Introduction
Domain Adaptation의 중요성은 이미 많은 리뷰에서도 언급했으므로 생략합니다. 저자는 오늘 리뷰할 논문에서 존재하는 Adversarial adaptation 방법들의 단점을 다음과 같이 이야기 합니다.
- 기존 존재하는 방법론들은 Semantic feature를 직접적으로 domain discriminator에 입력으로 사용하여 domain confusion learning을 수행합니다. 하지만 Semantic feature는 영상의 content와 domain attribute information을 모두 포함하고 있습니다. 따라서 기존의 제안된 방법으로는 domain attribute information만 제거하도록 만들수는 없습니다. 즉 기존방법은 영상의 content에도 영향을 받게 됩니다.
- 또한 몇몇 논문에서는 데이터셋의 차이에서 나타난 distribution mismatch를 다루기위해 한 개 혹은 약간(few)의 convolution layer에서 confusion learning을 사용합니다. 하지만 이러한 방법은 다양한 representation level에서의 domain shift 를 다룰 수 없습니다. 즉, 초반 레이어에서는 low-level information of local patterns을 후반 레이어에서는 global patterns with semantics를 다루는데, 이러한 부분들이 온전히 반영하지 못합니다.
따라서 저자는 이러한 단점을 극복하기 위한 방법을 제안하고 있으며, 본 논문에서 이야기하는 Contribution은 다음과 같습니다.
- Domain distribution gap을 연결할 Conditional Domain Normalization(CDN)을 제안합니다. CDN은 다른 도메인의 입력들을 shared latent space로 결합(embedding)하여 두 다른 도메인의 입력이 동일한 domain attribute를 갖도록 합니다.
- CDN은 2D image와 3D point cloud detection task에서의 real-to-real, synthetic-to-real benchmark에서 모두 SOTA를 달성하였다고 합니다.
- 2D detection을 위한 large scale의 synthetic-to-real driving benchmark을 구성했다고 합니다.
Method
General Adversarial Adaptation Framework
먼저 일반적인 Adversarial Adaptation Framework에 대해서 소개하고 있습니다.
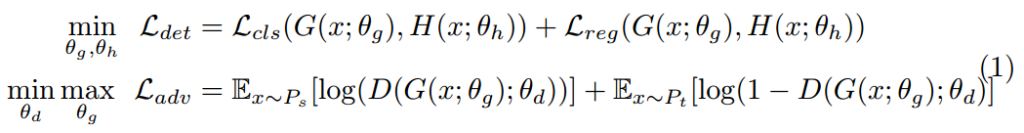
먼저 상단의 식은 supervised training on the labeled source domain에서의 Detection loss입니다. classification과 regression 각 loss의 합을 최소화 하는 것이 목표입니다. 그리고 이때, G는 extractor network이며, H는 bounding box head network입니다. 그리고 하단의 식은 Adversarial domain adaptation이 적용된 식이며 D는 discriminator 를 이야기하며, G는 D가 구별할 수 없도록, D는 G를 구별하도록 min-max game을 통해서 domain invariant representations을 배우게 되는 수식입니다. 수식에서 P_s와 P_t는 source, target을 의미합니다. (해당 수식에 자세한 내용은 링크 )
Conditional Domain Normalization
CDN은 앞서 설명했지만 두 다른 도메인의 입력(source, target)을 shared latent space로 embed하기위해 설계됐습니다. 그리고 shared latent space로 결합된다면, 두 도메인에서 얻은 semantic features는 같은 domain attribute information을 포함하게 됩니다. 이를 수식으로 나타내면 다음과 같습니다.
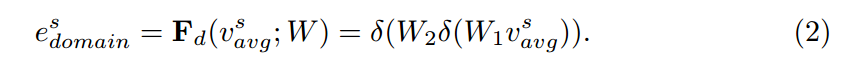
v를 represent feature maps으로 표현하고 s는 source 을 의미합니다. e는 embedding vector를 의미합니다. 이러한 임베딩 벡터는 F라는 domain embedding network에 의해서 만들어지며, F는 2개의 fully-connect layers with ReLU로 이뤄지며 이는 δ로 나타냈다고 합니다. 여기서 그럼 v_avg는 어떻게 만들어지냐면 다음과 같이 Global average pooling에 의해서 만들어집니다.
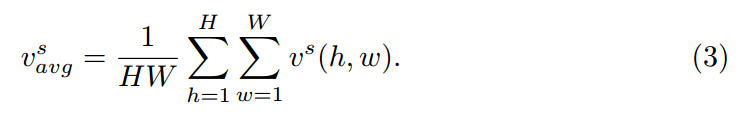
자 그럼 앞에서 source domain의 feature를 나타냈다면, 이제 target domain input을 encode 해야겠죠? 다시 말하지만 최종목표는 shared latent space로 source와 target의 domain inputs을 결합하는 것 입니다. 본 논문에서는 target features를 encode하기위해 source domain으로 affine transformation을 하였고, 이를 수식으로 다음과 같이 나타낼 수 있다고 합니다.
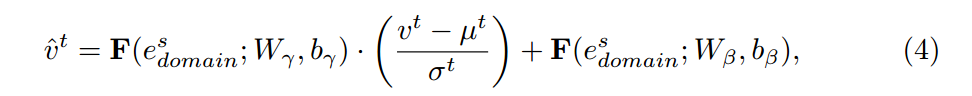
µ, σ는 target feature의 mean과 variance을 의미합니다. 즉 v^t는 target feature를 의미하니까 거기서 평균을 빼고 분산으로 나눠주게 됩니다. 이는 Normalization의 방법인데, 저자는 standard batch normalization을 이용하여 계산하였다고 합니다. 그리고 affine transformation을 수행한다고 하였는데, 여기서 affine transformation의 파라미터는 function F를 통해서 배우게 된다고 합니다. 여기서 F를 보시면 인자로 수식 (2)에서 언급한 source domain의 embedding vector가 포함되며, 이를 자세히 나타내면 다음과 같습니다.
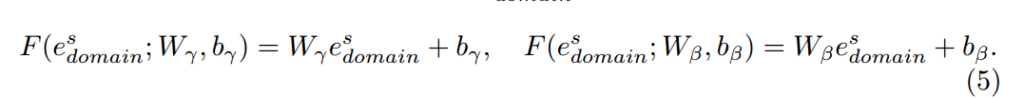
최종적으로 본 논문에서 adversarial adaptation Framework는 다음과 같다고 합니다.
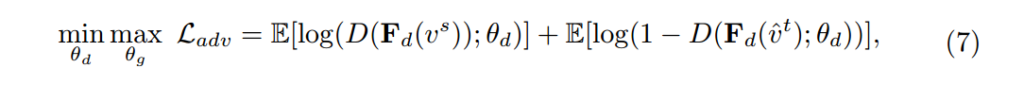
( 수식은 크게 어렵지 않은데 정확히 알려면 코드를 봐야할 것 같지만 공개하지 않네요.. ㅠ)
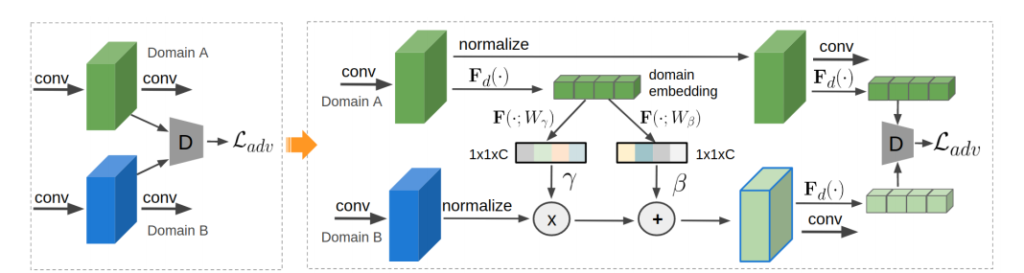
앞에서 언급한 방법들을 나타낸 그림입니다. 왼쪽의 기존 방법들과 대비하여 오른쪽의 자신들의 방법을 나타냈습니다. 저자는 Domain A와 Domain B를 그냥 비교하는 기존의 방법들은 feature에 content와 domain attribute를 모두 포함하는 단점을 가지고 있지만(앞에서 언급함), 자신들의 방법은 feature에서 domain attribute를 분리하고 이를 이용해 다른 도메인의 feature를 인코딩하므로 동일한 domain attribute를 갖도록 한다고 합니다.
Adapting Detector with Conditional Domain Normalization
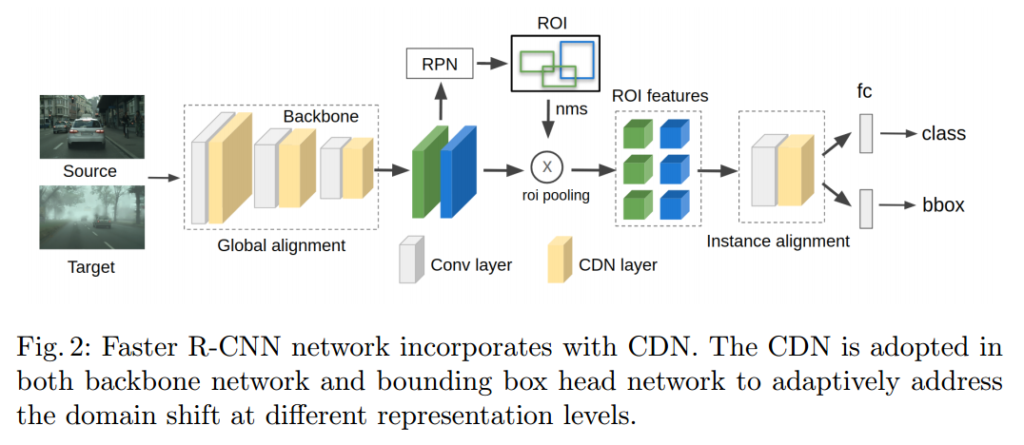
저자는 Detection에 앞서 설명한 CDN을 위의 그림과 같이 적용합니다. 특징적으로는 Detection의 feature level에 따라 다른 특징을 나타낸다는 선행연구에 따라서 모든 레벨(Global, Instance)에 대해서 CDN Layer를 적용했다고 합니다. 각각에 대한 Loss는 다음과 같습니다.
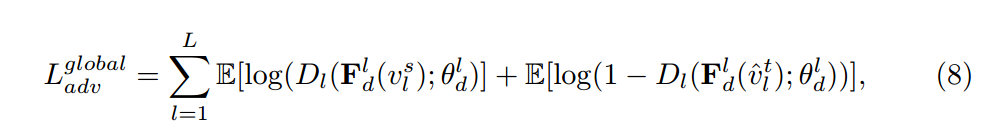
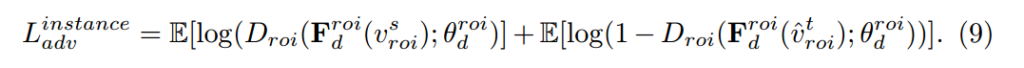
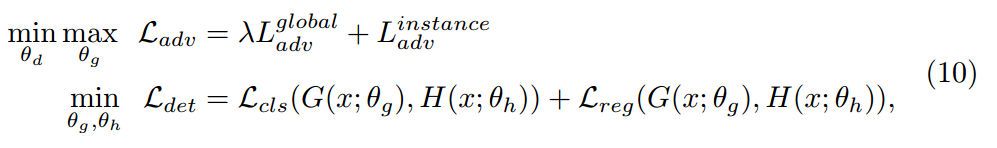
Experiments
본 논문에서는 real-to-real (KITTI to CITYscaapes) , synthetic-to-real(Virtual KITTI/ Synscapes/SIM10K to BDD100K, PreSIL to KITTI)에 대해서 실험을 진행하였습니다. 각 데이터셋에 대한 설명도 논문에 짧게 작성되어있는데 이는 생략하겠습니다.
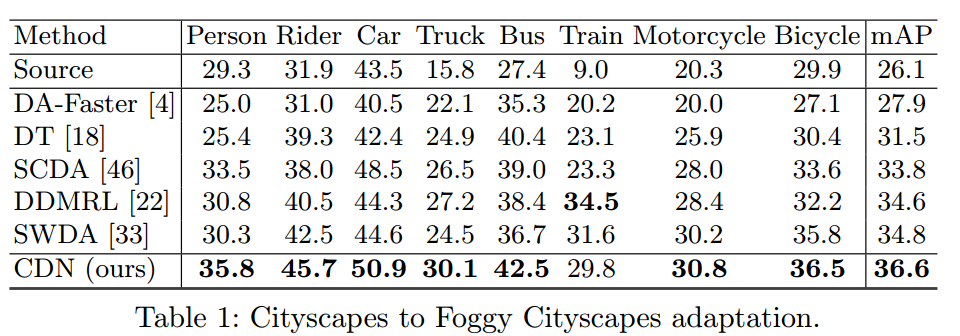
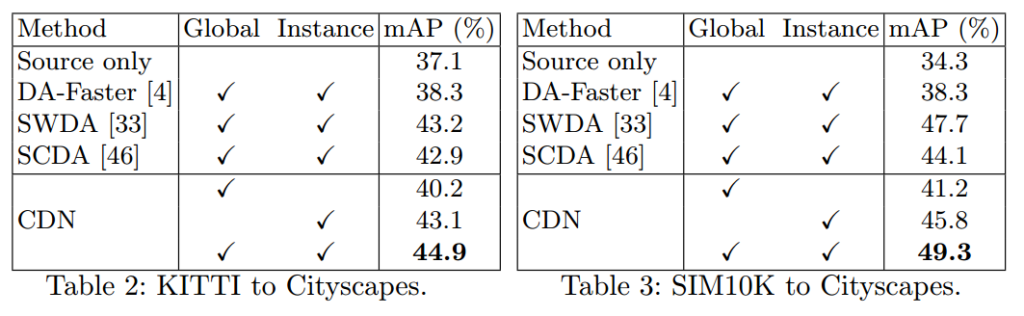
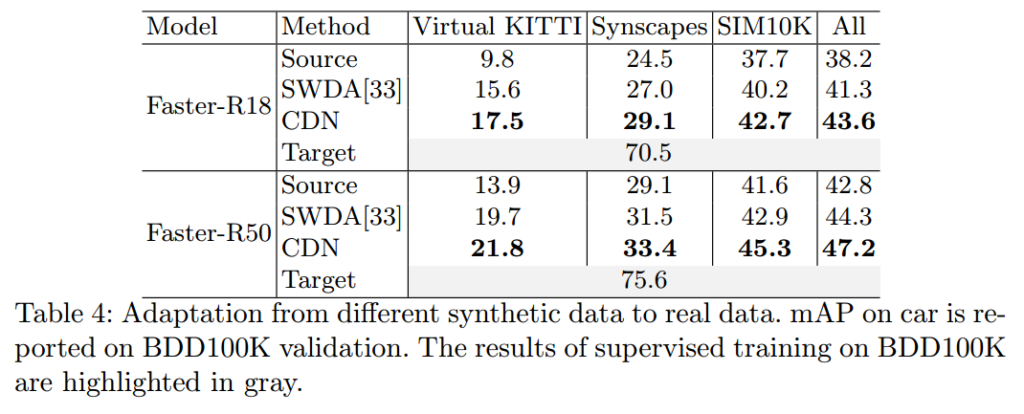
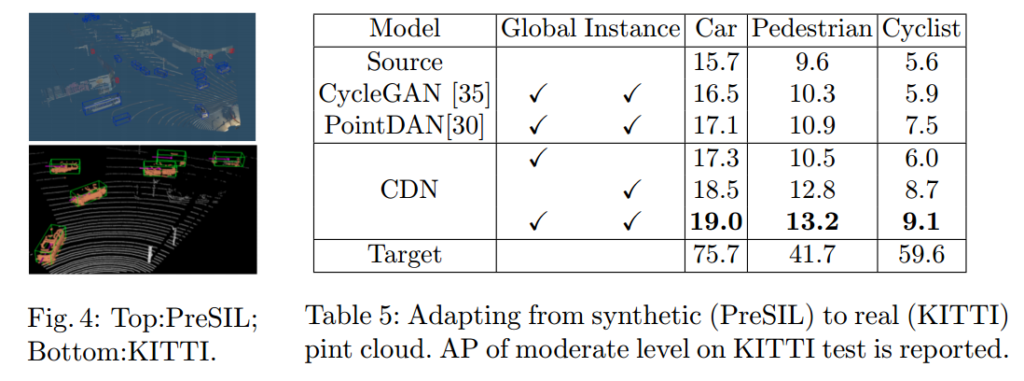
이외에 3D Detection에서도 적용했다고 합니다.
기타 다른 분석도 모두 포함하고있는데 이는 너무 광대하여 생략하고, 더 자세히 살펴본 후 다음주 세미나에서 진행하겠습니다.
결론
제가 찾던 Domain Adaptation을 다루고 있었습니다. ‘real-to-real’ 이 제가 원하는 타겟이며 이와 관련한 논문들을 찾아봐야할 것 같습니다. 또한 해당 논문은 코드를 공개하고 있지 않는데, 관련 코드를 더 찾아보거나 직접 구현해볼 필요성도 있어보입니다.
좋은 리뷰 감사드립니다. 몇가지 질문 드리겠습니다.
질문 1. 무얼 의미하는 Domain adaptation인가요?
Domain adaptation에서 domain이 쓰임새에 따라 구체적으로 의미하는 바가 매우 상이하다는 생각이 듭니다.
김지원 연구원님이 원하시는 Domain adaptation은 RGB-Thermal + 다른 데이터셋에서의 Domain adaptation으로 알고 있습니다.
근데 해당 리뷰에서 이야기하는 Domain adaptation은 같은 씬에서 다른 표현(가상, 안개등)을 의미하는 domain에 해당하는 걸로 보이고 있어 많이 헷갈리네요…
질문 2. Domain adaptation의 분류가 궁금합니다. ++해당 질문은 추가로 조사하셔야한다면 답변 안해주셔도 됩니다.
예전부터 Domain adaptation에 많은 관심을 가지고 계신걸로 알고 있습니다. 저는 매번 Domain adaptation이라는 분야가 매우 넓은 폭을 가지고 있다고 생각합니다. 지금 연구 방향도 모든 task를 포용하는 연구가 진행되는 것이 아닌 한 task에서 작동하는 Domain adaptation이 연구되고 있는걸로 보입니다. 또한 task마다 이야기하는 Domain adaptation도 매우 상이하여 헷갈리더라고요.. 혹시 크게 Domain adaptation는 어떻게 구분이 되는지 알고 싶습니다.
1. 다른 실험결과(테이블 2,3) 보시면 데이터셋 간의 도메인 갭을 줄이기위한 Domain Adaptation를 적용한 결과를 확인하실 수 있습니다. 제가 하고자 하는 내용에 대해서 설명드린적은 없는것 같은데.. 다음 발표때 해당내용을 추가해보겠습니다.
2. 질문하신 내용의 핵심을 이해하지 못했습니다. DA의 구분의 의미를 좀더 설명해주시면 답변드리겠습니다