해당 논문은 spatio, temporal 정보를 이용한 video augmentation을 통해 contrastive learning을 진행한는 방식을 소개한 논문이다.
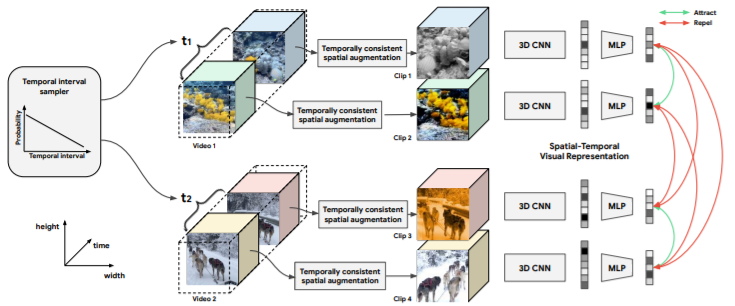
- Temporal Augmentation
하나의 비디오에서 두개의 clip을 positive pair로 사용하는 방식이다. 이때 다른 방식과의 차이점은 sampling 전략이다. clip을 얻는 과정은 다음과 같다.
1. P(t)의 분포에서 시간 구간 t를 정합니다.
2. [0,T]길이의 비디오가 있을 떄 [0, T-t] 구간에서 uniform하게 sampling하여 clip을 생성합니다
3. 첫번쨰 클립이 t만큼 지연된 것을 두번째 clip으로 합니다.
여기서 P(t)는 무엇이고 t는 어떻게 정하는 것일까를 추가로 소개하면 다음과 같다.
P(t)는 주어진 sampling probability 분포이다. P(t)의 정적분형태를 F(t)라 하며 그 미분함수 F'(t)에 (0,1) 구간의 랜덤 변수를 입력으로 하여 t를 얻는다.
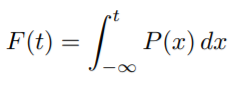

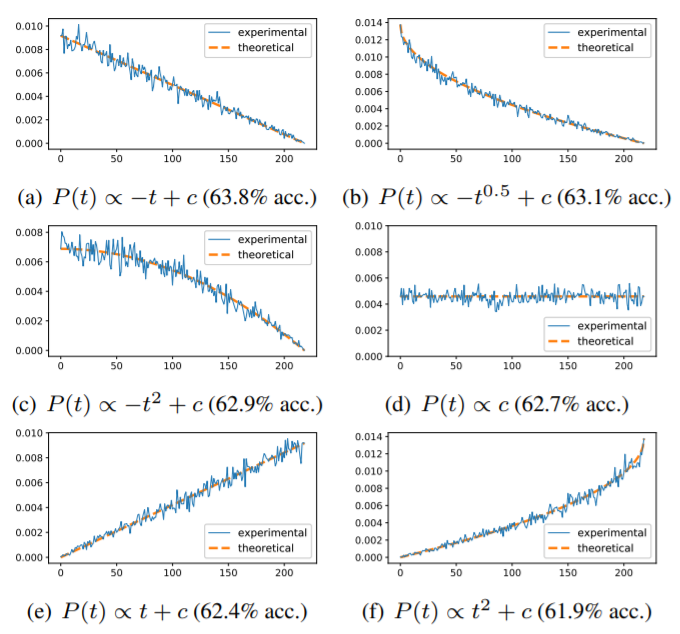
해당 논문에서는 위의 6가지 P(t) 함수로 실험하였을 때 감소하는 분포의 (a,b,c) 함수가 다른 분포의 함수보다 비교적 더 나은 성능을 보였다고 확인하였다.
2. Spatial Augmentation
spatial augmentation은 image 에 대한 unsupervised learning에서도 많이 등장하는 방식이다. 해당 논문은 기존의 spatial augmentation 방식에서 random cropping, color jittering, blurring과 같은 방식들을 사용하지 않았다. 이러한 randomness는 비디오에서 frame간의 연속성을 해칠 수 있기 떄문이다. video의 연속성을 해치지 않는 augmentation을 위해 비디오 클립 전체에 대한 augmentation을 제안하여, 기존의 frame 단위로 랜덤성을 통해 augmentation 하는 방식에서 clip단위로 랜덤성을 갖도록 제안하였다.

제안하는 방식은 clip 단위로 변형을 한다(3행)
제안하는 방식에 대한 ablation study는 다음과 같다.
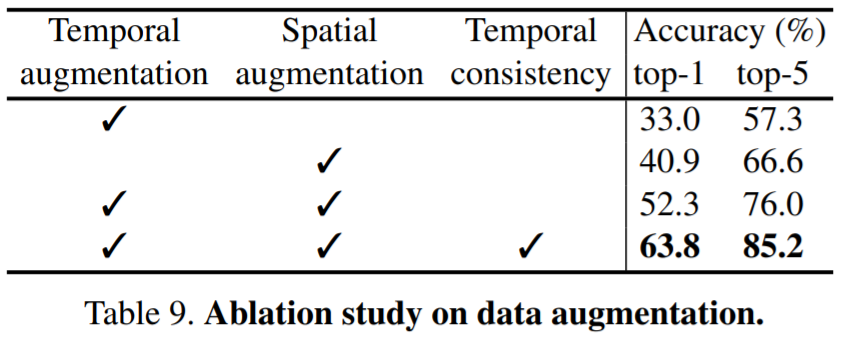
다음으로 모델의 featrue 표현력을 확인하기 위해 학습한 backbone을 고정시키고 linear classifier로 분류를 진행하는 Linear evaluation 성능을 리포팅하였다.
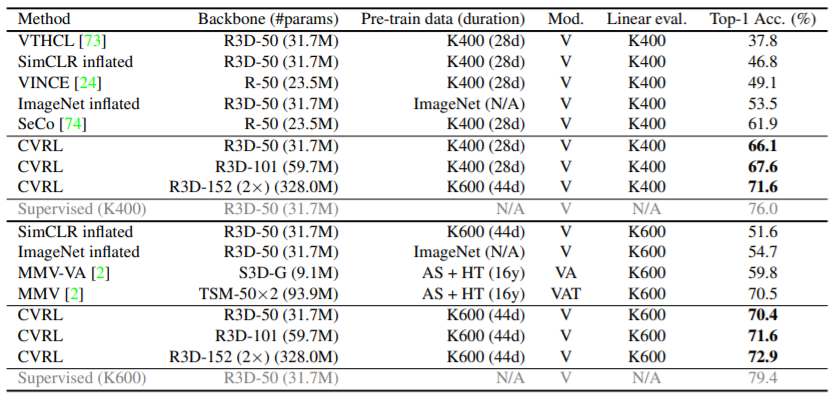
마지막으로 해당 방식으로 학습한 feature의 downstream성능을 확인하기 위해 action detection(AVA)과 action classification (UCF-101)을 진행하였다.
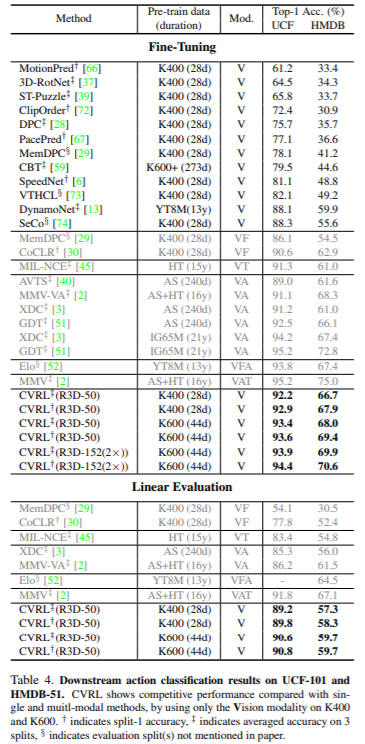
제안하는 방식이 Vision only 방식에서 높은 성능을 보임을 확인할 수 있음.
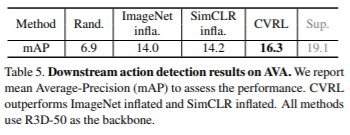
성능향성폭이 너무 큰데?
늦은 답변 죄송합니다
성능 향상폭이 큰 ablation study의 경우 1,2행의 경우 temporal 혹은 spatial augmentation을 아예 적용하지 않은 경우로, 각각을 비교하기 보다 3행과 4행의 성능 향상폭(top1:11.5)이 더 의미있다고 생각했습니다!
(논문의 제안점이 temporal 정보를 손상시키지 않고 기존 augmentation 방식에 spatial augmentation을 붙이는 것이므로
기존 방식도 temporal augmentation과 spatial augmentation을 모두 사용은 했을 것이라 생각하여서 1행 2행과의 비교보다 3, 4행간의 비교가 더 중요하다고 생각하였습니다)