

Temporal Action Detection 분야에서는 Object Detection에서와 유사하게 Proposal을 생성하고 Classification을 진행합니다. 이러한 Temporal Proposal 생성이 어떤식으로 되는지 확인하기위해 SOTA 였던 Temporal Action Detection 방법론들의 코드를 서베이하던 중, 여러 방법론들이 BSN(Boundary Sensitive Network) 라는 논문의 Proposal 생성 방식을 따르고 있어 리뷰하게 되었습니다.
1. Method (BSN)
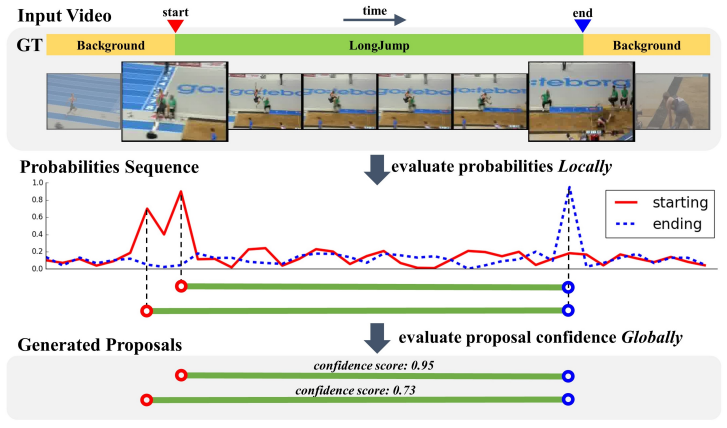
BSN은 Action일만한 영역을 예측하는 방법론 입니다. 어떤 Action인지는 판단하지 않으나 이 Proposal이 사전에 정해둔 Action인지 아닌지를 나타내는 Actionness를 판단하며, (1.1) Visual Encoding, (1.2) Boundary Sensitive Network, (1.3) Redundant Proposals Suppression과 같이 크게 세 가지 과정으로 나뉘어 framework가 구성됩니다.
1.1 Visual Encoding
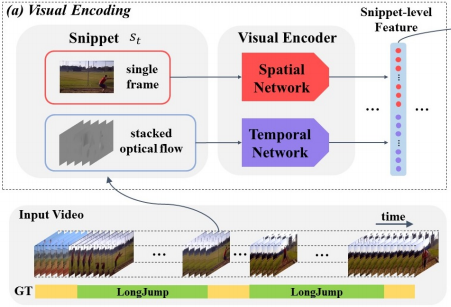
우선 Visual Encoding 과정을 거쳐 snippet-level의 feature를 생성하게 됩니다. 여기서 snippet이란 temporal segment 와도 같은 의미이며 연속된 프레임의 집합을 의미합니다. 한 비디오에서 일정한 길이 \rho 만큼씩 겹치지 않게 snippet을 생성하고, I3D로 추출된 RGB feauture와 해당 snippet의 optical flow를 concatenate하여 snippet-level feature를 생성하게 됩니다. 본 논문에서 실험한 데이터 셋 ActivityNet-v1.3에서는 \rho 를 16으로, THUMOS14 에서는 \rho 를 5로 두었다고 합니다.
1.2 Boundary Sensitive Network
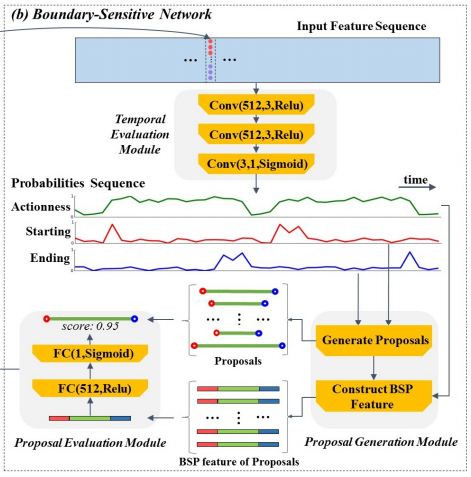
BSN 과정에서는 앞서 추출한 snippet-level feature를 활용해 bottom-up 방식으로 Proposal을 생성하고 Proposal-level feature도 추출하게 됩니다. Proposal-level feature 는 Actionness를 판단하는데 사용됩니다. 해당 과정에서도 TEM(Temporal Evaluation Module), PGM(Proposal Generation Module), PEM(Proposal Evaluation Module)과 같이 세 가지 모듈로 나뉘어 연산이 진행됩니다.
- TEM (Temporal Evaluation Module)
TEM에서는 먼저 한 비디오 내에서 추출된 모든 snippet-level feature 간의 temporal 정보를 얻기 위해 Conv Layer로 embedding 시킵니다. 마지막 Layer의 Activation Function을 Sigmoid로 두어 총 3 채널의 [0,1] 사이 값을 얻으며, 이는 각각 해당 시간 지점의 Actionness, Starting, Ending 확률이 됩니다.
- PGM (Proposal Generation Module)
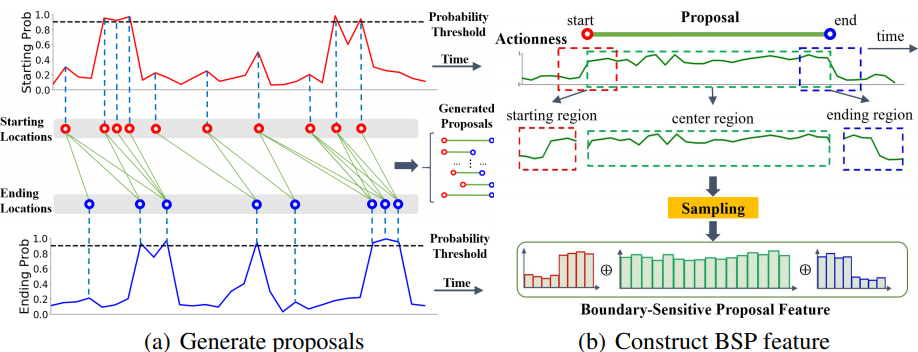
PGM에서는 앞서 TEM에서 얻은 각 시간 지점 별 세 종류의 확률로 Proposal 을 생성하게 됩니다. 우선 Starting 확률을 활용하여 각 시간 지점 중 Starting point가 선정됩니다. 선정되는 방식은 모든 시간 지점 중 i) 확률이 0.9를 넘는 지점 혹은 ii) peak 지점(이전 시간 지점보다 확률이 높은 지점) 두가지 조건 중 한 가지라도 만족할 경우가 사용되며, Ending point도 이와 같은 방식으로 선정됩니다. 이렇게 Starting point들과 Ending point들이 선정 완료 된 후, 각각 연결을 했을 때 minimum duration과 maximum duration 범위 사이에 들어온 길이를 가진 쌍만 Proposal로 선택을 하게 됩니다. 여기서 duration의 범위는 GT 기준으로 정해졌다고 합니다.
이렇게 얻은 Proposal에서 각각 Starting point부터 ending point 까지를 center region으로 나누고, Starting point를 중심으로 앞뒤 center region / 5 만큼의 영역을 starting region, Ending point를 중심으로 앞뒤 center region / 5 만큼의 영역을 ending region으로 나누게 됩니다. 그리고 center region에 해당하는 Actionness 확률을 16개의 값으로 interpolation, starting region과 ending region에 해당하는 Actionness 확률을 각각 8개의 값으로 interpolation 한뒤 이를 concatenate 하여 Proposal-level feature 인 BSP(Boundary-Sensitive Feature)를 추출합니다.
- PEM (Proposal Evaluation Module)
PEM 에서는 앞서 구한 BSP를 FC layer로 embedding 시켜 해당 Proposal 의 confidence를 계산하고 GT와의 IoU를 계산해 학습시키게 됩니다.
1.3 Redundant Proposals Suppression
BSN 과정 학습 후 평가 시, Proposal 별 score 로 sorting 하고 높은 score의 Proposal을 기준으로 나머지 Proposal과 IoU를 계산하여 많이 겹칠 시 제거하는 Soft-NMS 처리를 하여 최종 Proposal을 선정하였다고 합니다.
2. Experiments
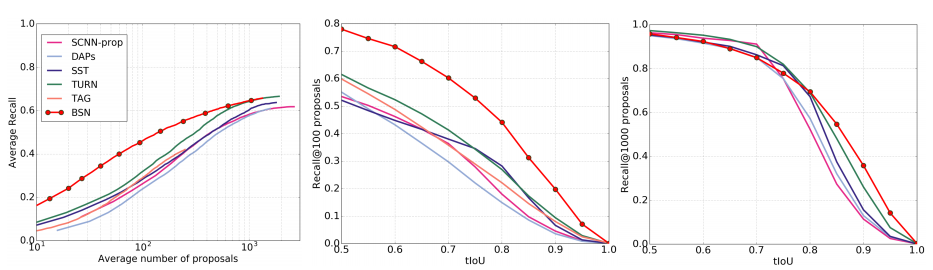
Fig 6는 해당 논문의 BSN의 Proposal 성능을 의미 합니다. 왼쪽 그래프로 BSN이 다른 SOTA 방법론에 비해 Proposal의 수가 적을 때 성능 차이가 더 크다는 것을 알 수 있으며, 각각 Proposal이 100개와 1000개일 때 tIoU 별 Recall 성능을 나타낸 가운데 그래프와 오른쪽 그래프를 보았을 때도 확실히 Proposal이 많을 경우 다른 SOTA 알고리즘과 비슷한 성능을 보이지만 적을 경우 다른 SOTA 알고리즘에 비해 좋은 성능을 보이는 것을 알 수 있습니다. Proposal의 수를 늘린다는 것은 결국 해당 알고리즘의 속도도 선형적으로 느려진다는 것을 의미하는 것을 고려할 때 이 그래프들을 통해 BSN은 다른 방법론들 대비 빠른 속도로 좋은 성능을 낼 수 있다는 것으로 분석됩니다.

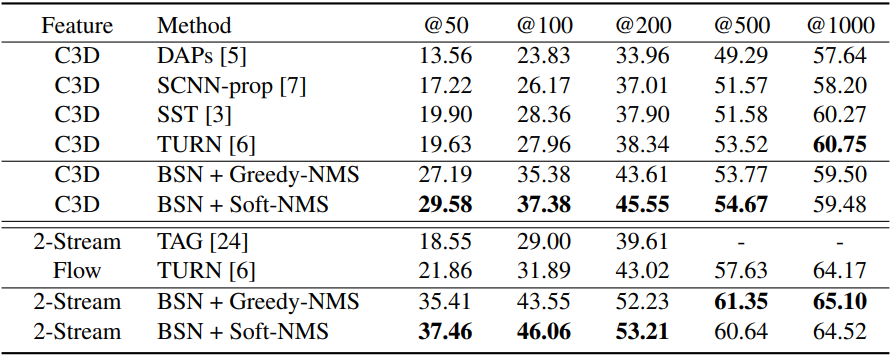
Table 1과 2는 각각 ActivityNet-v1.3과 THUMOS 14 데이터 셋에서의 Proposal 생성 성능을 나타내며, AR@AN 지표는 Proposal 수(AN) 별 Average Recall(AR)을 의미합니다. 두 데이터 셋에서 모두 당시 SOTA의 성능을 달성한 것을 알 수 있으며, 앞선 Fig 6에서 분석했던 바와 마찬가지로 Proposal의 수가 적을 수록 다른 알고리즘과 성능차이가 많이 나는 것을 확인할 수 있습니다.
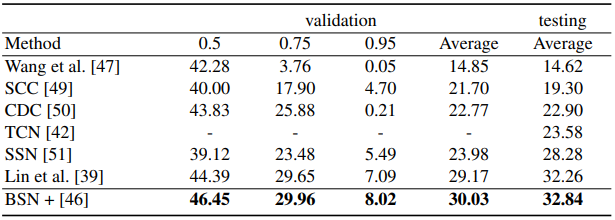
terms of mAP@tIoU and average mAP, where our proposals are combined with video-level classification results generated by [46]
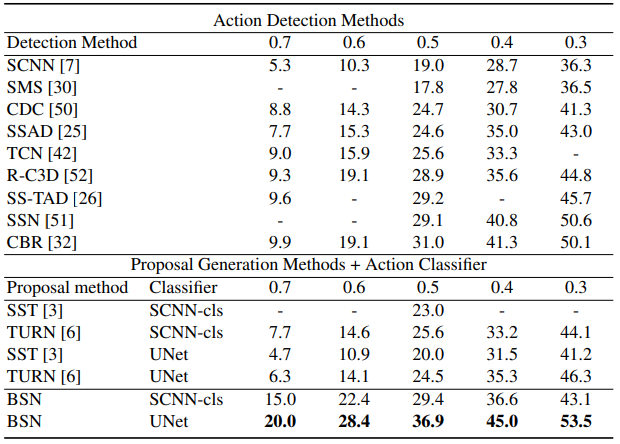
where classification results generated by UntrimmedNet [48] and SCNN-classifier [7]
are combined with proposals generated by BSN and other methods
Table 3에서 [46]은 “CUHK & ETHZ & SIAT Submission to ActivityNet Challenge 2016” 라는 논문을 의미하며 Table 3과 4는 각각 다른 방법론의 Classifier를 BSN에 붙였을 때의 Action Detection 성능으로 다른 Proposal 방법론 대비 높은 성능 향상을 보이며 SOTA를 달성한 것을 확인할 수 있습니다.
3. Reference
[1] https://arxiv.org/pdf/1806.02964.pdf
제가 읽다가 이해가 안되는 부분이 있어 질문드립니다. proposal을 만들고, 이때 Object detection 에서 objectness처럼 Actionness를 판단하는것 같습니다. 근데 TEM(Temporal Evaluation Module), PGM(Proposal Generation Module), PEM(Proposal Evaluation Module) 3가지 모듈을 각각 학습시키는게 아니라 세개를 모두 진행하는 하나의 프레임워크를 통해서 마지막에 각각 레이어 학습을 위한 Loss를 backward하는건가요? 글에서는 PEM에서 IOU를 계산해 학습한다고 하였는데 해당 부분에서 backward를 할때 뒤에 TEM 과 같은 부분도 학습이 될 수 있는건가요..?
세가지 모듈을 각각 순차적으로 학습시키는 방식으로,
우선 TEM 따로 학습 시키고 TEM에서 Snippet-level의 세가지 확률을 예측하고, 예측한 확률로 PGM에서 Proposal을 생성한 뒤, 생성된 Proposal로 PEM을 학습 시키고 평가하는 방식으로 진행됩니다.
사실상 3-stage를 거치는 방법론으로 이와 같이 여러번의 과정으로 나눈이유로는 중간 PGM에서 Proposal을 생성하는 과정이 미분 불가능이라 이렇게 나눈 것으로 추측 됩니다.
음.. snippet level feature 가 temporal한 영역에 따라서 나뉘는 feature라는건 이해하였는데. proposal-level feature는 snippet level feature와 무슨차이를 가지나요? snippet level feature가 모여서 proposal-level feature가 되는건가요? 피규어4번의 맨위에보면 그림이 의미하는바가 snippet level feature들이 모여 있는 건가요?
넵 맞습니다. Snippet level feature는 일정한 길이인 프레임 셋에서 나온 feature이고, 이 Snippet level feature 에서 나온 세가지 확률을 활용해 aggregation 하여 얻은 것이 Proposal level feature라고 보시면 됩니다.
FIg 4의 맨위 그림은 한 비디오에서 생성된 Snippet level feature가 모여있는 것이 맞습니다.
제가 이해한 바로는 비디오를 optical flow로 예측 후, TEM을 통해 시각-{Actionness, Starting, Ending } probability를 예측하고 PGM을 통해 start, end를 예측하여 proposal을 구분한 뒤, 각 proposal에 대한 BSP feature(1/5(bins=8), 3/5(bins=16), 1/5(bins=8)를 변환하고 PEM이라는 tiny fc를 통해 예측 score를 구하고, 해당 propsal과 GT의 iou를 계산하여 예측하는 방식으로 학습하는 걸로 이해했습니다.
그럼 TEM을 통해 시각-{Actionness, Starting, Ending } probability를 예측하는 것이 핵심 부분이라고 생각하며. 시작과 끝 부분에 대한 확률 분포가 정확해야지만 해당 방법론이 의미가 있어보입니다. 학습에 대한 설명도 추가 가능할까요?
넵 맞게 이해하셨습니다.
학습 방식으로는 TEM 모듈만 먼저 학습을 시켜 output인 세가지 probability를 예측하게 되며 각 probability는 binary logistic regression Loss로 학습됩니다.
TEM 학습 -> TEM 예측, PGM 예측, PEM 학습 -> TEM 예측, PGM 예측, PEM 예측 이라고 보시면 됩니다.