Intro
이번 리뷰는 지난 리뷰에서 소개드린 monoloco [1]을 확장한 단안 카메라에서의 3차원 보행자 위치 인식 방법론에 해당합니다. 해당 논문에 대해 간략하게 소개하자면, monoloco로부터 획득한 coarse localization과 mono depth estimation을 이용한 BEV + 보행자의 Semantic Segmentation에서 얻은 보행자의 위치 정보를 refine하여, fine-grained localization을 예측하는 방법에 해당합니다. 추가적인 입력 정보 없이 monoloco보다 개선된 성능을 보여주었습니다.
저자가 주장하는 3가지 기여는 아래와 같습니다.
1. 단안 영상 기반의 3차원 보행자 위치 인식을 깊이 정보를 이용한 BEV, coarse 위치 정보를 융합하는 3단계 파이프라인을 제안합니다.
2. 보행자의 깊이 정보로부터 위치 인식 성능 향상을 위해, 보행자의 semantic segmantation 정보를 BEV에 투사하는 방법을 제안합니다.
3. BEV 정보를 직접적으로 이용하여 보행자 3차원 인식 정보들을 보정함으로써 세밀한 보행자 위치 인식 결과를 도출함으로써 SOTA에 달성합니다.
Method
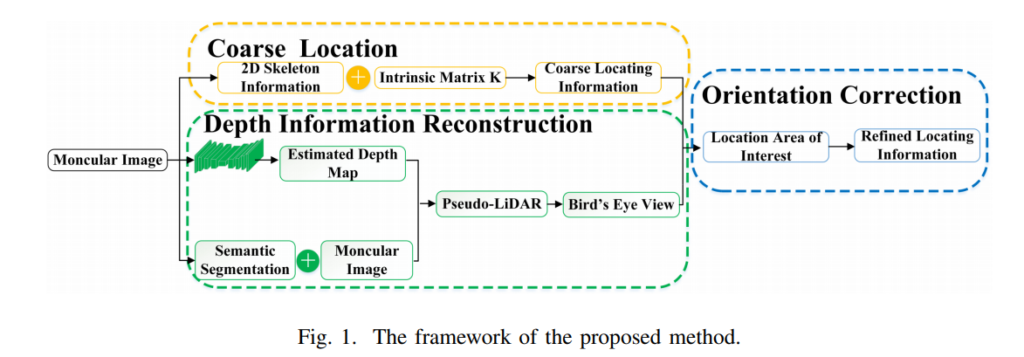
해당 방법론은 fig 1.과 같이 3가지 파트로 구성되어집니다. monoloco를 통한 coarse한 위치 정보를 예측하고, pseudo-lidar와 semnantic segmantation을 이용하여 dense한 정보를 추론합니다. 그후 coarse한 위치 정보와 dense한 위치 정보를 토대로 위치 정보를 보정하여 예측합니다.
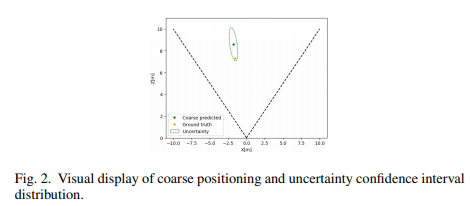
(1) Coares Location. PifPaf[2]를 통해 예측된 보행자의 포즈 정보를 입력값으로 사용하여 monoloco로부터 보행자의 coarse한 위치를 예측하고 또다른 예측값인 uncertainty bias를 Region of localization으로 사용합니다. Uncertainty bias를 Region of localization은 Fig 2의 초록색의 타원에 해당합니다.
(해당 부분은 monoloco와 동일하기 때문에 추가적인 설명없이 넘어가도록 하겠습니다. 궁긍하신 분들은 이전 리뷰를 참고하시기 바랍니다.)

(2) Depth Information Reconstruction. 단안 영상을 입력으로 사용하는 mono depth estimation 모델을 통해 depth를 예측하고 semantic segmentation 모델을 통해 보행자를 예측하여 해당 하는 컬러 정보를 depth에 추가한 후, pseudo-lidar로 변형 후, BEV로 사영시킵니다. 보행자의 semantic 정보가 컬러 정보로 pseudo-lidar에 적용된 모습은 fig 3.을 통해 확인 가능하며, BEV에 적용된 모습은 fig 4.를 통해 확인이 가능합니다. depth estimation과 semnatic segmentation은 각각 [3], [4]의 방법론을 적용하여 추론하였습니다.
++ [3], [4] 방법론을 사용한 이유에 적혀있지 않아 아쉬움이 컸습니다. [3]인 경우, depth 추정 시 실제와 유사한 표면을 생성하는 방법론에 해당함으로, 보행자의 표현력을 키우는 것이 목적으로 보입니다. [4]인 경우, RNN을 이용한 segmentation으로 연속적인 정보인 kitti에서 효과를 얻을려고 하는 것으로 보입니다…
(3) Orientation Correction. (1)에서 획득한 uncertainty bias를 Region of localization과 (3)의 정보를 토대로 위치 정보에 대해 refinement 합니다. 크게 두가지로 나눠집니다.
A. Refine the positioning position through image convolution:영상 convolution을 이용한 위치 보정을 합니다. (1)에서 획득한 Region of localization만큼의 크기의 정보를 절단하여 사용합니다. 그후 시맨틱 세그멘테이션 정보를 Gini index를 이용하여 적절한 kernel 사이즈인지 확인하여 적응적으로 변형하여 사용합니다. Gini index는 아래와 같습니다.
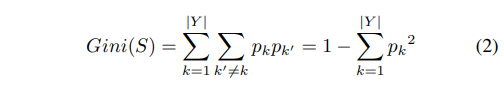
Y=255, p_k는 전체 픽셀과 k에 해당하는 픽셀의 갯수 입니다. 지니 계수가 클수록 불균형하며 작을수록 균형이 맞는 상황입니다.
++ 쉽게 말하자면, 딥러닝이 아닌 수작업으로 검출한다는 이야기입니다. monoloco로 관심 구역을 정하고 해당 구역안에 시맨틱 세그멘테이션 정보가 있다고 가정하고 gini index로 세그멘테이션 정보가 있는 혹은 가장 많이 담기는 커널 사이즈를 이용하겠다는 이야기입니다.
++ 여기서 컨볼루션은 deep learning의 컨볼루션이 아닙니다.
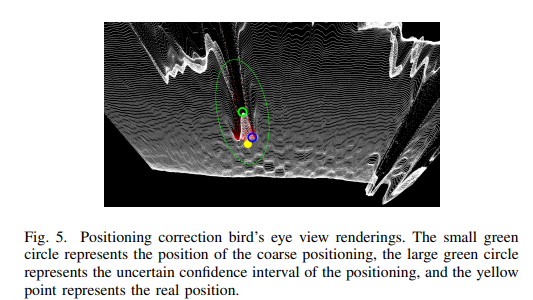
B. Mean-Shift clustering location Correction method: 컨볼루션 커널로부터 획득한 정보들로 보행자의 시맨틱 세그멘테이션에 해당하는 위치 정보들을 획득하게 됩니다. 이 정보들을 Mean-Shift clustering을 통해 보정된 위치 정보를 습득합니다. 그렇게 얻은 정보들은 Fig 5에서 확인할 수 있습니다. coarse한 위치 정보는 작은 초록색 원에 해당하며, 불확실성 bias는 초록색 큰 타원에 해당합니다. 보정을 통해 최종적으로 예측된 위치는 파란색에 해당하며, GT는 노란색 원에 해당합니다.
Experiment
실험에 사용된 데이터 셋은 monoloco와 동일한 KITTI를 이용하였으며, monoloco에서 제안한 메트릭을 그대로 사용하였습니다.
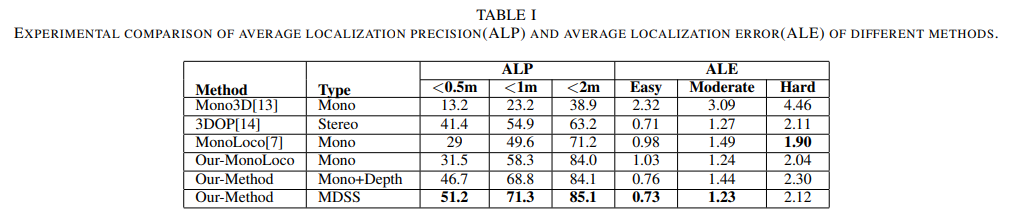
Table 1을 통해 기존의 방법론보다 성능이 개선된 모습을 볼 수 있습니다. 하지만 ALE-Hard에서 비교적 낮은 성능을 보이는데, 먼거리에 위치한 깊이 정보가 비정확하고, 2d bbox가 비정확함으로써 발생한 현상이라고 주장합니다. 또한 Type의 MDSS는 Mono+Depth+Semantic Segmentation의 약자에 해당합니다.
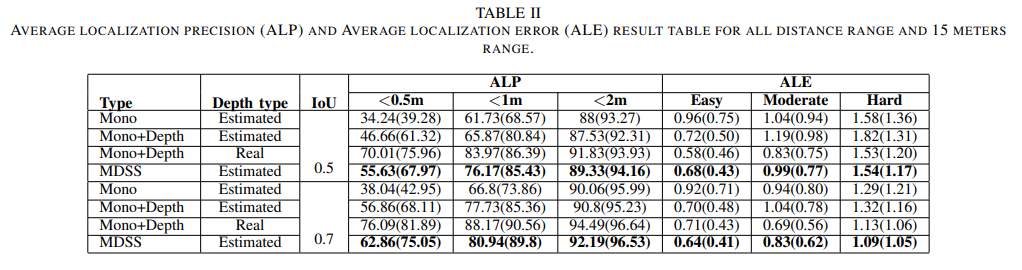
Table 2는 Ablation Study에 해당합니다. Deth type의 Real은 Kitti의 LiDAR에 해당합니다. 확실히 아직까지는 Real 데이터보다 낮은 성능을 보여줍니다만, 이는 depth estimation의 한계로 보입니다.
++ 다양한 depth 모델로 실험을 하였다면, 해당 방법론을 객곽적으로 볼 수 있었을텐데 조금 아쉽네요.
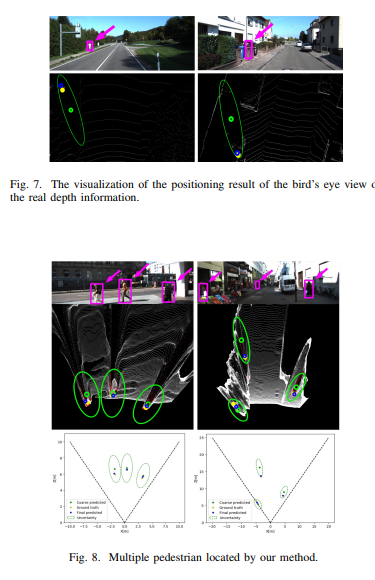
마지막으로 정성적인 평가 결과입니다. Fig 7, Fig 8은 각각 GT, Pseudo-Lidar의 BEV에서 보이는 결과 입니다. coarse 정보에 해당하는 monoloco보다 개선된 성능을 보여줍니다.
REFERENCES
[1] L. Bertoni, S. Kreiss, and A. Alahi, “Monoloco: Monocular 3d pedestrian localization and uncertainty estimation,” in Proceedings of the IEEE International Conference on Computer Vision, pp. 6861–6871, 2019.
[2] S. Kreiss, L. Bertoni, and A. Alahi, “Pifpaf: Composite fields for human pose estimation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 11977–11986, 2019.
[3] W. Yin, Y. Liu, C. Shen, and Y. Yan, “Enforcing geometric constraints of virtual normal for depth prediction,” in Proceedings of the IEEE International Conference on Computer Vision, pp. 5684–5693, 2019.
[4] S. Zheng, S. Jayasumana, B. Romera-Paredes, V. Vineet, Z. Su, D. Du, C. Huang, and P. H. Torr, “Conditional random fields as recurrent neural networks,” in Proceedings of the IEEE international conference on computer vision, pp. 1529–1537, 2015.
============================================================================
해당 방법론은 end-to-end 방법론이 아닌 hand-craft 방법론에 해당합니다. monoloco는 단순하게 관심영역을 결정해주는 역할만하고 실질적인 위치 추정은 depth estimation과 semantic segmentation만 영향을 미칩니다. 즉, 3차원 정보를 활용하여 새롭게 학습 및 추론하는 것이 아닌 2차원에서 추론된 정보들을 refine 함으로써 위치를 추정하는 방법에 해당합니다. 이럴 경우 얻을 수 있는 장점이 무엇인지 저자가 어필해줬으면 하는데 아쉬움이 큽니다… flop이 적거나, 추론 시간이 적거나… 이래저래 아쉬움이 큰 논문이였던 것 같습니다.
리뷰 잘 읽었습니다.
해당 논문에서 Depth를 BEV로 변환하여 사용한다고 하셨는데, 혹시 BEV로 변환하는 과정에 대해서도 해당 논문에서 가볍게 다루나요? 또는 논문에서 다루지는 않더라도 어떤 방식으로 BEV 변환을 할 수 있는지 과정을 아시면 알려주시면 감사하겠습니다.
BEV는 point cloud (x y z) 중 y 값을 제거하여 구합니다.
영상 픽셀의 위치 정보 x,y와 각 픽셀에 대응되는 dpeth z로 point cloud (x, y, z)를 생성할 수 있다는 건 아실거라 생각합니다. BEV는 3차원 정보 (x, y, z) 중 높이를 의미하는 y 값이 빠진 (x, z)만 이용하여 2차원 정보로 표현한 방법입니다.
Depth는 real로 사용했을때와 predict했을때의 성능 차이를 보여준 것 같은데 혹시 Segmentation은 유사한 결과 없나요? Segmentation 정보가 GT로 들어갔을때 어떨지 궁금하네요
넵 없습니다… 리뷰에 작성한 실험이 전부이고, 저도 없어서 매우 아쉬습니다…