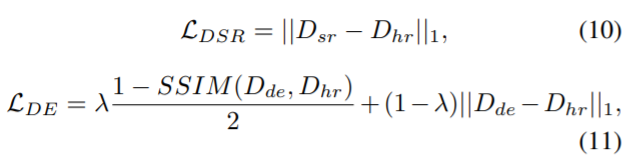
Experiments
평가용 데이터로는 크게 Middlebury, MPI Sintel, NYUv2, ToFMark 데이터 셋을 사용했습니다.
아무래도 RGB-D paired한 데이터 셋을 사용하다보니 실외보다는 실내에서 촬여된 데이터셋으로 학습 및 평가를 진행하였네요.
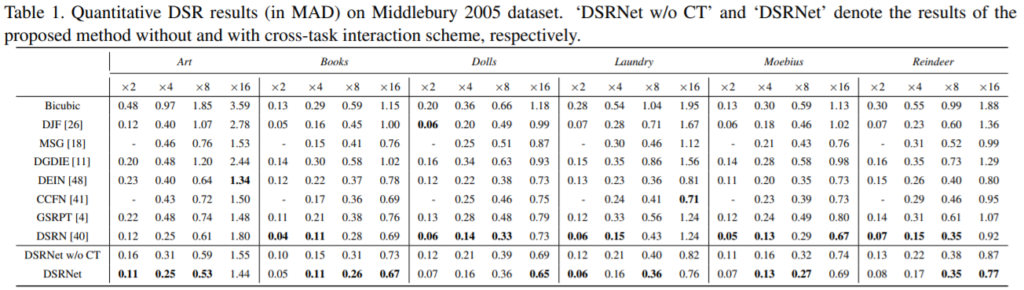
표 1은 Middlebury dataset에 대한 정량적 결과를 요약한 것입니다. ‘DSRNet w/o CT’와 ‘DSRNet’은 cross-task interaction scheme이 있고 없고에 따른 차이입니다.
DSRN이라는 방법론이 아마 이쪽 분야에서 가장 최근에 나온 SOTA 방법론인 것 같은데, 저자는 해당 방법론과 자신들의 방법론의 성능이 비슷하거나 더 좋고 있으며 추가로 자신들의 방법론은 평가 시 RGB 이미지 없이 Depth image만 있으면 된다는 것을 강조하며 성능향상과 단일 modality만으로 평가한다는 장점을 강조합니다.
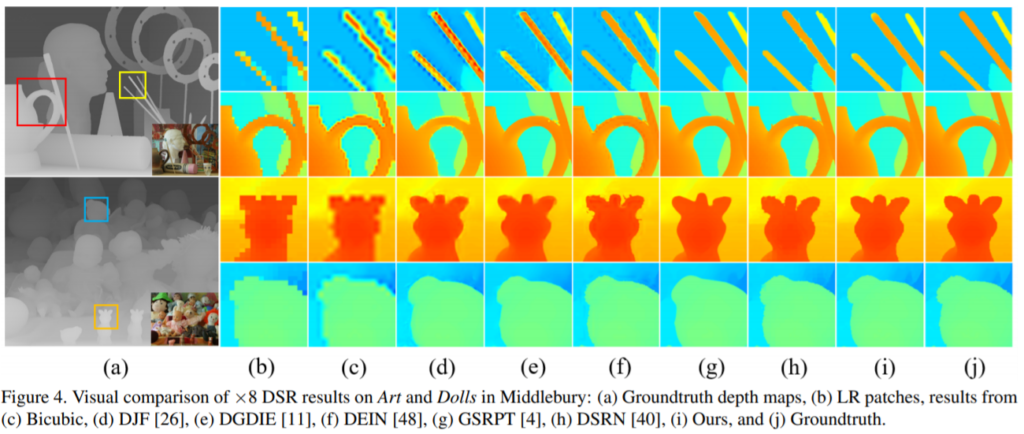
위에 그림은 GT depth map (a)에 대하여 patch 단위로 쪼개서 각 방법론에 따른 결과를 정성적으로 본 것입니다. edge 가장자리가 선명하게 잘 살아있네요.
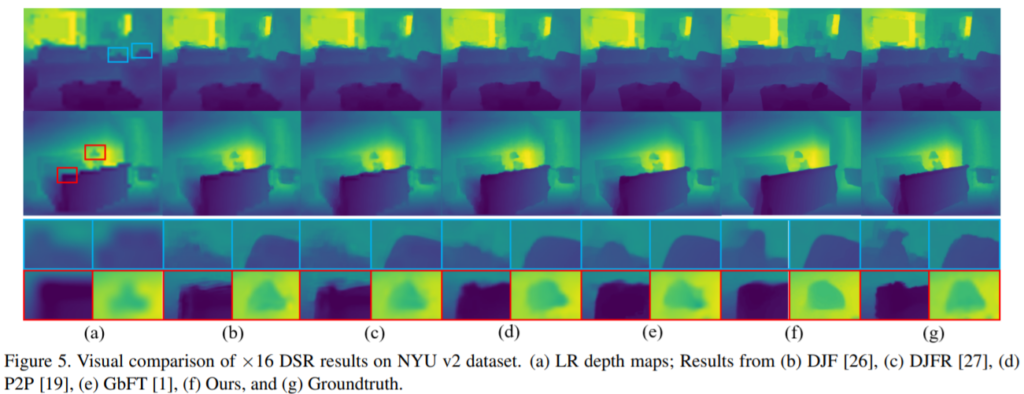
해당 결과는 NYU v2 dataset의 결과입니다.
리뷰 감사합니다. 결국에 Testing time에서는 DSR Net을 사용하는데,, 음… DENet이 testing 이 되어야하는거 아닌가여..? 제가 전체적인 목적을 잘못이해한걸까요..?