이번에도 어김없이 Self supervised depth estimation 논문을 들고 오게 되었습니다.
이번 논문은 Conference 논문이 아닌 journal 논문입니다. 이 논문 또한 저번에 리뷰한 논문 (DDV) 와 동일하게 Depth generate model 을 메인 컨트리뷰션이며 거의 대부분을 차지 하는데요, 이는 현재 제가 실험하고 있는 상황이랑 거의 동일하여 읽게 되었습니다. 사실 내용이랑 성능이 완전 드라마틱하지는 않아 가지고 좋은 저널이 아닌가 보다 했는데 TIP가 무려 IF가 20이 넘는 저널이라 해서 제 방법론에 희망이 있다는 것을 살짝 느꼈다는 건 후문입니다. . . ㅎㅎ 잡설은 차치하고 방법론에 대한 설명으로 넘어가도록 하겠습니다.
이 논문이 제안하는 방법은 Attention 방법을 이용한 Depth estimation 성능 향상입니다. Attention 방식을 Global 하게 적용하기도 하고 local 하기도 적용하여 디테일과 성능 모두 챙겼다고 합니다.
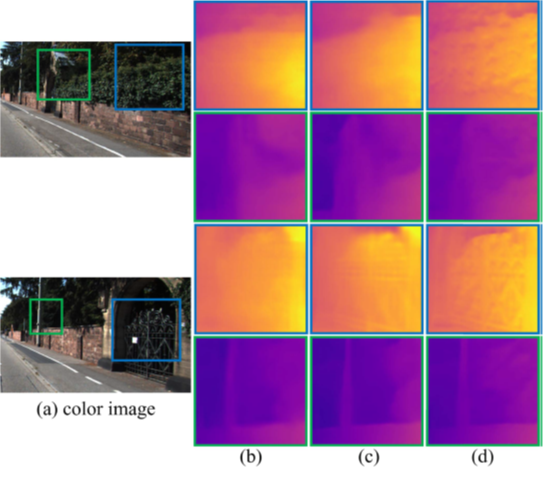
정성적 그림으로 보면 확실히 Monodepth2 보다 철장의 디테일이라던가 풀숲의 디테일이 살아있는 것을 볼 수 있습니다. 이와 같은 성능을 내기 위한 컨트리 뷰션을 정리하면 다음과 같습니다.
- 다양한 스케일의 영상을 입력으로 받아서 사용하는 Multi Level Feature Fusion(MLFE) 모듈을 통해서 고품질의 깊이 영상을 제작한다.
- Global Attention 과 Struct Attention 을 이용해서 Global feature와 local feature를 잘 융합한다.
- Multi scale 방식의 Loss 를 효과적으로 다루기 위한 re-weighed loss 방법을 제안한다.
Method
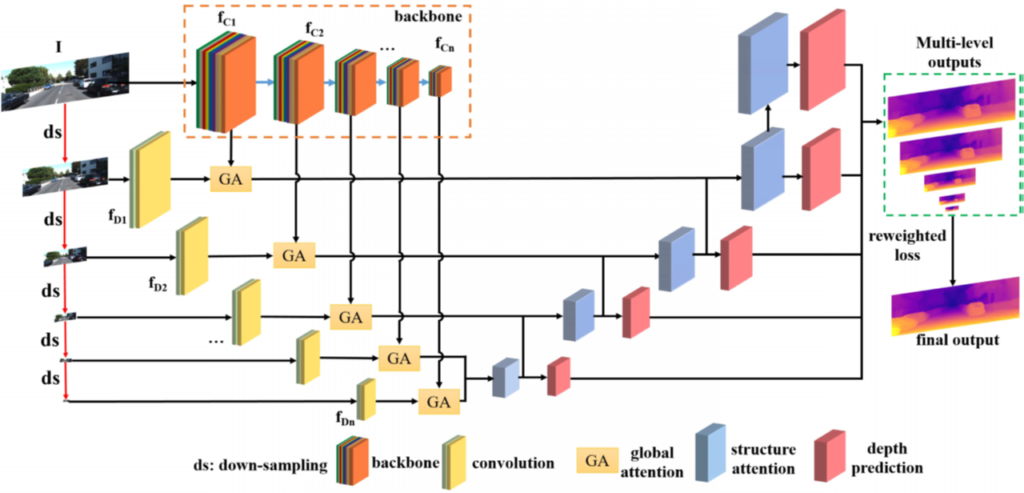
1.MLFE
기존에는 encoder feature를 backbone network에서 나온 것 만을 사용하지만 이 논문에서는 실제 영상 또한 feature로 사요하여 더욱 풍부한 정보를 담고자했다고 합니다. 위 아키테쳐에서 fc와 fd 로 나눠서 feature를 뽑는 과정을 MLFE mlti level feature extraction 이라고 합니다. 이렇게 추출한 두 feature를 합치는 방식을 Attention 방식으로 처리후 합치게 됩니다. 그 과정을 아래 Dual Attention에서 Global Attention에 해당합니다.
2. Dual Attention
2.1 Global Attention
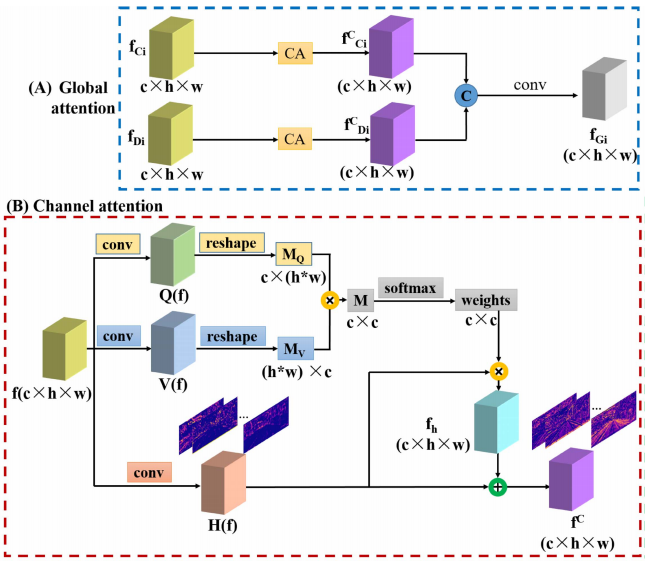
이미지로부터 추출한 두 feature fc와 fd는 Global Attention 방식으로 합치게 됩니다. 그 방식은 위 그림과 같습니다. fc와 fd 둘다 Channel Attention와 Conv를 통과한 후 concate 하여 합쳐지게 됩니다. Channel attention 방식을 기존 Self-attnetion 방식과 동일하게 Query, key , value로 나눈후 진행하게 됩니다. 위 과정을 통해서 각각의 feature의 정보가 강력하게 만들어줍니다.
2.2 Structure Attention
Upconv 할때 생기는 Edge의 모호성이과 전체적인 blur를 바로 잡기위한 방법론을 제안한다고 합니다. 이는 아래 그림과 같습니다.
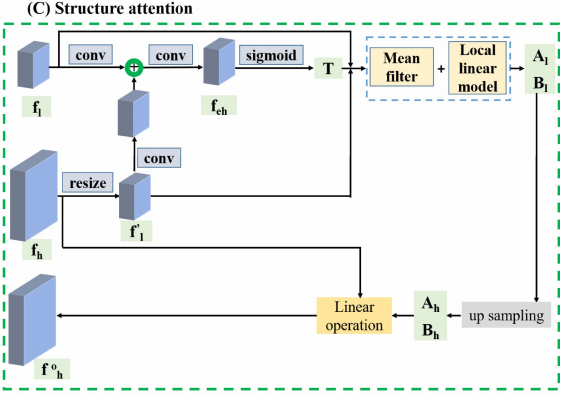
fh는 highresolution feature이며 fl을 low resolution feature입니다. 그림2를 보면 structure attention module 에서 두가지 scale feature를 사용하는 것을 볼 수 있습니다. 보다 큰 스케일의 feature인 fh를 downsampling 한 후 fl과 유사하는 Al과 Bl을 구함으로써 Upconv시 생길 수 있는 손실 값들을 보충합니다.
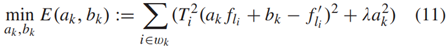
위와 같은 식을 이용해서 fli와 f’li가 유사해지도록 하는 Ti와 ak,bk를 구한 후 upsample 하면 Ah와 Bh를 얻을 수 있습니다. 그런 다음 아래 식과 같이 최종 high resolution feature를 보완한 f’h를 얻을 수 있습니다 이 feature를 conv와 sigmoid를 통해서 최종 disp를 얻게 됩니다.
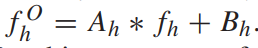
3. re-weighted loss
기존에는 Multi scale output에서 구한 loss를 단순히 더하지만 이 논문에서는 아래 식과 같이 큰 스케일의 output에 더욱 큰 weight 를 줌으로써 최종 disprity의 성능을 끌어 올렸다고 합니다.
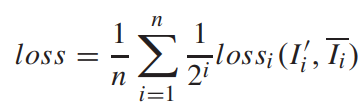
Result
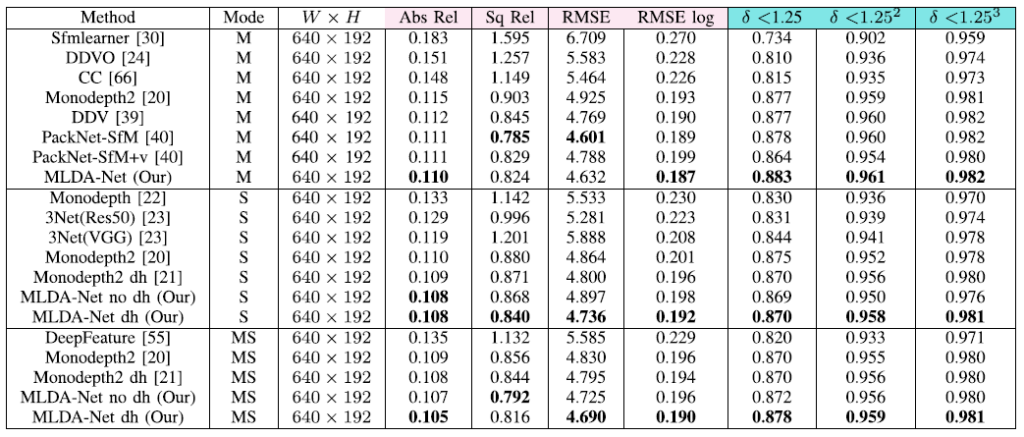
KITTI에서의 성능 평가 입니다 . Resnet18을 backbone으로 사용하는 모델들을 비교했다고 합니다. 큰 폭의 성능향상이 아닌 것 같아서 살짝 아쉽긴 하지만 그래도 좋은 성능을 보이고 있습니ㅏㄷ.
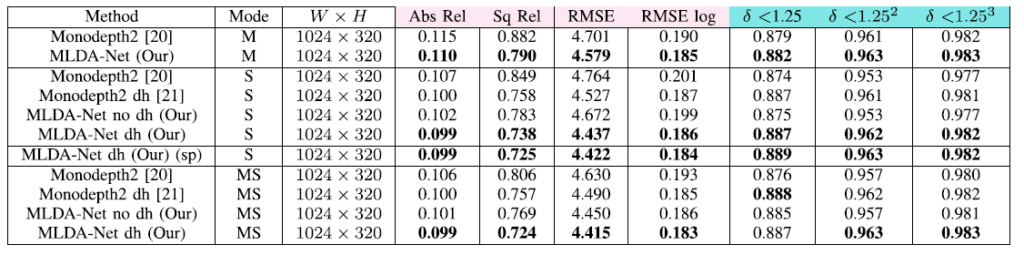
High-resolution에서 성능 평가 입니다. PackNet의 경우 Abs_rel의 경우 약 0.107 정도로 이 논문에서 제안하는 방법론 보다 좋은 성능을 보이는데 Monodepth2와 비교만 한 것이 아쉬운 것 같습니다.
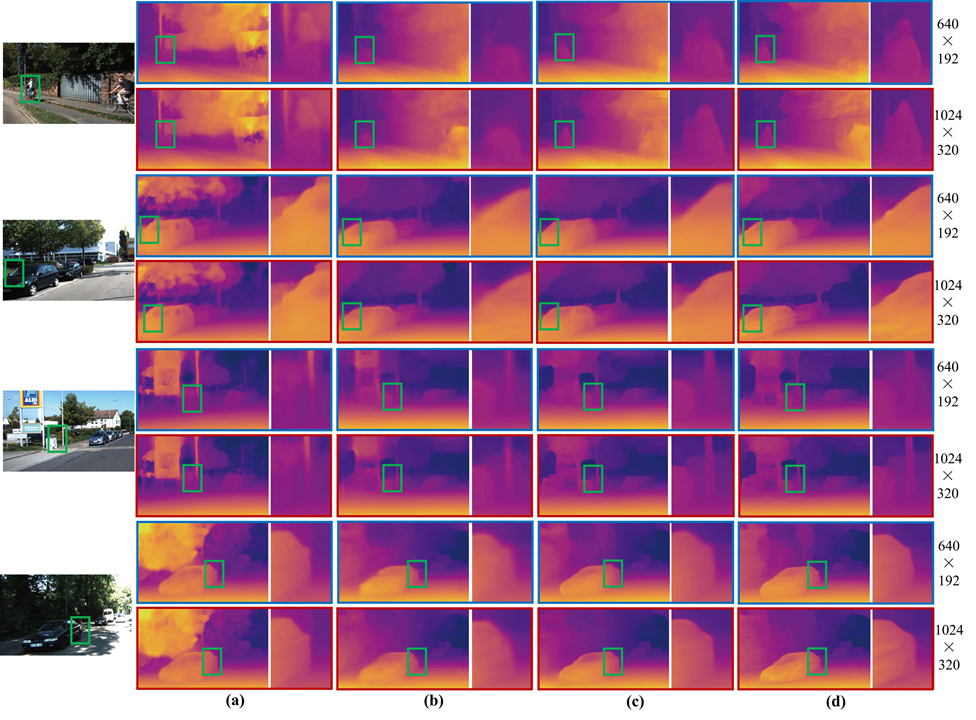
정성적 결과를 보면 확실히 Monodepth2 보다 물체의 경계가 산 것을 볼 수 있습니다.
Ab