논문 링크 : https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8803551
Abstract
이 논문은 장면 내에서 개별적으로 선택된 객체 그룹에 대한 깊이를 추정하기 위해 함께 훈련된 픽셀 단위 의미론적 이해를 이용하는 단안 깊이 추정 방식을 제안한다. 각각의 depth 예측 결과는 효율적으로 융합해 최종 결과를 도출해낸다. 공동으로 학습된 개별 네트워크는 각 object에 대해 단순화된 학습이 되어 전체적으로 더 정확한 깊이를 추정할 수 있다.
Introduction
RGB 이미지를 이용해 먼저 의미론적으로 장면을 이해하고 그 이해를 바탕으로 각 부분의 depth를 예측한다. 그리고 각 부분별로 생성된 depth는 이후에 간단하게 합쳐지고 이후에 적대적 학습을 통해 전체적 일관성이 제어된다. 이는 각 부분을 분리하여 depth에 대한 학습을 진행하면 각 객체별로 단순화된 목표를 가지고 depth를 학습하기 때문에 전체적으로 성능이 향상될 수 있다.
Contributions
- 단안 깊이 추정을 더 강화하기 위해 사전에 픽셀 단위의 scene segmentation을 이용
- 동일한 모델 내에서 공동으로 학습된 semantic segmentation에 기반해 각 부분에 대한 깊이를 추정하여 전체 모델에 대해 end-to-end로 학습
- 단안 깊이 추정 방식으로 정확하고 dense한 장면의 깊이를 생성할 수 있음
Approach
전체 장면들을 포괄하는 개별 객체를 그룹 지어 깊이를 추정한다. 경험적 분석을 통해 물체를 네 그룹으로 구분했다. 작고 좁은 전경 물체(보행자, 도로 표지판, 차, L_{1}), 평평한 표면(도록, 건물, L_{2}), 식물(나무, 덤불,L_{3}), 나머지 배경을 구성하는 물체(포장 도로위의 벤치처럼 라벨이 없는 물체,L_{4})
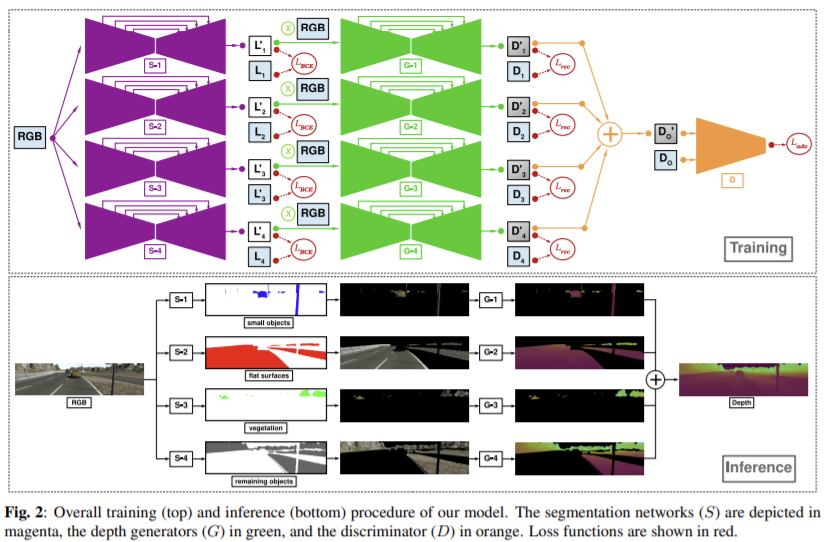
입력 이미지는 segmentation network (S)을 이용해 분할되고 이는 depth generators (G)에 입력으로 전달되는 RGB 이미지의 영역을 선택하는데 사용되며 (G)를 통과해 각 객체 그룹(D_{1}, D_{2}, D_{3}, D_{4})에 대한 깊이 정보를 생성한다. end-to-end로 학습되고 학습에는 depth와 픽셀 단위의 segmentation 라벨 GT가 있어야 한다.
1. Semantic Segmentation
RGB 이미지는 모든 segmentation 네트워크의 입력으로 사용되고 각 네트워크는 특정 객체 그룹에 대한 클래스 라벨을 출력한다. sigmoid 함수는 binary cross-entropy와 함께 각 네트워크의 loss 함수로 사용된다.
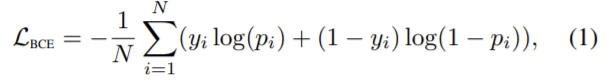
N은 픽셀 수, y는 GT라벨, p는 예측된 확률을 의미한다. 각 segmentation 네트워크에서 구한 loss는 다음 식으로 계산해 전체 segmentation loss를 구한다.
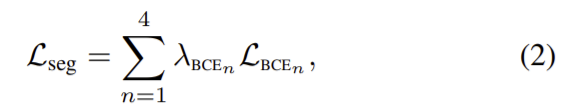
λ_{BCE_{n}}은 실험적으로 구한 가중치값이다.
2. Monocular Depth Estimation
입력 RGB 이미지가 depth 이미지로 변환되는 supervised 방식의 image-to-image 매핑 문제로 고려한다. 수식적으로 나타내면 depth 발생기 (G)는 RGB 이미지 x를 입력으로 하고 출력을 depth 이미지 y로 하는 매핑 함수G: x → y로 근사시킬 수 있다. 네트워크는 GT와 출력 픽셀 값 G(x)의 유클리드 거리를 최소화 하여 GT와 유사한 depth값을 갖도록 하는 것이 목표이다. reconstruction loss는
\mathcal{L_{rec_{n}}}=||G_{n}(S_{n}(x) × x)-(S_{n} × y)||_{1} \quad (3)
이고 이때 S_{n}은 segmentation 네트워크, x는 RGB 이미지, y는 GT depth
전체 loss는 다음 식으로 나타낼 수 있다. 이때 λ_{rce_{n}}도 실험적으로 구한 가중치값이다.
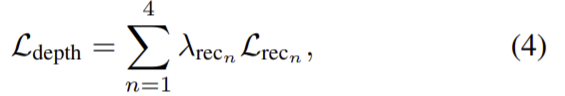
구한 depth들은 단순히 더하는 방식을 이용해 전체 depth를 구한다. D_{O}=\sum\limits_{n=1}\limits^{4}{D_{n}} 이처럼 간단한 선형 연산을 하게되면 stitching 효과, depth 값의 과포화, depth의 비균질 등의 문제가 생길 수 잇다. 따라서 이를 방지하기 위해 최종 depth 이미지의 전체적 일관성을 보장하는 적대적 loss 부분을 도입해 전체 depth의 합을 discriminator의 입력으로 사용한다. 전체 모델(GO)는 전체 장면의 depth 출력을 만들 때(G_{O}(x)=\tilde{y}), discriminator (D)는 만들어진 가짜 depth \tilde{y}와 GT depth y를 구별하도록 학습되었고 적대적 loss는 다음으로 정리된다.
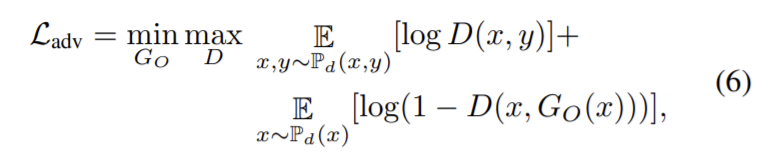
전체 loss는 다음으로 정리된다.
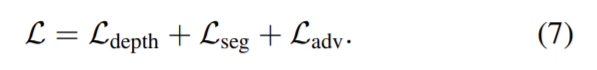
Experiment
- RGB, depth, 픽셀 단위 label을 갖는 합성 이미지로 학습 (<The SYNTHIA dataset: A large collection of synthetic images for semantic segmentation of urban scenes> 데이터셋과 <Vision meets robotics: The KITTI dataset> 데이터셋 사용)
- 모든 segmentation, depth generator 네트워크는 encoder-decoder 구조
(encoder와 decoder는 대응되는 모든 쌍이 skip connection을 포함함) - discriminator는 <A. Radford, L. Metz, and S. Chintala, “Unsupervised representation learning with deep convolutional generative adversarial networks,”>의 구조를 따르며 segmentation, depth 네트워크와 유사하게 convolution-BatchNorm-leaky ReLU (slope = 0.2) 모듈을 이용
- Adam optimization 이용 (β1 = 0.5, β2 = 0.999, α = 0.0001 최상의 최적화)
- λ_{BCE_{1}} = 100, λ_{BCE_{2}} = 1, λ_{BCE_{3}} =10, λ_{BCE_{4}} = 1
- λ_{rec_{1 }}= 100, λ_{rec_{2}} = λ_{rec_{3}} = λ_{rec_{4 }}= 10
Ablation study
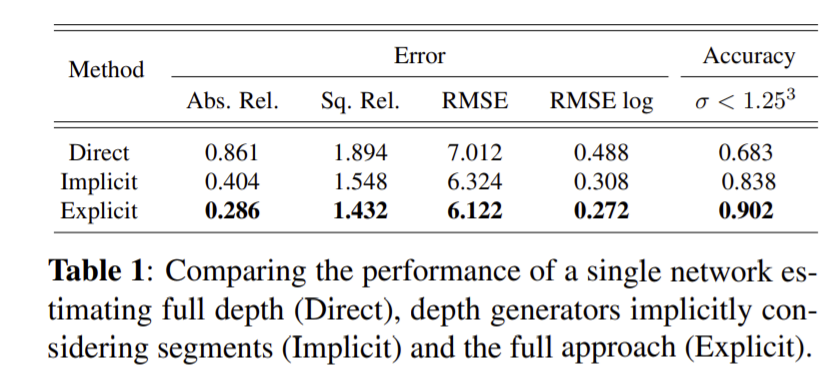
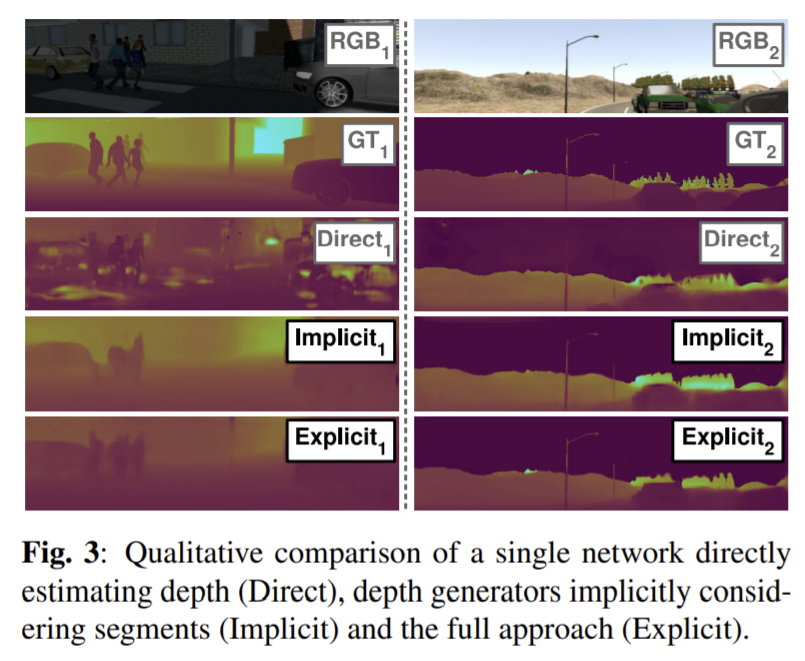
하나의 depeth estimation 모델(Direct), segmentation을 명시적으로 하지 않고 암묵적으로 segmentation을 나눠 depth generator를 이용하는 모델(Implicit), 명시적으로 segmentation을 수행한 뒤 depth generator를 이용하는 모델(Explicit)을 통해 제안한 모델의 복잡성이 필수임을 증명한다. 이때 Implicit 방식의 reconstruction loss는 \mathcal{L_{rec_{n}}}=||G_{n}(x)-(L_{n} × y)||_{1}로 계산한다. 성능은 Explicit 방식이 성능이 뛰어난 것을 확인할 수 있다.
다른 방식과 비교
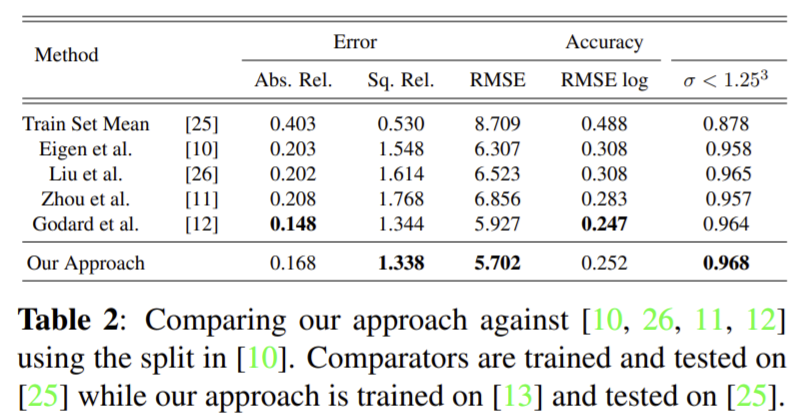

** 정리 **
- segmentation 네트워크를 통해 4 그룹으로 나눔
- depth generator 네트워크를 통해 depth를 예측
- 예측된 depth 4개를 더한 뒤 discriminator 네트워크를 이용해 depth를 조정해 최종 depth를 구함
경험적 분석을 통해 segment를 4가지 그룹으로 나눴다고 했는데 그 분석에 대한 설명이 있었으면 좋았을 것 같습니다. 또한 ablation study에서 implicit 방식이 어떻게 segmentation을 암묵적으로 진행했다는 것인지 조금 더 자세한 설명이 있었으면 좋겠습다.