RCV연구실 image translation 전문가 신정민 연구원으로부터 추천받아 리뷰하게된 논문입니다.
우선 시작하기에 앞서 제가 이 논문을 읽게된 이유에 대해서 설명드리겠습니다. 지난 MLPD를 작성하면서 Multispectral pedestrian detection을 진행하는데 있어서 결정적으로 아직 완벽히 해결되지 못한 문제를 알게됩니다. 이 문제는 바로 ‘Misalignment’ 문제 입니다. 이 문제는 다양한 원인으로 발생할 수 있으며, 센서 퓨전을 다루는 연구에서는 항상 고려되어야할 문제입니다. 좀 더 잘 설명하기위해 시각적인 그림을 가지고 왔습니다.

위에는 우리가 잘 알고있는 카이스트 벤치마크 데이터셋 입니다. 그리고 아래는 FLIR에서 제공하는 교육용 데이터셋입니다. FLIR셋의 경우 카이스트에 비해서 실제 misalignment를 보이고 있으며, 이러한 문제는 좀 더 실용적이고 실질적인 문제가 됩니다. 그래서 저는 이러한 이슈를 해결하기 위해 생각했던 것이 바로 ‘Image transfer’ 입니다.
![논문 정리] AdaIN을 제대로 이해해보자 :: Lifeignite](https://blog.kakaocdn.net/dn/Zeoll/btq0nNzxzze/P61hc74xMxoystafi6yx80/img.png)
위의 그림은 ‘Image transfer’에서 가장 기본이되는 AdaIN 논문의 아키텍처 입니다. 간단히 설명하면 이미지는 content와 style로 나눌 수 있으며, 소스 이미지의 content와 타켓 이미지의 style을 통해서 새로운 이미지를 만드는 것이 ‘Image transfer’라고 할 수 있습니다. 그럼 저는 이러한 컨셉을 어떻게 적용하려고 하는 것일까요?

위의 그림과 같이 ‘RGB 또는 Thermal의 컨텐츠를 살리고 다른 모달리티 이미지의 스타일만 가져오는 새로운 이미지를 만들어 alignm이 맞는 두 이미지의 fusion을 통한 detection을 수행하면 어떨까’ 라는 생각을 하게 됐습니다. 그래서 이를 간단히 적용해보기 위해서 가장 대표적인 AdaIN과 CycleGAN에 AdaIN로스를 추가하여 결과를 확인해봤습니다.

확실히 멀티스펙트럴 인풋으로 들어가기 때문에 Fake ‘RGB’를 잘 만들고 있다고 생각이 들었지만… 결국 카이스트셋의 입력은 얼라인이 맞기 때문에 FLIR로 다시 실험을 하면 다음과 같은 결과가 나타났습니다.

어느정도 잘만드는것 같았으나.. 실제 몇몇 케이스를 더 살펴보면

Detection을 수행하기에 사람을 그냥 빛으로 만들거나,

버스의 형태가 사라지는등 Content의 정보가 잘 살아있지 못함을 확인할 수 있었습니다.
그래서 Image Transfer를 수행할때 Content의 정보가 많이 손실되는 문제를 해결해야 처음 생각한 아이디어를 고려해볼 수 있겠다는 생각을 하던중 RCV연구실 Image transfer 전문가 신정민 연구원님이 2021년 CVPR에서 발표한 논문을 소개시켜주셔서 해당 논문을 읽게됐습니다.

해당 논문에서는 위의 티저 그림과 같이 기존 Image transfer 논문들이 content를 손실하는 Content leak 문제가 발생한다고 처음으로 이야기합니다. 그리고 이러한 content leak 문제가 발생하는 원인에 대해서 다음과 같이 분석하고 있습니다.
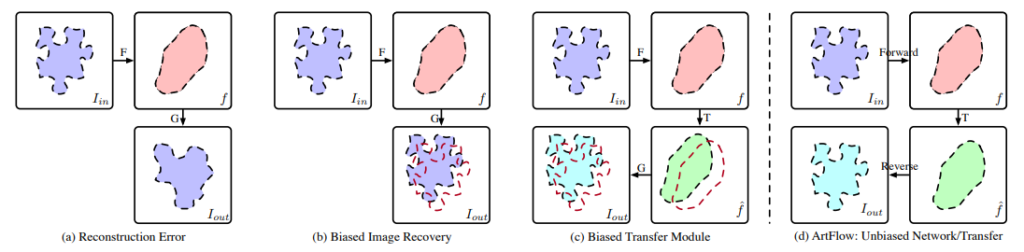
Reconstruction Error
먼저 기존의 Encoder-Decoder 방식의 Image transfer 논문의 경우 Encoder에서 pooling을 사용하기 때문에 loss of spatial information이 발생하고 이를 디코더에서 완벽히 재현해낼 수 없습니다. 따라서 Content Leak문제가 발생한다고 저자는 이야기 합니다.
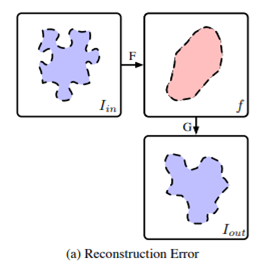
Biased Image Recovery
다음으로는 ‘Biased Image Recovery’ 입니다. 앞서 언급한 ‘Reconstruction Error’도 Content Leak를 발생시키는 요인이였다면 더불어 Decoder에 bias된 학습또한 Content leak을 발생시킨다고 합니다. 예를들어 AdaIN의 경우 Loss 설계를 다음과 같이 진행합니다.
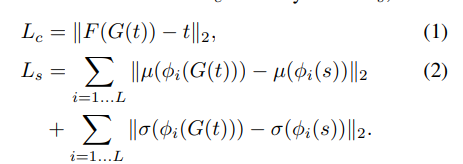
Content loss의 경우 adaptive instance normalization의 output인 t와 encoder(F), decoder(G)를 통해 나온 영상간의 mse loss를 통해 계산하며, style Loss의 두 평균과 분산을 이용하여 계산합니다. 따라서 이러한 학습 방식은 content와 style 각각에게 영향을 미치게되며, 이는 아래 loss 그래프에서도 확인할 수 있습니다.
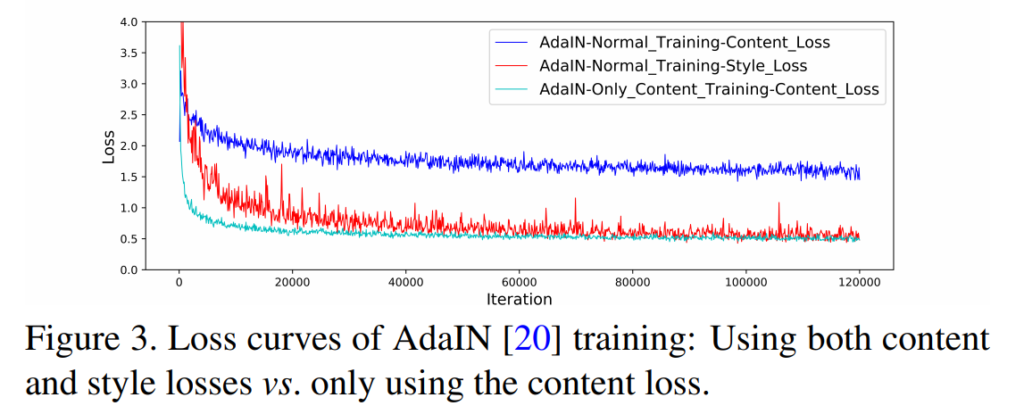
위에 그림과 같이 오직 content loss만 적용할때(초록색) 보다 style과 content를 모두 학습할때의 경향성을 보시면 모델은 style loss(빨간색)에 더 치중하며 content loss(파란색)은 content loss만 적용할때보다 loss가 커지는 것을 확인할 수 있으며 결과적으로 확인해도 아래 그림과 같이 학습이 거듭될 수록 content는 사라지는 것을 볼 수 있습니다.

Biased style transfer modules
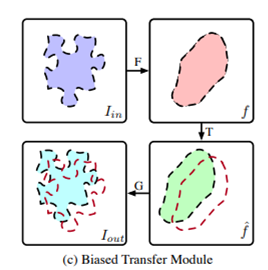
또 다른 종류의 Content Leak 발생 요인으로 Avatar-Net에서 사용하는 Style Decorator(style transfer module)에 대해서 이야기합니다. 해당 방법론은 content feature(f_c)와 style feature(f_s)를 normalize하는데, 방법은 먼저 f_s에서 f_c에 알맞는 corresponding patch를 찾아서 Style Decorator라는 모듈을 통해 만든 f_cs로 대체한다는데, 문제는 f_cs를 이용해서 f_c를 온전히 만들수는 없다고 합니다. 그리고 이러한 문제가 Content Leak을 발생시킨다고 합니다. (이 부분은 Avatar-Net에 대해서 좀 더 알아봐야할 것 같습니다.)
이러한 문제들로 인해서 Content Leak은 발생하며 저자는 이러한 문제를 해결하기 위한 reversible neural flow model인 Projection Flow Network(FPN)을 포함하는 ArtFlow라는 방법을 제안합니다.
해당 방법론은 Glow model를 따른다고 저자는 논문에서 설명하고 있는데요, 그리면 이러한 flow based 방법은 어떤 방법을 의미하는 것일까요? 설명을 이어가기에 앞서 잠시 추가적인 설명을 진행하겠습니다. 제가 리뷰했던 Anomaly detection을 수행한 Safe Robot Navigation via Multi-Modal Anomaly Detection 논문에서도 잠시 다룬적이 있었는데요.. 해당 방법을 간단히 다시 설명하자면 다음과 같습니다.
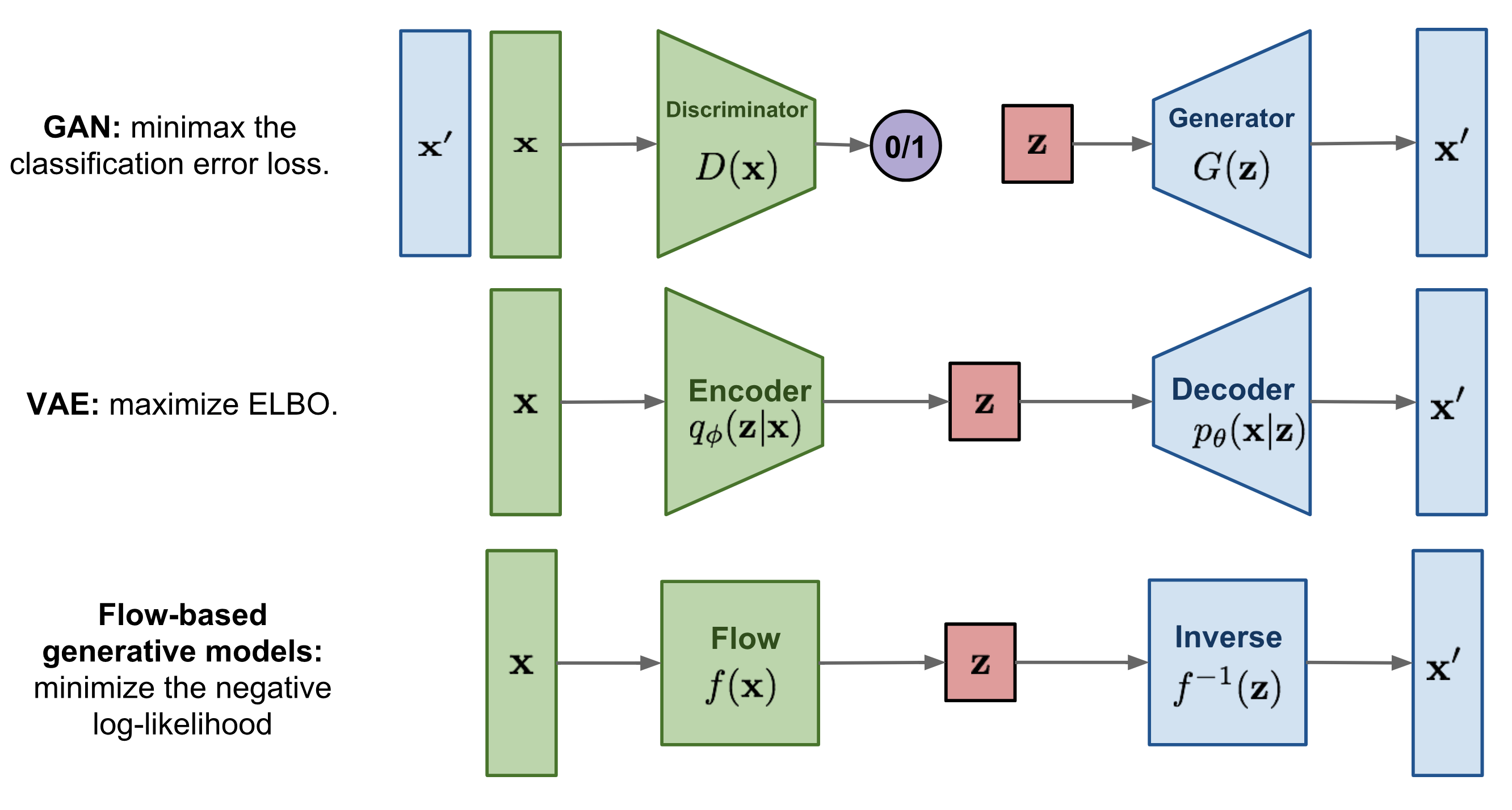
먼저 GAN 방식은 Discriminator를 이용해 참/거짓을 판별하고 이를 속이는 Generator를 통해서 진짜 같은 이미지를 만드는 방식입니다. 그리고 VAE 방식은 Encoder와 Decoder 구조를 통해서 새로운 이미지를 만드는 방식입니다. 그리고 Flow based generative models 방식은 Encoder-Decoder 구조와 다르게 어떠한 latent space vector로 만드는 함수 F를 구하고 이 함수 F의 역함수를 통해서 새로운 이미지를 만드는 과정으로 역함수가 존재하기 때문에 데이터의 손실이 적은 특징을 가지고 있습니다. 특히 해당 논문에서 따르고 있는 Glow에 대한 설명은 아래 PR 리뷰에서 자세히 다루고 있으므로 함께 첨부하겠습니다.
자 그럼 다시 본론으로 돌아와서 해당 논문도 이러한 flow based 방식을 통해서 content의 정보 손실을 최소화하여 Content Leak 문제를 해결하는 PFN을 제안하고 있습니다.
Projection Flow Network
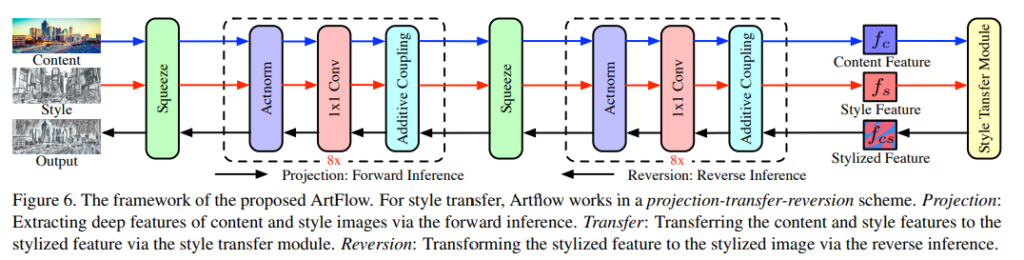
위의 그림은 전체 아키텍처입니다. 그리고 해당 논문은 flow 방식이기 때문에 가역적(reversible)이여야 합니다. 따라서 논문의 저자는 이전에 제안된 reversible transformation인 affine coupling layer의 special case인 additive coupling을 foward에 적용했다고 합니다. 이러한 근거로는 additive coupling layer가 style transfer task를 다루기에 실험적으로 충분했다고 합니다. 또한 채널의 감소도 필요한데, 이를 위해서는 Invertible 1×1 convolution을 적용했다고 합니다. 이는 feature의 채널을 바꾸기 위해 사용됐는데, 방법에 나타난 ‘Invertible’에서 알 수 있듯 비가역적인 covolution 이며, 이는 Glow에서 착안했으므로 위에 첨부한 PR 리뷰를 보시면 도움이 됩니다. 마지막으로 activation normalization layer도 마찬가지로 Glow에서 제안된 Actnorm을 사용하여 batchnormalization을 대체했다고 합니다.
Unbiased Content-Style Separation
또한 Content Leak 문제를 해결하기 위해서 Content Leak의 발생요인으로 Style과 Content를 동시에 학습하면서 biased 되는 문제를 앞서 설명했는데요. 저자는 lossless feature projector/inverter로 FPN을 사용하면 해결될 수 있다고 합니다. (이에 대해서 몇가지 가정과 증명을 다루고 있는데 이는 생략하겠습니다.) 그리고 FPN을 projector/inverter로 기존에 제안된 AdaIN, WCT에 적용하면 다음과 같은 error 그래프를 볼 수 있다고 합니다.
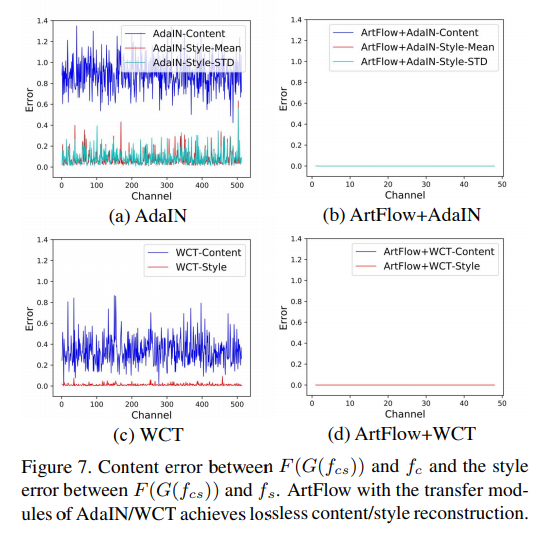
확실히 위의 그림에서 (a) vs (b) , (c) vs (d) 를 확인해보면 unbaised 됨을 확인할 수 있습니다.
Experiments
Style transfer 논문답게 먼저 visualization 결과를 보여주고 있습니다.


그리고 아래 그림은 실제 round(학습 정도라고 생각하면 될 것 같습니다.) 가 많아져도 content가 보존되는 것을 비교해서 보여주고 있습니다.

앞서 평가는 정성적이였다면 정량적인 평가도 수행하고 있습니다.

SSIM, Content Loss, Gram Loss 등을 통해서 정량적으로 비교하였는데, SSIM을 통해서 자신의 방법론이 가장 높은 스코어를 나타냈다고 합니다. 속도적인 측면도 설명하고 있는데 자신들의 방법은 pooling이 없어 큰 이미지를 다루고 있기 때문에 다소 느린 속도가 나타남을 언급하고 있습니다. 또한 gram loss 같은게 가장 낮지 않았는데, 이는 해당 gram loss를 타겟으로 학습하지 않았기 때문에 reasonable 하다고 합니다. (아마 다른 논문에서는 Gram loss를 타겟으로 했다봅니다.)

그리고 User 평가도 진행하였는데 ArtFlow가 가장 많은 표를 받았다고 합니다. 다만 이는 주관적이라 애매한것 같습니다.
결론
본 논문에서는 content leak 문제를 정의하고 이를 해결하기 위해 flow based 방법론을 style transfer에 적용하여 결과를 나타내고 있습니다. 현재 코드를 돌리고 있는데, 몇가지 data agumnetation에 의해서 성능이 잘 나타나지 않는 것 같습니다. 다음주에는 이러한 부분을 잘 수정하여서 앞서 언급한 아이디어에 적용이 가능하도록 코드를 수정할 계획입니다.
끝
좋은 리뷰 감사합니다.
Glow 방법론에 대해서 잘 알지 못한터라 해당 논문을 읽는데 있어 다소 어려움이 있었는데 필수적인 부분을 잘 작성해주셨네요.
질문이 두가지 있는데, 하나는 본문 내용 중 “lossless feature projector/inverter로 FPN을 사용하면 (Style과 Content loss가 편향되는 문제를) 해결될 수 있다고 합니다.(가정과 증명은 생략)” 이라는 내용이 있는데, 혹시 lossless feature projector/inverter의 동작 과정에 대해서라도 간략하게 설명해주실 수 있나요?
두번째 질문으로는 지금 코드를 돌려보신 것 같은데, 이러한 Flow based generative model은 입력 사이즈에서 어떠한 pooling과정 없이 동일한 사이즈의 feature로 학습이 되나요? 그렇다면 학습 시간은 일반적인 Auto Encoder와 비교하였을 때 큰 차이가 있는지 궁금합니다.
1. 내일 세미나에서 설명드리겠습니다.
2. 지금 돌리는 중인데 좀 많이 느리네요.. 체감부터 많이 차이나고 있습니다.
1. https://www.youtube.com/watch?v=TywKpiZJ7P4 에서 확인하시면 됩니다.