Intro
이번 리뷰 논문은 monoloco ~ MonStereo의 중간 단계에 해당하는 논문에 해당합니다. 단안 영상에서 추정된 보행자의 포즈 정보를 이용하여 3차원 위치 정보를 추론하는 monoloco에서 보행자의 방향 정보를 추가로 추론합니다. 또한 저자는 해당 논문을 식에 맞게 코로나 거리두기와 연관둔 기능을 추가로 소개합니다. 이전 연구에서 사람들간 소통에 대해 분석한 F-formation을 이용하여 보행자간 거리와 소통 여부에 판단하는 모듈을 추가합니다. (참고 fig 1)
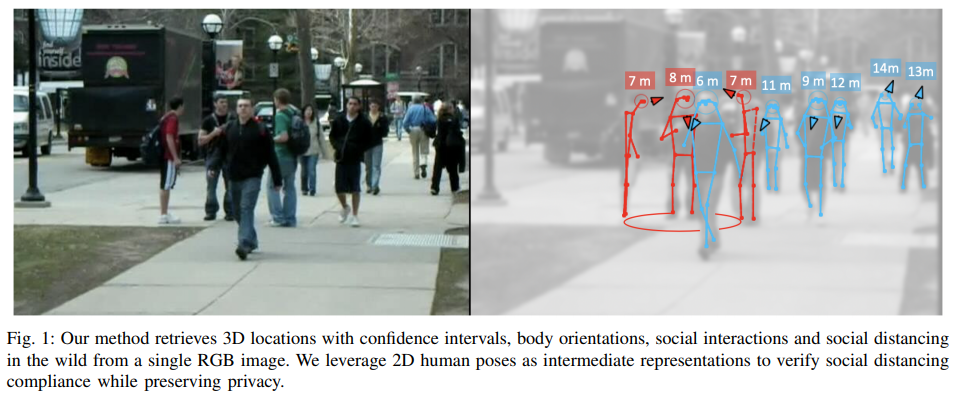
방법론에 설명하기 앞서 사회적 거리두기에 사용한 행동 과학에 포함되는 Social Interactions에 연구된 방법에 대해 소개드리고자합니다. 관련 연구에서는 사람과 사람간 소통 시, 특정한 형태로 자연스럽게 형성되는 공간 F-formations에 대해 설명합니다.

F-formation은 fig #과 같이 3가지 공간으로 구분되어집니다.
1) o-space : 원형의 빈공간을 둘러싸고 있는 참여자들의 개인 공간을 보존하기 위한 공간. 각 참석자들은 내부를 바라보는 형태로 구성되며, 해당 공간을 기반으로 관계 유형이 정의되어집니다.
2) p-space : 참가자를 포함하며, 참가자들로 형성되는 내부의 원형의 빈 공간
3) r-space : p-space 외부의 공간에 해당
각각의 관계 유형은 o-space에 따라 전형적으로 vis-a-vis(face-to-face), L-shape(corner-to-corner), side-to-side으로 구분되어집니다.
저자는 유추된 보행자의 3차원 공간과 보행자의 방향을 행동 과학을 기반으로한 F-formation을 이용하여 사회적 상호작용 및 거리 정보를 유추합니다.
Method
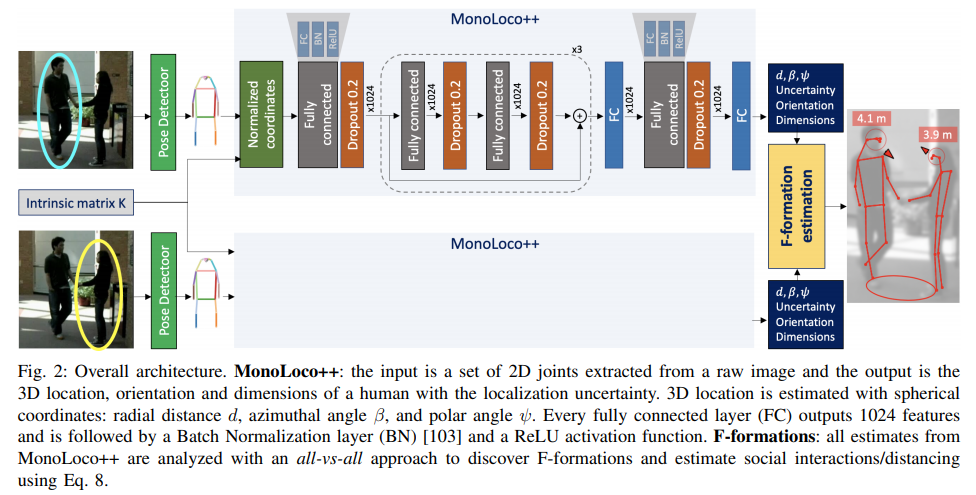
방법론은 이전에 리뷰한 Monoloco를 계승합니다.
전체적인 파이프라인을 소개하자면 아래와 같습니다.
1-3은 이전과 동일한 구조를 가집니다.
1. 우선 단안 카메라로 촬영된 영상을 입력으로 하여 off-the-shelf pose detector를 이용하여 보행자들의 pose keypoint를 추론합니다. 추론된 pose keypoint를 입력값으로 사용합니다.
2. 이전과 동일하게 각 키포인트들은 내부 카메라 파라미터를 통해 정규화된 영상 좌표로 변환 시켜줍니다.
3. 그후 Fig 2와 동일한 구조를 가진 feedfoward network를 통해 output을 획득합니다.
4. 보행자의 구형 좌표계상 3차원 위치 정보 [ radial distance d, azimuthal angle β, polar angle ψ ], 보행자의 orientation [sin α, cos α]를 예측.
이전 monoloco에서는 3차원 위치 정보 z와 uncertainty bias u만 예측했습니다. 이전 방법론과 다르게 3차원 위치의 모호성을 해결하기 위해 구형 좌표계, radial distance d, azimuthal angle β, polar angle ψ에서의 3차원 보행자 위치를 예측합니다. z와 d는 비슷해보이지만 의미하는 바가 다릅니다. z인 경우, 지면을 동일한 축으로 가진 카메라와 거리를 의미합니다. 반면에 d는 카메라 중심과 직접적은 거리에 해당합니다. 그렇기에 실직적으로 높이와 연관된 정보는 z보다는 d에서 직접적인 연관성을 띕니다.
추가로 보행자의 orientation θ를 예측 합니다. 하지만 여기서 orientation θ은 카메라 기반의 보행자가 바라보는 시점에 해당합니다. 이는 영상 관점에서 해석하면 모호성을 가져올 수 있습니다. 예시를 들면 같은 방향을 바라보는 보행자들이 촬영된 영상 위치에 따라 보행자의 형태는 상이합니다. 이를 방지하기 위해 보행자 기준의 상대적 orientation을 이용합니다. 이를 위하여 α = θ+β로 정의된 방향 정보 사용합니다. 또한 [2]에서 제안한 바와 같이 불연속성을 방지하기 위해 [sin α, cos α]로 예측. ~ 해당 부분 논문 확인 필요
5. 영상 내에 있는 모든 보행자 키포인트를 3.의 feedfoward network를 태워 (d, β, ψ), θ를 이용하여 상대적인 보행자 orientation과 3차원 위치 유추합니다.
6. F-formation estimation. 모든 보행자들로부터 추론된 정보들을 all-vs-all 방법을 통해, 사회적 상호작용과 거리 정보를 예측합니다. 사회적 상호작용 및 거리는 규칙 기반의 알고리즘으로 작동합니다. 저자는 해당 영역에 추가적으로 o-space를 동적으로 적용하는 알고리즘을 제안합니다(fig 3.)

우선 두 사람간의 o-space를 형성하기 위해서 아래의 수식과 같이 O_01과 r_{o-space}을 형성합니다.
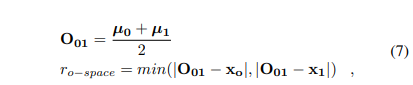
각 참석자의 o-space를 가리키는 위치 µ = [x + r ∗cos(θ), z + r ∗ sin(θ)], 여기서 사전 정의된 o-space의 radius r, 참석자의 위치 x에 해당합니다.
먼저 u는 추론된 위치 정보와 방향 정보를 기반으로 o-space의 위치를 가르킵니다. 이를 기반으로 두 참석자간의 중심을 유추 후, 참석자의 위치 정보를 기반으로 가장 가까운 위치 정보를 새로운 o-space의 radius r로 정의합니다.
++ 해당 부분이 새롭게 제안한 알고리즘입니다.
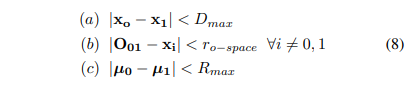
그후 수식 (8) 기반으로 사회적 상호작용 및 거리를 판단합니다.
(a)를 통해 두 참석자의 일정 거리에 있는지 판단을 하고 (b)를 통해 o-space가 비어있는지를 판단합니다. 이 두 수식을 통해 all-vs-all로 구성된 pair들이 대부분 선별됩니다.
마지막으로 (c)를 통해 각 참석자들이 o-space를 바라보고 있는지(F-formation을 형성하는지)를 판단하여, 실질적으로 사회적 상호작용 및 거리 두기 여부에 대해 예측합니다.
++ D_{max}, R_{max} 는 사전 정의된 파라미터 입니다. 저자의 주장으로는 방역 당국 혹은 어플리케이션에 따라 해당 파라미터를 통해 범용적으로 사용이 가능하다고 이야기합니다. 규칙 기반의 장점이자 단점으로 보입니다.
++각각의 loss는 MonStereo와 동일하기에 이전 리뷰를 참고해주시면 감사하겠습니다.
Experiment
실험에서는 이전과 동일하게 KITTI와 nuSecnes의 teaser를 사용합니다. 사회적 상호작용에는 비디오 팀에서 소개한 걸로 기억하는 Collective Activity Dataset을 이용했습니다. 사회적 거리두기에는 KITTI를 이용하여 평가를 하였습니다.
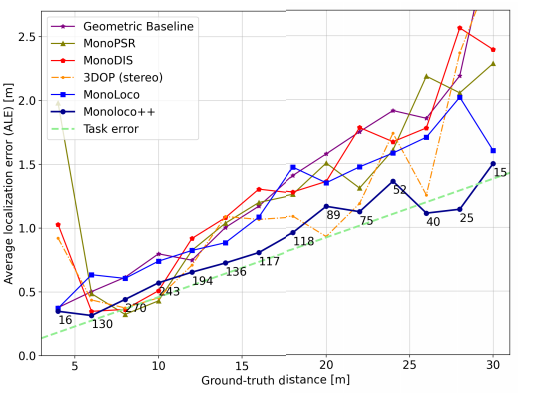
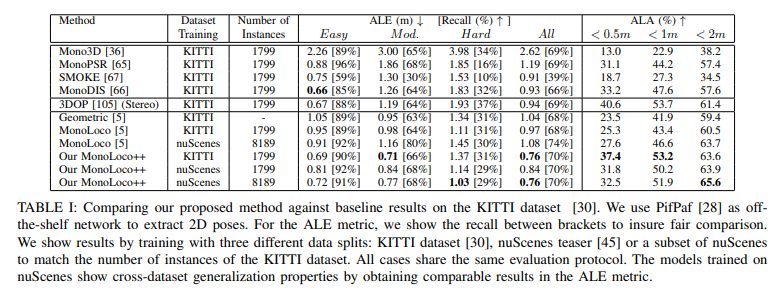
KITTI에서의 정량적인 결과입니다. 기존읜 방법론인 monoloco보다 높은 성능을 가져왔으며, 재밌는 부분은 stereo에 해당하는 3DOP보다 높은 성능을 가져옵니다. 또한 단안에서 발생하는 task error를 먼거리에서는 오히려 극복한 것을 통해, 위치 정보의 모호성을 구 좌표계로 변경하고, 방향 정보를 추가하는 것이 효과가 있다는 것을 증명합니다.
또 Table 1에서 dataset training에서 nuScenes이라고 적혀진 부분은 domain generalization(cross-dataset generalization)을 확인하기 위해 추가적인 kitti에서의 추가 학습이 없었다고 합니다. 여기서도 재밌는 부분이 Hard에서 오히려 kitti에서 학습한 결과보다 좋은 성능을 보이며, 최종적인 성능에서 kitti로 학습한 결과와 동일한 성능을 보입니다. 이는 해당 방법론이 데이터셋의 영상 정보에만 취중되는 것이 아닌, 보행자의 키 분포를 이용하는 간단한 방법이기에 영상이 아닌 보행자의 분포가 얼마나 잘담겨있냐가 더 중요한 요소로 작용된다는 것을 증명합니다.
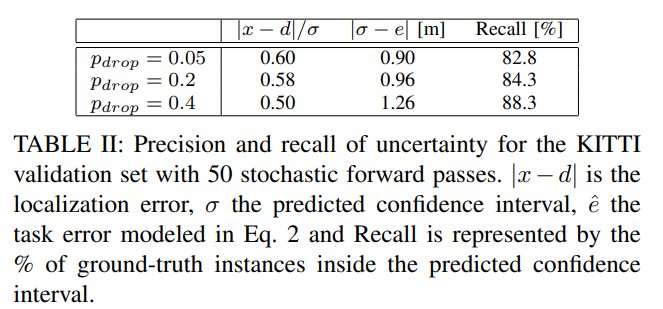
해당 실험에서는 drop out에 비율에 대한 ablation study에 해당합니다. 결과를 보면 drop out에 대한 비율은 불확실성과 에러에 대해 비례하고 Recall에 대해서는 반비례하는 trade-off 관계인 걸 확인 할 수 있습니다. drop out에 대한 비율이 커질 수록 불확실성이 커진 정보들만 가져가게 되고, 이는 먼거리에 위치한 보행자 혹은 가려진 보행자들도 후보에 추가한다는 이야기입니다. 이러한 케이스가 필요한 경우가 있습니다. 아래의 그림(fig 9) 같은 상황에 해당합니다.
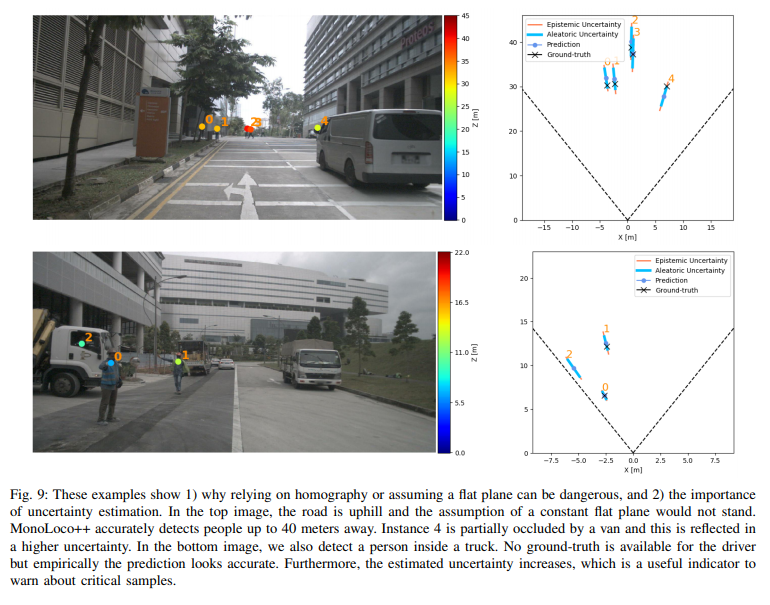
Fig 9의 상단의 4번 보행자와 같이 밴에 가려진 상황도 검출이 가능해집니다. 하지만 불확실성이 커진 것을 확인이 가능합니다. 추가로 하단 2번 보행자는 실제 GT에는 없는 상황에 해당합니다. 하지만 이런 비정상적인 상황에서도 예측함으로써 위험하거나 돌발상황에 대비할 수 있다고 이야기합니다.
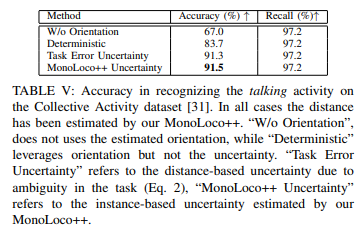

먼저 사회적 상호작용에 대한 평가 결과 입니다. 평가를 위해 D_{max}=2, r_1=0.3, r_2=0.5, r_3=1로 설정하였으며, R_{max} = r_{o−space} 를 기준으로 하였습니다. 사회적 상호작용 여부에 대한 binary classification으로 문제를 해석하여 talking 여부를 판가름하였습니다. 그 결과 Table 5와 같이 91.5%의 성능이 나옵니다.
(w/o orientation : 방향 정보 없이, Deterministic : 불확실성을 사용 x, Task Error Uncertainty : 사전 정의된 task error를 사용)
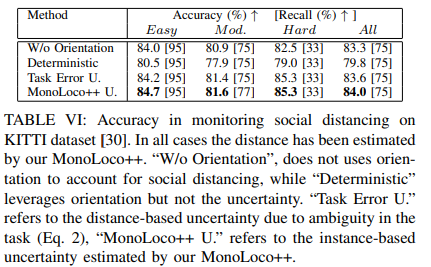
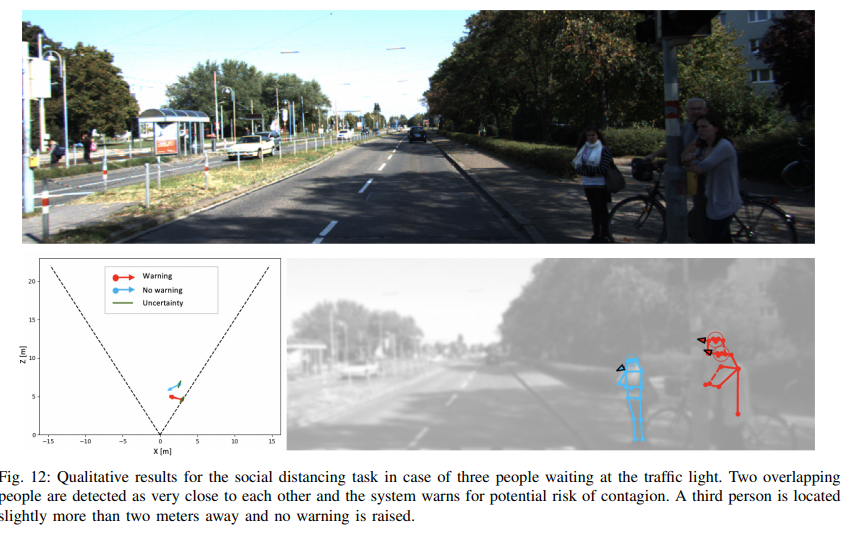
데이터 셋은 KITTI를 사용하였으며, 수식 (8)을 통해 warning/no warning 이진 클래스를 생성하여 GT로 사용하여 평가하였습니다. 상호작용이 우선이 아닌 거리두기를 평가를 하는 것이 목적이기에 f-formation이 보다 느슨한 규칙을 사용해야합니다. 그렇기에 저자는 바라보는 각도 차이를 R_{max} = 2*r_{o−space} 로 늘려 평가를 진행하였습니다. 결과는 Table 4와 같습니다.
Reference
[1] Marquardt, Nicolai, Ken Hinckley, and Saul Greenberg. “Cross-device interaction via micro-mobility and f-formations.” Proceedings of the 25th annual ACM symposium on User interface software and technology. 2012.
[2] P. Li, X. Chen, and S. Shen, “Stereo r-cnn based 3d object detection for autonomous driving,” in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 7644–7652.
결론
이번에 monoloco 시리즈를 읽으면서 저자가 정말 셀링은 기가막히게 한다는 생각이 들었습니다. 사실 이어져온 각각의 방법론은 딥러닝에 대한 테크니컬이 들어가지는 않았습니다. 하지만 어필하는 필요성과 실험 방법들을 보면 해당 방법이 필요하겠다는 생각이 듭니다. 제안한 방법의 필요성을 어필하는 것도 매우 중요한 능력이라는 걸 새삼스럽게 다시 깨닫게 해주는 논문입니다.
monoloco 시리즈를 마무리하면서 각각의 방법론을 정리하자면 다음과 같습니다.
Motive
– monoloco : 보행자의 키 정보와 거리 정보의 관계성에 대한 불확실성을 이용한 추론
– monoloco++ : 보행자의 방향 정보를 추가
– MonStereo : 단안과 양안에서 발생하는 long-tail 문제를 단안과 양안을 모두 사용.
Input
– monoloco/monoloco++ : keypoint
– monstereo : keypoint pair
output
– monoloco : 거리 정보 z, 불확실성 b ~ 거리 정보만 있으면 학습 가능
– monoloco : 구 좌표 상 3차원 위치 정보 (r, b, pi), 보행자 방향 ~ 3차원 위치 정보 + 보행자 방향 정보가 있어야 학습 가능
– MonStereo : 구 좌표 상 3차원 위치 정보 (r, b, pi), 보행자 방향, pair 여부 ~ 3차원 위치 정보 + 보행자 방향 + pair 정보가 있어야 학습 가능
Model
– monoloco : FC(1024~BN~ReLU~Dropout)
– monoloco++ : FC(1024~BN~ReLU~Dropout)~residual
– MonStereo : FC(1024~BN~ReLU~Dropout)~residual + auxiliary layer(Instance Stereo Matching loss)
Loss
– monoloco : Laplace loss + L1 loss(d)
– monoloco++ : Laplace loss + L1 loss(r, b, pi, theta)
– MonStereo : Laplace loss + L1 loss(r, b, pi, theta) + ISM(Instant Stereo Matching) Loss~Binary cross entropy loss
추가로 코드 레벨로 분석을 하였고 monloco인 경우, 현재 가지고 있는 정보를 기반으로 학습과 평가가 가능해보입니다. 이를 토대로 momoloco 기반으로 monstereo로 개선하여 평가를 진행.
필요시 보행자의 3차원 위치 정보와 orientation에 대한 정보를 annotation을 진행하여 monoloco++과 monstereo에 대한 학습과 평가를 진행 해볼 생각입니다.
좋은 논문 리뷰 감사합니다. 몇 가지 궁금한 것이 있습니다.
보행자의 orientation은 실제 이미지에서의 얼굴으 방향과는 상관 없이 pose keypoint로부터 추정된 전체적인 몸의 방향이라고 생각하면 되나요??
그리고 사회적 거리두기 평가에 KITTI를 이용하였다고 하셨는데 혹시 사회적 거리두기 평가가 어떤 평가인지 설명해주시면 감사하겠습니다!!
Q. 보행자의 orientation은 실제 이미지에서의 얼굴 방향과는 상관 없이 pose keypoint로부터 추정된 전체적인 몸의 방향이라고 생각하면 되나요??
– pose keypoint에서 추론된 방향이 아닙니다. KITTI 데이터셋에서 측정된 GT로부터 모델이 학습하여 추론하는 값입니다.
Q. 그리고 사회적 거리두기 평가에 KITTI를 이용하였다고 하셨는데 혹시 사회적 거리두기 평가가 어떤 평가인지 설명해주시면 감사하겠습니다!!
– 두 참석자간 거리를 측정하고 일정 임계값 이내에 있는지 확인하고, F-formation을 통해 소통 중인지 판단을 합니다. 두 조건이 맞다면 사회적 거리두기를 지키지 않는다고 분류합니다. 즉, 사회적 거리두기를 지키고 있는가를 classification하는 평가 입니다. 그래서 Accuracy와 Recall를 평가 메트릭으로 사용하여 평가를 합니다.