이번에 리뷰할 논문은 Self-supervised monocular depth estimation에 self-attention과 Discrete Disparity Volume이라는 방식을 제안한 논문을 가져와 봤습니다. 이 논문은 현재 Depth estimation model을 제안한 방법론들 중에서 가장 좋은 성능을 보이고 있어서 주의깊게 보고 있습니다. 또한 Self-Attention을 적용하는 것과 Depth를 정의하는 방식이 Self-supervised 에서 매우 새롭게 다가와서 저희 또한 적용을 검토하고 있습니다.
1, Contribution
이 논문에서 제안하는 방법은 총 세가지입니다.
- Backbone 모델에서 나온 feature를 self-attention을 활용해 global 한 영역을 볼 수 있도록 만듦
- Discrete Disaparity Volume(DDV): 기존 Supervised 기반의 Depth estimation에서 사용되던 방식으로, 기존 Sigmoid나 Relu와 같은 Activation function으로 linear하게 정의 되었던 inverse_depth를 이산화된 방식으로 정의하여 보다 Sharp하고 robust한 Depth 를 예측함
- ResNet50 backbone에서 ResNet101 로 distilation하는 방식에 대해서 소개.
2.Method
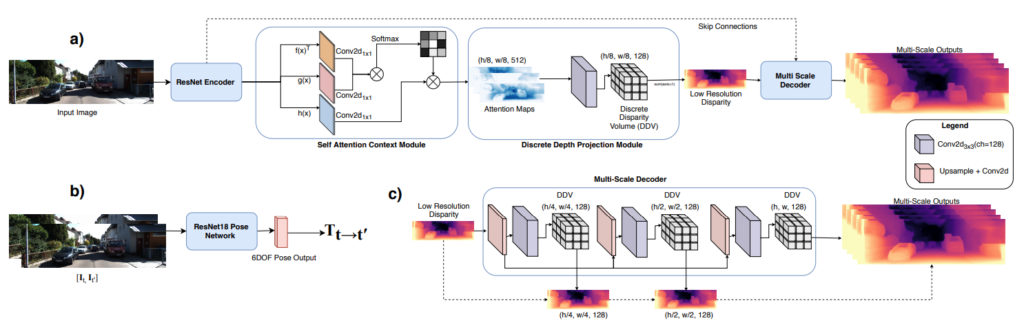
위 그림은 이 논문에서 제안하는 모델의 아키텍쳐입니다. 기존 self-supervised depth estimation의 방법과 동일한 프로세스로 진행되며 모델의 세부내용이 다르게됩니다. 이중에서 (a)의 Self-attention과 (c)의 DDV가 제안된 모듈입니다.
(1) Self-attention
Self-attention은 NLP에서 Transformer에서 많이 사용되고 있으며 최근들어 ViT와 같은 방식으로 Vision 분야에도 많이 도입되고 있으며 Classification이나 Object detection 같은 곳에도 좋은 성능을 보여주고 있습니다. 또한 Semantic segmentation과 같은 pixel level detection 과 같은 분야에서 또한 좋은 성능을 보여주고 있습니다. 이에 논문의 저자는 영감을 받아서 Depth estimation에도 Self-attention이 적용된다면 좋은 성능을 보여줄 것이라 생각하여 적용하였다고 합니다. 적용방식은 다음과 같습니다 .
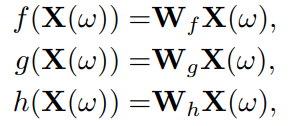
Resnet에서 나온 feature W를 key,query,value로 나눈후 1×1 convolution에 태웁니다. 그후 key feature와 query feature를 matmul 한 후 softmax로 채널별 attention을 구한후 value feature와 곱하여 attention을 진행하면 feature의 attention이 완료됩니다. self-attention 방식의 경우 기존에 다른 방법론에서 사용되는 것과 동일하며 매우 간단합니다.
(2) Discrete Disparity Volume
기존 Self-supervised depth estimation에서 Disparity를 예측할때 마지막 activation fuction으로 보통 Sigmoid를 사용해 0~1 사이에 linear한 disparity를 예측했습니다. 하지만 요즘 Supervised depth estimation에서는 아래 그림과 같이 disparity 값을 정해두고 각 값을 softmax를 이용해 있을 양을 정하여 disparity를 정하는 방식으로 disparity를 정의한다고 합니다.

이렇게 할 경우 disparity가 보다 sharp 해지도록 에측한다고 합니다. object에 대해 sharp 하게 예측하면 보다 error에 대해 강인해지므로 좋은 성능을 이끌어냅니다.
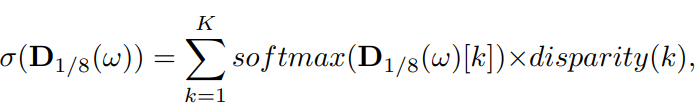
DDV의 식입니다. feature를 softmax하여 미리 정의해둔 위 그림과 같은 diparity map과 곱하고 더하여 최종적인 disparity를 예측합니다.
위 두개 외에 Loss나 pose CNN과 같은 경우 Monodepth2와 동일하므로 생략하도록 하겠습니다.
3.Results
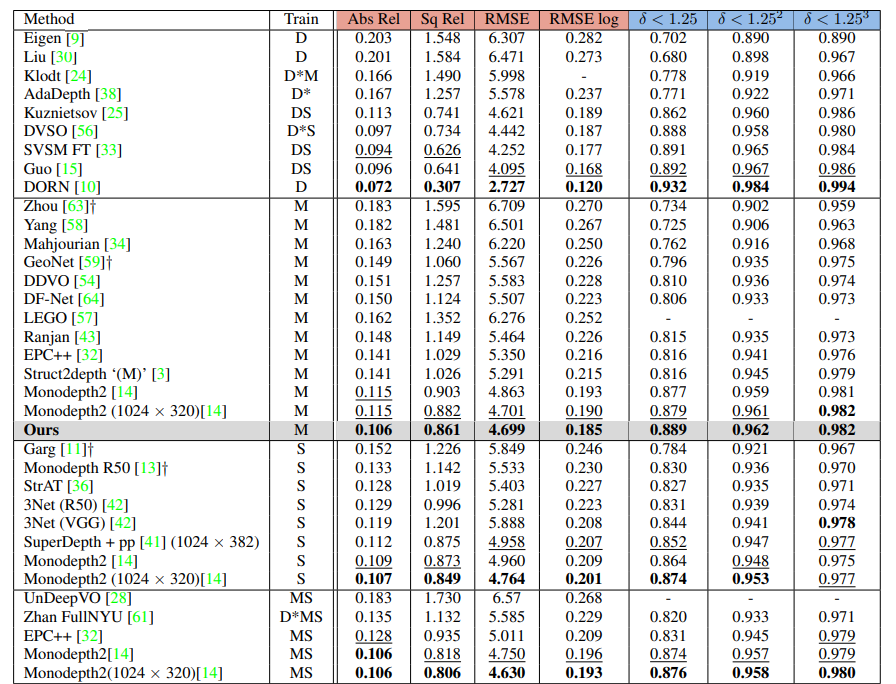
KITTI에서 의 성능입니다. 2020 당시에는 monodepth2가 SOTA였던 시절이니 그에 비해서 굉장히 좋은 성능을 보인 것을 알 수 있습니다. 또한 Abs_rel 0.106과 a<1.25 는 정말 뛰어난 수치 인 것 같습니다. 아무리해도 저 성능을 넘기가 힘든데 말이죠…

Ablation study 결과 입니다. Resnet 18을 backbone으로 썼을 때 Self-attn 과 DDV를 추가함으로써 성능향상을 볼 수 있으며 ResNet101로 변환 후 dilated 했을때 Sota성능을 볼 수 있습니다.
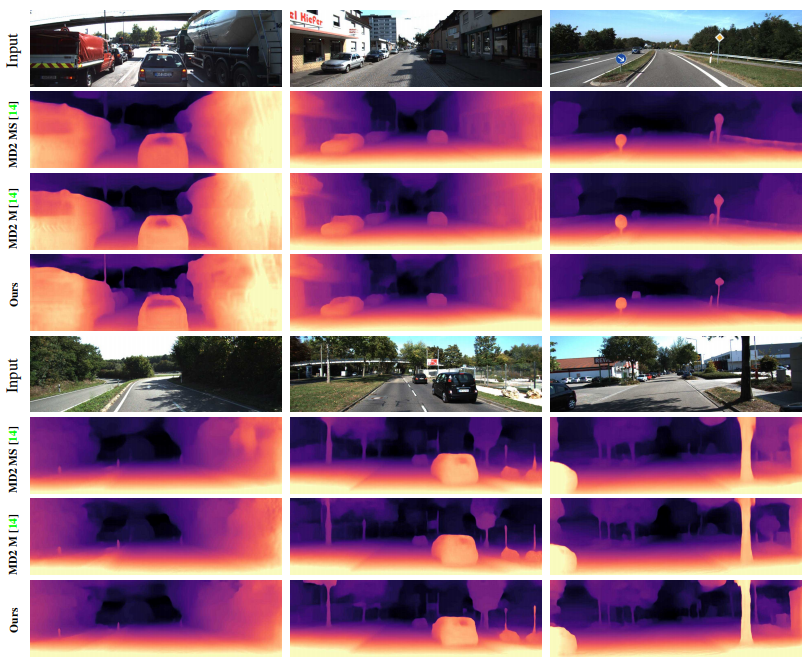
DDV를 적용했을 떄 Sharp 해진다는 것을 보인 정성적인 결과 입니다. 보면 표지판과 같은 것들이 보다 정확한 디테일이 산 것을 알 수 있습니다.
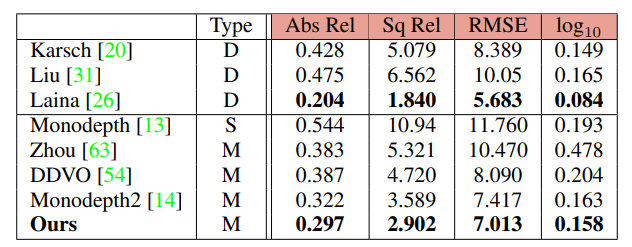
KITTI에서 뿐만이 아니라 Make3D 데이터 셋에서도 좋은 성능을 보인것을 알 수 있습니다.
좋은 논문 소개 감사합니다. DDV의 경우 Self-supervised depth estimation 학습시 기존에 0~1로 activation function을 적용하여 예측했던것을 더 많은 uniform 단계로 분류하여 결과값이 더욱 sharp 한 형태를 가졌다는 뜻 인가요?
넵