소개
해당 연구는 Probabilistic Abduction and Execution (PrAE) learner 를 제안한다. 이를 통해 기존의 후보군 중 카테고리를 선택하는 학습법이 아닌 확률적인 방법으로 답을 예측하며, visual attribute annotations없이 end-to-end 방식으로 학습한다.
해당 논문은 video와 관련된 키워드로 temporal, spatial 등이 포함되어 선정되었으나, 그보다는 Explainable Artificial Intelligence, 사람을 닮은 인공지능 연구 분야에 가까운 듯 하다. (spatial-temporal 정보를 갖을 수 있는 방법이 혹시 있을까 하여 읽게 되었다.) 해당 논문은 지능 검사 중 하나인 Raven’s Progressive Matrices(RPM) 를 주 과제로 삼았으며, 이는 관계 유추적 추론 능력 즉, 유동 지능(새로운 문제를 해결하는 능력)의 측정 지표로 평가되는 지표로, 사람에게는 비교적 쉬운 spatial-temporal reasoning(유동지능을 요구하는)이라는 테스크가 machine vision systems에서는 여전히 어려운 일이라는 것을 통해 해당 태스크를 해결하는것이 어려운 일 임을 알 수있다.
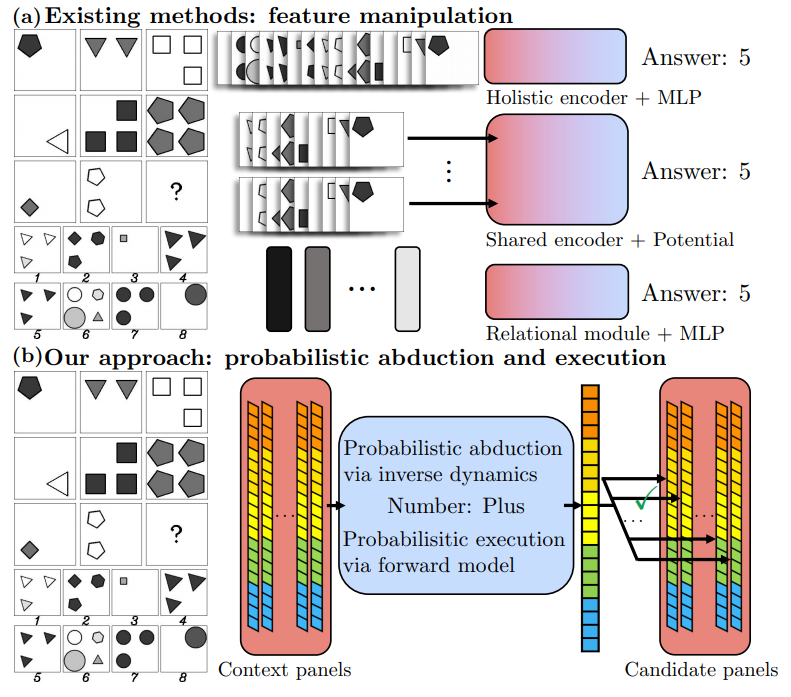
해당 논문에서 밝힌 기존 모델의 문제점은 다음과 같다.
- perception 과 reasoning 과정이 구별되지 않았다.
- deep model들은 대부분 train에 과적합 되었으며, 이는 고전 neural networks 구조의 한계이다.
- top-down, bottom-up reasoning의 부재 (양방향 추론의 부재)
The PrAE Learner
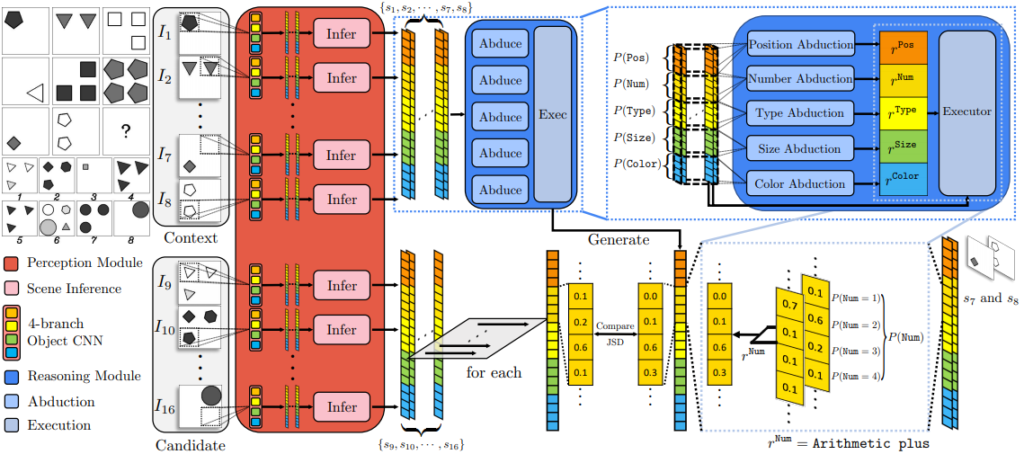
task는 그림2의 좌측 상단과 같다. 3×3 패널에서 빈칸 하나를 추론하는 것이다.
모델 설명
저자는 모델을 frontend operates와 backend operates로 나누었다.
- Neural Visual Perception 는 frontend 부분이며 object CNN과 scene inference engine으로 구성되어있다. 이는 input인 16개(정보8개 + 후보8개)의 pannel에 각각 작동한다.
– object CNN
4개의 CNN 브랜치로 이루어져 있으며 객체 속성(객관성, 유형, 크기 및 색상 등)의 확률 분포를 생성합니다.
– Scen Inference Engine
CNN output을 받아 panel 특성 분포를 생성합니다.
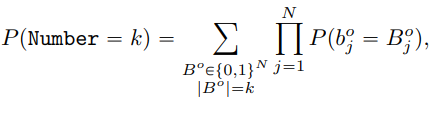
- Symbolic Logical Reasoning은 backend 부분이다. backend는 숨겨진 원리를 캡쳐하는 부분이다.
– Probabilistic Abduction
8개의 pannel이 주어졌을 때 probaailistic abduction engine은 rule의 확률을 다음과 같이 계산한다.
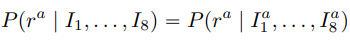
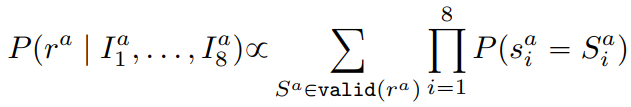
– Probabilistic Execution
Probabilistic Execution engine은 panel attribute a에 대한 적절한 rule을 선택한다.
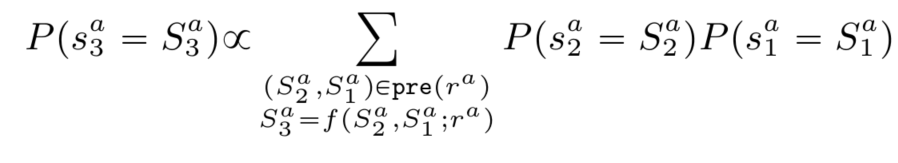
– Canidate Selection
최종적으로 예측된 panel과 정답을 비교하는 방법으로 Jensen-Shannon Divergence(JSD)를 이용한다.
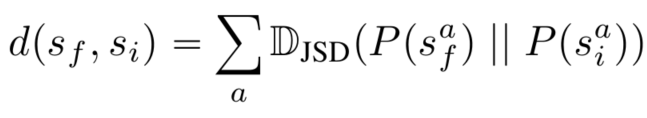
학습 방법
모델의 최종 목적함수는 다음과 같다, l은 cross-entropy loss를, y는 ground truth를 나타내며 auxiliary loss를 통해 초기에 학습이 어려웠던 문제를 해결했다고 한다. 또한 reasoning process에서 강화학습 기법으로 최적화 하였다고 한다.
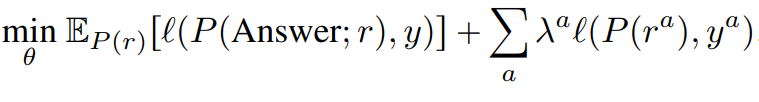
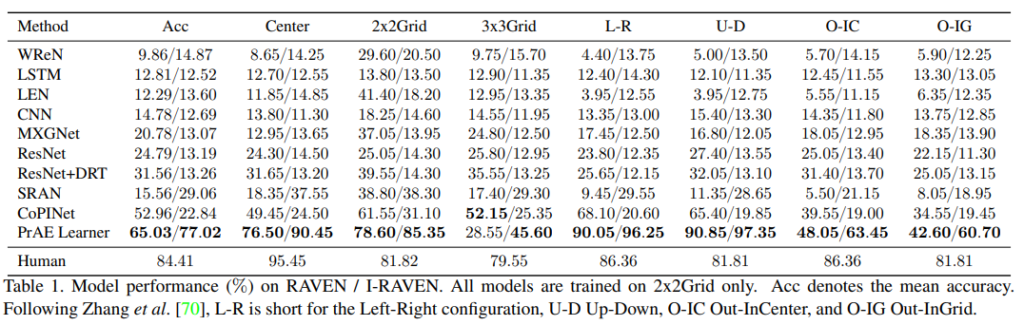
실험
실험 결과는 다음과 같다.
visual attribute annotations 이 없다는 것은 해당 방법론이 Unsupervised 방식으로 학습한다는 것을 의미하나요?
이 방법론이 만들어내는 output이 정확히 무엇인가요?
또 JSD를 통해서 정답분포와 모델이 학습한 분포간의 차이를 구해주는거 같은데 이게 학습이 끝나고 성능을 평가할때 사용이 되는 것인지 아니면 목적함수에 포함되어 올바른 분포를 학습할 수 있도록 사용되는 것인지 궁금합니다