안녕하세요 이번주 논문은 2018 CVPR에 나온 논문으로 MLPD 후속연구에 활용하기 위해서 일어본 논문입니다. 해당 논문을 읽기전에 혹시 DANN논문을 읽지 않으신분들이 있다면, 제가 남긴 리뷰를 읽고오시길 추천드립니다. 수학적인 내용이 많고 어렵지만 Domain Adaptation에서 근본이 되는 논문이라서 이 분야에 관심이 있다면 반드시 읽어봐야할 논문이라고 생각합니다.
DANN논문을 간단히 요약하자면 Domain간의 Gap 차이를 줄이기 위하여 도메인간의 거리를 나타내는 H-divergence를 정의하고, 이를 줄이는 방향으로 feature representation을 학습하였습니다.
좀 더 자세히 말하자면, 이 때 H-divergence는 이론적으로 무한한개수의 classifier를 통해 구할 수 있는 값이지만, 사실상 불가능하므로 유한한개수의 classifier를 이용하여 구하였고, 실제 H-divergence와의 gap차이를 수식적으로 나타내기위해 statistic learning theory에서 사용하는 방식을 이용하여 upper bound를 설정하였습니다. 즉, true H-divergence의 upper bound의 값은 model complexity + empirical H-divergence 로 나타내었고 이는 또한 proxy-distance로 근사화 되었습니다.
위의 내용이 이해하기 상당히 난해한데요. 제가 세미나에서 발표한 내용이니 참고하시면 좋을거 같습니다.
논문내용

먼저 논문에서는 도메인이 무엇인지에 대해서 설명합니다. 위의 사진을 보시면 각각의 이미지마다 condition이 다릅니다. 예를들어, illumination이 적다거나, foggy하다거나, weather이 다르다거나, 촬영하는데 사용한 카메라가 다르가거나… 여러가지 이유로 각각 이미지는 서로 상이한점들을 가집니다. 이런 것들을 domain이라고 정의하였고, 해당 문제점을 지적합니다. 그 이유는 test환경이 조금만 달라져도 도메인갭이 생겨서 성능저하가 발생할 수 있기 때문입니다.
Domain Adaptation에서의 핵심은 domain이 달라져도 잘 작동하는 모델을 설계하는 것 입니다.
사실 제가 이 논문을 읽게된것은 DANN논문을 응용하여 MLPD에 적용하고자 하였는데 어려운점들이 있었기 때문입니다. 아래에 나열해보았습니다.
- DANN에서는 이미지를 분류하는 classifier를 사용하고, 해당 classifier에서 나온 값을 이용하여 backprob할때 사용한다.
- MLPD는 Conv5 레이어에서 두개의 모달리티가 합쳐진다.
- 위의 내용들을 생각했을때, MLPD에서는 어떠한방식으로 classification score를 뽑고, 어떠한 방식으로 discriminator를 설계하여 backprob해주어야하는가?
- classification score는 instance-level인가? 아니면 image-level인가?
등등… 고민이 많았는데요. 그래서 과연 DA를 object detection에 적용한 논문들은 어떠한 방식을 취했을까 하는 궁금증에 서베이를 하던중에 해당 논문을 찾았습니다. 제가 고민했던 부분을 논문에서 모두 제시하니 좀 신기하였는데 한번 논문을 같이 살펴봅시다.
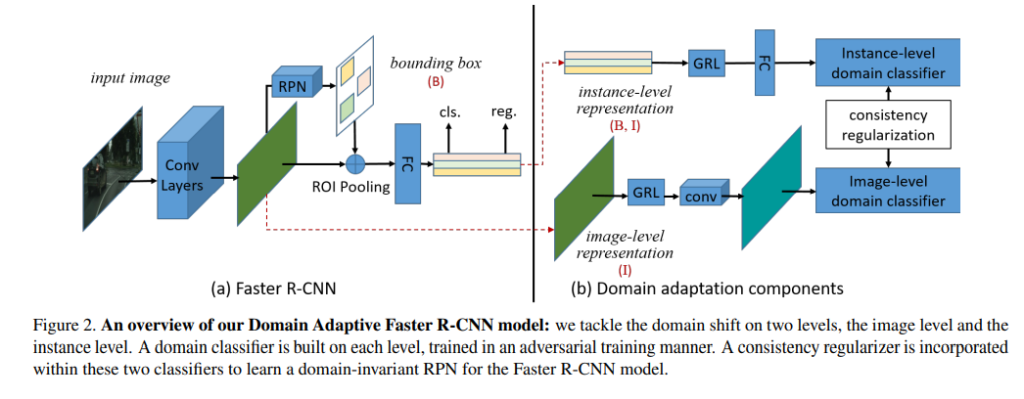
위의 그림은 파이프라인인데요. 수식적인 내용이 논문에서는 먼저나오는데 저는 파이프라인 먼저 설명 후 수식설명으로 넘어가겠습니다. 혼자 DANN을 MLPD에 붙힐 방법을 고민하다가 해당 논문을 보고 속으로 유레카를 외치었는데요. 그 이유는 제가 DANN을 MLPD에 못 붙히겠던 이유는 과연 Classification score를 어디에서 끌어와서 써야하냐 였는데 해당 논문에서는 이를 잘 정리해두었기 때문입니다.
결론적으로 해당 논문에서는 image-level에서의 classification score와 instance-level에서의 classification score를 모두 사용하여 discriminator가 도메인을 분간 못하는 방향으로 학습합니다. 이때, gradient의 부호를 반대로 해주는 Gradient Reversal Layer도 마찬가지로 사용되고요. 이러한 점들을 보면 DANN과 개념이 매우비슷한데 차이점이라면 Object detection task이기때문에 instance level에서의 classification score가 추가되었단 점입니다. 그리고 image-level, instance-level의 consistency를 increase하기 위해 regularization term을 두어서 총 3개의 constraints를 사용합니다.
수식적인 내용은 DANN과 매우흡사하여 이해하기 어렵지 않았으며, 사실 수식적인 내용에 behind story가 많이 생략되었는데 이는 DANN논문에서 아주 자세하게 다룹니다.
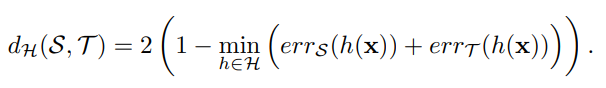
하나씩 살펴보겠습니다. 먼저 위에 식은 H-divergence로 도메인간의 갭차이를 나타내는 distance같은 개념입니다. DA에서의 궁극적 목표는 해당 H-divergence를 최소화하는 feature를 뽑는 것 입니다. 즉, source 도메인과 target도메인간의 gap차이를 줄이는 것이 목표이고 이를 위해 H-divergence를 정의하여 수식화 한 것입니다.
수식의 의미를 살펴보면 H라는 classifier space상에 h라는 classifier 원소에 대해서 위와 같은 연산을 수행합니다. 즉, source도메인과 target도메인에서의 samples에 대하여 discriminator가 분간 못할 확률을 각각 더하고 이 값이 가장 작은 classifier를 선정합니다. 그리고 해당 classifier에 대해서 위의 연산값이 바로 H-divergence값 입니다. 물론 이는 classifier의 space가 infinite하지 않기 때문에 실제 true H-divergence값과는 차이가 있습니다. 이러한 내용은 제가 저번주에 리뷰한 DANN논문에서 자세히 다루며, 이번 리뷰에서는 생략하겠습니다.
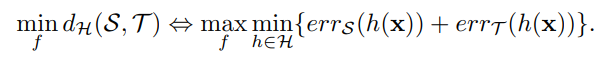
어찌됐건 H-divergence값을 줄이기 위해서는 위의 min이하 값의 최대값을 찾는 것이 필요합니다. 즉, feature를 비슷하게 하도록 학습하기 위해서는 위와같은 연산이 필요합니다. 해당 연산은 h라는 classifier가 분간을 못하도록 학습을 하면 H-divergence, 즉 도메인간의 갭이 줄어든다는 것을 의미합니다.
이론은 복잡햇으나 loss term은 비교적 간단합니다.
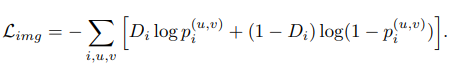
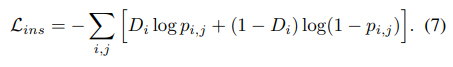
일반적인 image와 instance-level에서의 binary classification을 위해 sigmoid cross-entropy loss를 사용됩니다.
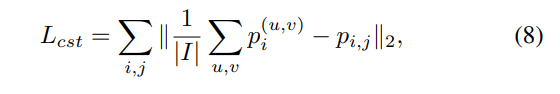
여기에 추가적으로 L2 Regularization을 사용하여 Image-level과 instance-level에서의 discriminator의 판별값에 consistency term을 부여합니다. 즉, instance-level이던 image-level이던간에 discriminator는 둘다 비슷하게 헷갈리게끔 constraint를 부여한 것 입니다.
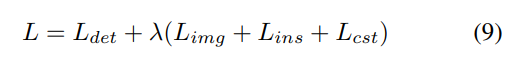
그리고 해당 텀들을 합쳐서 Loss항으로 정의하는데 람다같은 가중치를 곱해서 더하는건 다른 논문들에서 사용하는 방식과 비슷한거 같습니다.
평가
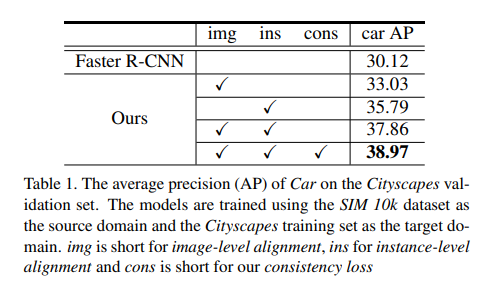
평가입니다. car class에 대해서만 했으며 Sim->Cityscape 로 source, target 도메인을 했을때 결과입니다. 각각의 componetn들을 추가했을때 성능향상을 보이긴 했는데, 제가 생각했던거 만큼 엄청나게 성능이 좋거나 하진 않네요. 역시 Supervision에 비하면 한참 떨어지는거 같습니다.
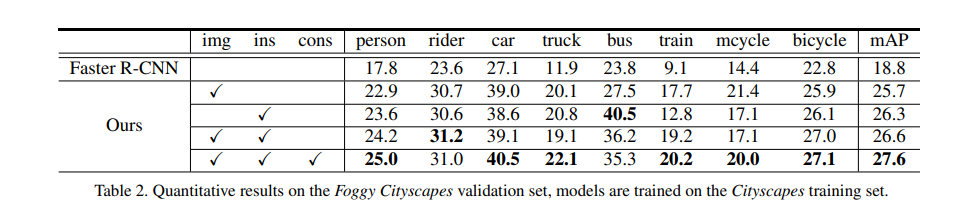
비슷한 맥락의 실험결과입니다. target과 source 도메인만 바뀌었네요.
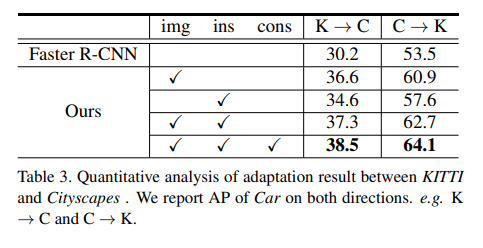
마찬가지 입니다.

해당 그림에서는 correct/mislocalization/Background 라는 개념이 추가되었는데요. IoU기준으로 GT와 얼마나 overlap되었나에 따라 나눈 것 입니다. 0.5이상은 correct, 0.3~0.5는 mislocalization, 그리고 0.3이하는 배경을 False positive로 잘못 인식했다라고 생각하시면 됩니다.
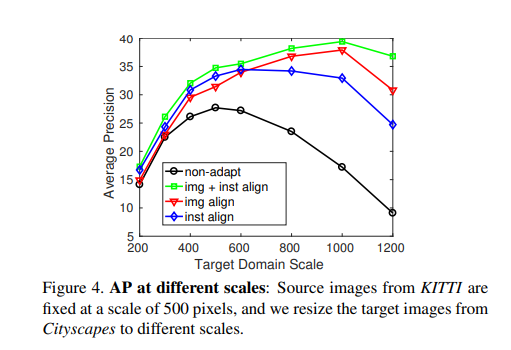
AP against target domain scale에 대한 결과입니다. Image-level과 Instance-level을 모두 고려하였을때 성능이 가장 좋을것을 알 수 있습니다.
요약 및 소감
해당 논문은 DANN에서 소개하는 Domain Adaptation 개념을 Object detection에 적용한 논문으로 MLPD 후속연구를 위해 읽었습니다. DANN을 MLPD에 적용하려고했을때 막히던점들을 해당논문을 통해 영감을 많이 얻을 수 있었습니다. 성능이 조금 아쉬운거 같긴하지만, 개인적으로 현재 DA분야가 어느정도 까지 올라왔는지 몰라서 이정도 성능이면 만족할만한 수준인지 잘 감이 안잡힙니다. 2018 CVPR논문인데 최근 2021년 논문들은 어느정도 성능을 보이는지 읽어볼 필요가 있는거 같습니다.
Target으로 학습한 모델의 결과와는 따로 비교하고 있진 않나요..?
넵 그러한 실험내용은 논문에서 다루지 않고있네요.