

Weakly-supervised Temporal Action Localization 분야는 video-level의 label 만으로 untrimmed video에서 Action의 위치를 찾고 분류하는 분야입니다. 실상 Localization보다는 Detection에 가까우며 Weakly-supervised Temporal Action Detection이라고도 불리우기도 합니다. 해당 분야에서 temporal segment 정보 없이 문제를 풀어나가기 위해 frame-level 혹은 snippet-level의 classification 후 localization 하는 과정을 많이 거치게 됩니다. 그러나 이와 같은 방법에서는 temporal context relation이 온전히 활용되지는 않기에 classification 하기 힘든 hard snippet이 나타나게 되고 결국 localization 성능 또한 저하됩니다. 오늘 리뷰할 논문은 이를 해결하기 위해 hard snippet mining을 통한 Contrastive Learning인 Contrastive learning on hard snippets to Localize Action (CoLA)를 제안하였습니다.
1. Method
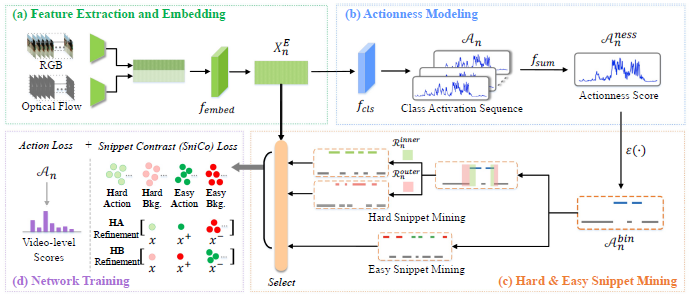
1.1 Feature Extraction and Embedding
제안된 CoLA의 프레임워크에서는 우선 video에서 snippet-level의 feature를 추출하게 됩니다. 주로 Temporal Action Localization 분야에서는 뒷단의 성능 향상을 보여주기 위해 앞단 backbone network는 I3D와 optical flow를 동일하게 사용하는 경향성을 보이는데, 본 논문도 마찬가지로 RGB feature와 optical flow feature를 추출하고 concatenate 한 뒤 embedding 하여 사용합니다.
1.2 Actionness Modeling
추출된 snippet-level의 embedding feature로 해당 feature가 action을 포함하는지 아닌지 판단하는 actionness modeling 과정을 거칩니다. 주로 이미지에서 weakly-supervised object detection 문제를 해결할 때 Class Activation Map을 사용하는 것과 같이, actionness modeling 시에는 이와 유사하게 Temporal Class Activation Sequence (T-CAS)라는 것을 활용합니다. 이는 단순히 FC Layer를 활용해 embedding feature를 class 수만큼의 차원으로 줄이는 것이며, 모든 class에 대한 값을 합한 뒤, Sigmoid를 거쳐 actionness score를 생성합니다.
1.3 Hard & Easy Snippet Mining
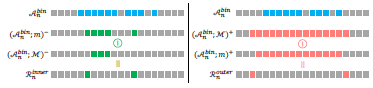
기존 Weakly-supervise Temporal Action Localization의 문제인 hard snippet 문제를 해결하기에 앞서 hard snippet을 정의하는 과정이 필요합니다. Boundary를 판단해야하는 Action Detection(Action Localization)에서는 Background로 변경되는 지점에 존재하는 snippet의 경우가 Action 혹은 Background 내의 snippet 보다 모호한 경향을 보이기 때문에, 논문에서는 예측된 action 영역에서 Boundary에 인접한 snippet을 hard snippet으로 정의하였습니다.
좀더 자세하게 먼저, 앞서 구해진 actionness score를 thresholding 하여 action 영역을 선정하였습니다. 그리고 action 영역 내의 hard snippet인 hard action과 background 영역 내의 hard snippet인 hard background로 구별하고 침식과 팽창 알고리즘으로 이를 선정하였습니다. Hard action의 경우 Fig 3의 왼쪽과 같이 서로 다른 크기의 mask로 침식 알고리즘을 적용해 나온 두 결과의 차이인 snippet으로 선정되었으며, hard background의 경우 Fig 3의 오른쪽과 같이 서로 다른 크기의 mask로 팽창 알고리즘을 적용해 나온 두 결과의 차이인 snippet으로 선정되었습니다.
앞선 과정으로 hard snippet mining 을 마친 후, 이를 학습하기 위한 contrastive pair 선정을 위해 easy snippet mining 과정도 진행하게 됩니다. Hard snippet mining보다 단순하게, Easy snippet의 경우 backbone network가 잘 학습되어있다는 가정하에 actionness score가 높은 top-k snippet을 easy action, bottom-k snippet을 easy background로 선정하였다고 합니다.
1.4 Network Training
앞서 설명된 CoLA를 학습하기 위한 Loss로는 Action Loss와 Snippet Contrast Loss로 구성됩니다.
Action Loss의 경우 1.2 절에서 언급된 T-CAS를 활용하며, 한 video에서 나온 모든 snippet의 T-CAS 중 class 별로 top-k mean하여 video-level의 prediction으로 변경해 활용합니다. 이는 여러 Weakly-supervised Temporal Action Detection에서 사용하던 방식을 따라하였다고하며, 이렇게 얻은 video-level prediction과 video-level label 사이의 에러를 CrossEntropy로 계산하여 Action Loss로 선정합니다.
SniCo(Snipet Contrast) Loss 의 경우, HA(Hard Action) refinement term과 HB(Hard Background) refinement term으로 구성되며, 각 term은 triplet 으로 구성됩니다. HA refinement term의 경우 Fig 2의 (d)에서 볼 수 있듯이, hard action과 easy action은 가깝게 easy background와는 멀게 설계되며, HB refinement term의 경우 hard background와 easy background는 가깝게 easy action과는 멀게 설계됩니다. 식 (1)이 두 term에서 loss 계산하는 방식을 나타내며 x^{+}는 각 term에서 가깝게 만드는 Positive, x^{-}는 각 term에서 멀게 만드는 Negative를 의미합니다. S는 Negative의 수를 의미하며, /tau는 softmax의 값을 smoothing하는 temporature를 의미하며 0.07로 사용하였다고 합니다.
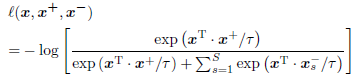
1.5 Inference
학습 시와 유사하게 각 snippet 별로 구해진 T-CAS에서 class 별로 top-k mean을 구한 뒤, 그 중 가장 큰 값으로 해당 snippet의 prediction을 선정하고 이를 thresholding 하여 action인지 background인지를 판단하게됩니다. 그리고 action으로 판단된 snippet 중 같은 class를 나타낼 경우 grouping하여 proposal을 생성하고 생성된 proposal들을 NMS 처리하여 최종 output을 선정하게됩니다.
2. Experiments
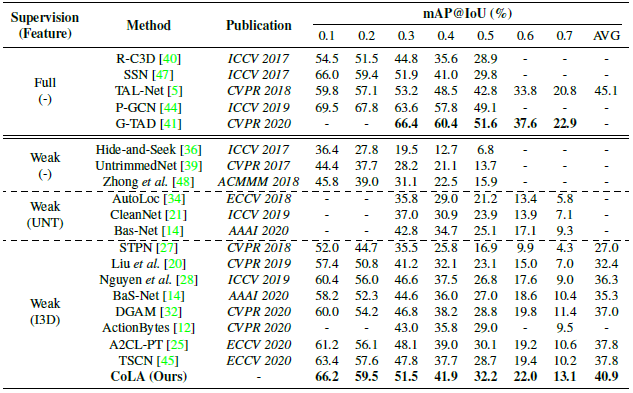
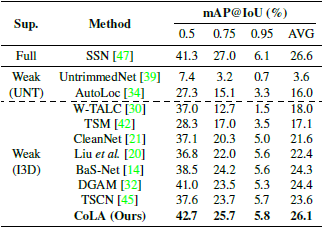
Table 1과 2는 각각 THUMOS 14 데이터 셋과 ActivityNet v1.3 데이터 셋에서의 Action Detection 성능입니다. 같은 Weakly-supervised Temporal Action Localization 성능과 비교했을 때 SOTA의 성능을 달성하였으며, 특이한 점으로는 Full-supervised Tmeporal Action Localization과도 비슷한 성능을 보였습니다.
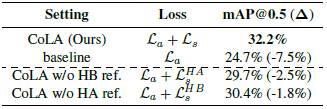
Table 3은 제안된 CoLA의 Loss 중 SniCo Loss에서 각 term을 제거했을 때의 성능 차이 입니다. 두 term을 각각 제거했을 때도 성능 하락을 보였으며 SniCo Loss 자체가 제거되었을 때 성능 하락 폭이 매우 커, 제안된 mining 방식이 매우 효과적이었음을 알 수 있습니다.

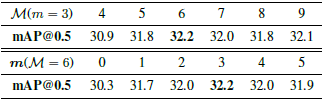
Table 4는 Negative 수에 따른 Ablation study로 가장 큰 값인 125일 때 제일 좋은 성능을 보였다고 합니다. 그리고 Table 5는 hard snippet mining 시 사용되는 mask 크기에 따른 ablation study로 각각 3, 6일 때의 성능이 가장 좋아서 제안된 CoLA에서는 해당 값으로 선정하였다고 합니다.
a more separable feature distribution compared to baseline.
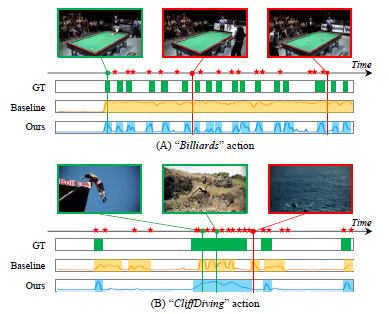
Fig 4 왼쪽은 SniCo Loss를 사용하기 전, 오른쪽은 제안된 방식으로 학습하였을 때 feature가 embedding되는 것을 visualization한 실험 입니다. 실제로 판단이 어려웠던 hard action과 hard background가 보다 구별된 것을 볼 수 있습니다. 그리고 Fig 5는 CoLA로 Action Detection 했을 때의 정성적 결과 입니다.
3 Reference
[1] https://arxiv.org/pdf/2103.16392.pdf
좋은 논문 소개 감사드립니다. framework 에서 각 class에 대한 존재 가능성을 이용하여 actionness 를 생성하는것으로 이해했는데, 이를 합치지 않고 이용하는 것이 action detection task 에서 더욱 도움이 되지 않는지 궁금합니다!
따로 그부분에 대한 ablation study는 존재하지 않으나 따로 사용하지 않고 합친 이유를 추론해보자면, actionness score 라는 것은 모든 action을 포함해 하나라도 발생할 가능성을 값으로 표현한 것인데 이를 따로 사용하게 되면 network가 학습시에 action이 발생했는지 안했는지에 집중하기보다 어떤 action인지에 좀더 집중할 것 같아 합쳐서 사용한게 아닌가 싶습니다.