이번에 제가 리뷰할 논문은 저번주에 리뷰한 논문( ADDA: Adversarial Discriminative Domain Adaptation )의 동일 저자의 후속 연구입니다. ADDA를 기반으로 작성된 논문으로 저번주 리뷰를 함께 읽으면 도움이 될 것 같습니다 🙂
CyCADA: Cycle-Consistent Adversarial Domain Adaptation – [ 논문 바로가기 ]

[ 1 ] Introduction
ADDA에서 언급한 것과 마찬가지로, Deep neural network는 아무리 대규모의 데이터셋으로 학습한다고 하더라도 새로운 데이터셋에 대해 일반화하는 것에는 한계가 있습니다. 이를 극복하기 위해 실제 이미지와 비슷한 대규모의 합성 데이터를 사용하곤 하지만 여전히 제한적이기 때문에 “Feature-level Unsupervised Domain Adaptation” 방법론이 이를 극복하고자 연구되고 있습니다.
Feature-level Unsupervised Domain Adaptation은 source^*와 target^* domain 간의 차이를 정렬하여 라벨이 없는 target^* 데이터 즉 unseen 데이터에 대해 성능이 떨어지는 문제를 해소하고자 합니다. 그 대표적인 방법론이 제가 저번주에 리뷰한 ADDA 입니다.(참고로 ADDA 논문에서는 source를 target으로 매핑시킨다는 표현을 썼는데 여기서는 align 정렬한다는 표현을 쓰네요. 참고로 정렬하는 방법으로는 두 분포의 feature 분포 사이의 거리 측정 등이 있습니다.)
cf. source^{*}, target^{*} : 보통 Domain Adaptation에서는 source를 train 데이터로, target을 test 데이터를 대신하여 표현합니다
그러나 이런 Feature-level Unsupervised DA 방법에도 두 가지 이슈가 있는데 하나는 semantic consistency를 잃는다는 것이고, 두번째는 higher level의 deep 한 표현 정렬에 치중되어 pixel-level이나 low-level domain shift 측면 잘 잡아내지 못하는 것입니다. (semantic consistency에 대한 내용은 뒷 단원에서 다루도록 하겠습니다) 따라서 본 논문에서의 main idea를 한 문장으로 정리하자면, ADDA에 sematic consistency를 적용하여 pixel-level과 feature-level 모두에서 표현을 조정할 수 있도록 CycleGAN을 추가한 것입니다. 서론이 길었지만 결국 정리하면 ADDA에 CycleGAN을 추가한 CyCADA(Cycle-Consistent Adversarial Domain Adaptation) 을 제안한 논문입니다.
[ 2 ] Cycle-Consistent Adversarial Domain Adaption
CyCADA의 구조는 다음 그림 2와 같이 정리할 수 있습니다.
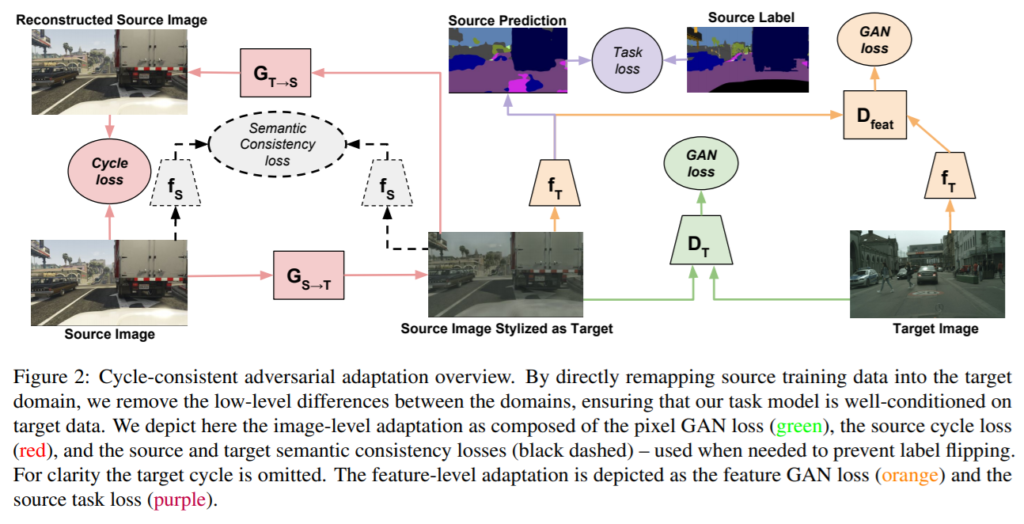
- Pretrain Source Data -> [ 2 – 1 ]
- Source image를 Target Styled Image(=Source image Stylized as Target)로의 변환 with CycleGAN -> [ 2 – 2 ]
- ADDA를 이용하여 Target Styled Source Image와 Target Image를 함께 학습 -> [ 2 – 3 ]
우선 Step1과 같이 CycleGAN을 통해서 source image를 target styled image로 변환합니다. 여기서 CycleGAN과의 차이점이 있다면 바로 Semantic Consistency 를 고려하기 위해 Loss를 추가했다는 점입니다. Semantic Consistency는 예를 들어 MNIST dataset에 포함된 2를 USPS dataset style로 변환 시, 변환된 이미지가 숫자 2를 유지하면서 변환되도록 하는 역할을 합니다. 이런 제약조건을 주지 않으면 아래 그림 4 같이 비슷하게 생긴 9로 바뀌는 등의 문제가 발생하게 됩니다.


그 다음으로 Step 2 에서는 ADDA와 같이 Source Image Stylized as Target image와 Target image를 이용하여 Discriminator는 두 이미지를 잘 구분하도록, 동시에 target과 translation image의 f_T output인 feature가 서로 비슷해보이도록(구분하기 어렵도록) 학습됩니다. 이 때, CycleGAN을 통해서 pixel-level에서는 거의 비슷하게 보이도록 변환이 되었지만 feature-level에서는 여전히 구분히 될 여지가 있는데 ADDA를 통해서 이를 완화할 수 있게 됩니다.

[ 2 – 1 ] Pretrain Source Task Model
- Notation
- source data X_S
- source labels Y_S
- target data X_T, but no target labels
- Goal
- to learn a model f_T : target 데이터 X_T에 대해 올바른 라벨로 예측하는 모델
ADDA와 동일하게 먼저 X_S와 Y_S에 대한 모델인 f_S를 구하기 위해 학습합니다. cross-entropy loss를 사용하는 K개의 분류에 대한 수식은 아래 (1) 과 같습니다. 그러나 f_S는 source data에 대해서만 좋은 성능을 가지지만, 일반적인 source to target domain shift는 target 데이터를 평가할 때 성능 저하로 이어진다고 합니다.
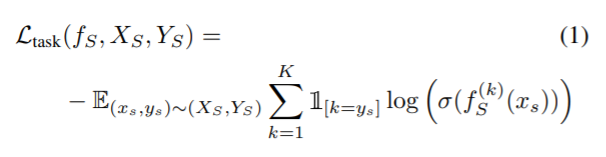
[ 2 – 2 ] Pixel-level Adaptation (Cycle-GAN)
이번 단계 역시 ADDA과 비슷하다고 생각하면 이해하기 쉽습니다. ADDA에서는 Discriminator가 source domain인지 target domain인지 잘 구별하도록 학습되는 동시에 target encoder는 Discriminator가 구분을 잘 할 수 없도록 최대한 source domain에 비슷한 output을 내도록 학습됩니다. CyCADA에서도 마찬가지로 Adversarial Discriminator가 domain을 구별할 수 없도록 여러 도메인에 걸쳐 Source와 Target을 common space로 매핑하는 방법을 학습합니다.
그러나 ADDA에서는 Generator 없이 Source에 대한 feature을 추출하는 것을 통해 target으로의 apaptation을 수행됐다면, 반면 CyCADA에서는 image-level 즉, Source를 Target image Style로 변환하는 Generator가 존재합니다. 이후, 변환한 image에 대해 Discirminator가 구분할 수 없도록 feature를 추출한다는 과정은 동일합니다. 따라서 이에 따른 GAN Loss 함수는 수식 (2)와 같습니다. 즉, common space로 매핑하기 위해 CyCADA에서는 source에서 target으로 매핑하는 G_{S->T}를 제안하고, Adversarial Discriminator D_T를 속이는 target sample을 만들도록 학습됩니다.
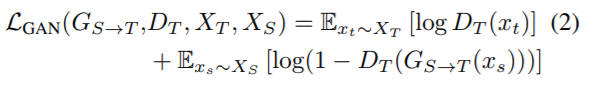
수식 (2)의 목표는 G_{S->T}가 주어진 Source를 통한 설득력있는 Target을 생성하는 것입니다. 또한 도메인을 직접 매핑하여 target model인 f_T를 학습할 수 있습니다. 그러나 실제로는 성능 보존에는 어려움이 있어, Translation 동안 source 보존을 위해 앞서 언급한 Semantic Consistency Loss를 추가합니다. 이는 수식 (3)과 같습니다.
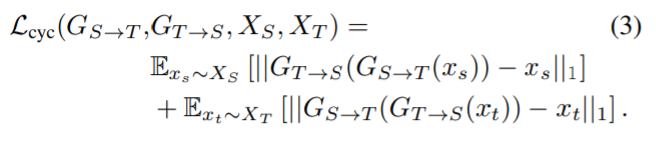
source에 대한 라벨은 알고있기 때문에, high semantic consistency 가진 이미지 변환을 수행할 수 있습니다. 이 때, pretrain된 source task model인 f_S를 noisy labeler로 사용하여 translation 전과 같은 방식으로 이미지를 분류하는 노이즈 레이블로 사용합니다. 이에 대한 loss는 수식 (4)와 같습니다.
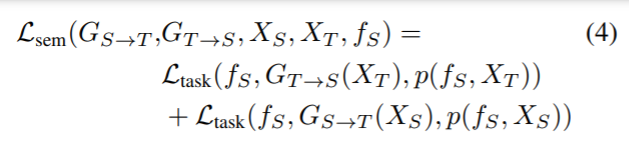
[ 2 – 3 ] Feature-level Adaptation (ADDA)
이제 Cycle-GAN을 사용한 이미지 생성이 완료되었다면, Translation image와 target image의 feature를 추출하는 f_T를 학습하기 위한 loss는 다음과 같습니다.
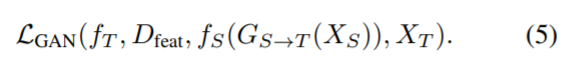
따라서 지금까지 나온 수식을 종합하면 아래 수식 (6)과 같이 어마무시한 수식이 나오게 됩니다.
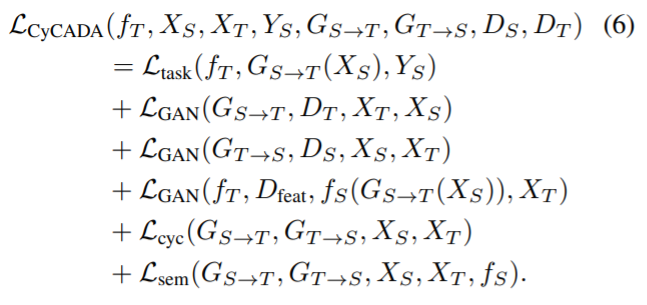
이 loss 함수는 궁극적으로 target 모델인 f_T를 최적화하는데 사용되는 것이죠..
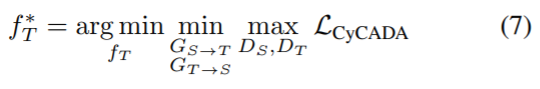
[ 3 ] Experiments
본 단원에서는 CyCADA를 여러 Unsupervised Adaptation 상황에 대한 평가를 진행합니다. 먼저 기존 ADDA에서도 진행했던 MNIST, USPS, 그리고 SVHN 데이터셋에 대한 Digit Classification에 대한 실험 결과를 보여줍니다. 다음으로 기존에는 하지 않았던 Semantic image Segmentation 실험 결과를 제시하는데, 이 때 데이터셋으로는 GTA와 CityScape 을 사용하였다고 합니다.
[ 3 – 1 ] Digit Adaptation
ADDA 와 마찬가지로 다음 세 가지 Unsupervised DA에 대한 실험 평가입니다.
Target -> Source
(1) MNIST -> USPS
(2) USPS -> MNIST
(3) SVHN -> MNIST
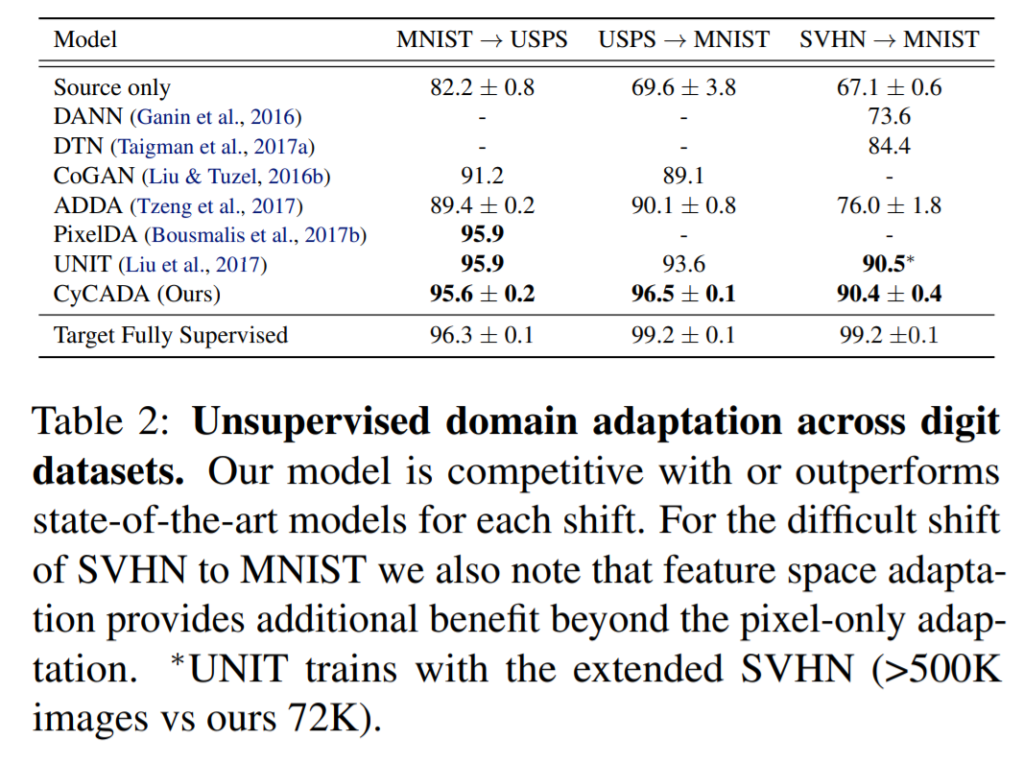
아래 Table 2 를 통해 전반적으로 기존 방법론들에 비해 평균적으로 성능이 뛰어난 것을 확인할 수 있습니다.
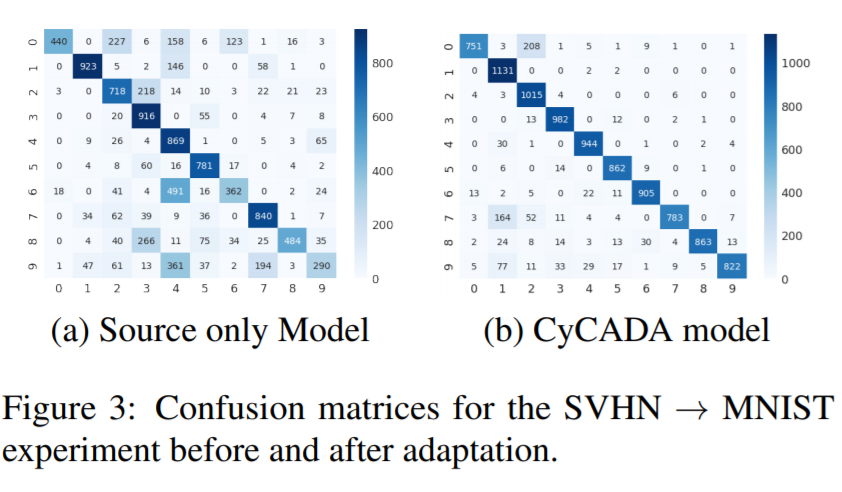
아래 Confusion matrix 그림 (3) 을 통해 SVHN to MNIST Adaptation이 제대로 적용되었는지를 보여줍니다. Adaptation을 적용하기 전에는 0-2, 4-7, 6-4, 8-3, 9-4를 헷갈리는 것을 확인할 수 있으나, Adaptation 후에는 에러가 꽤 줄어든 것을 확인할 수 있습니다. 다만 여전히 7-1, 0-2에 대해 헷갈리는 경우를 볼 수 있는데 이 에러의 경우 hand-written 숫자라는 것으로 인해 발생한다고 볼 수 있다고 합니다.
[ 3 – 1 ] Semantic Segmentation Adaptation
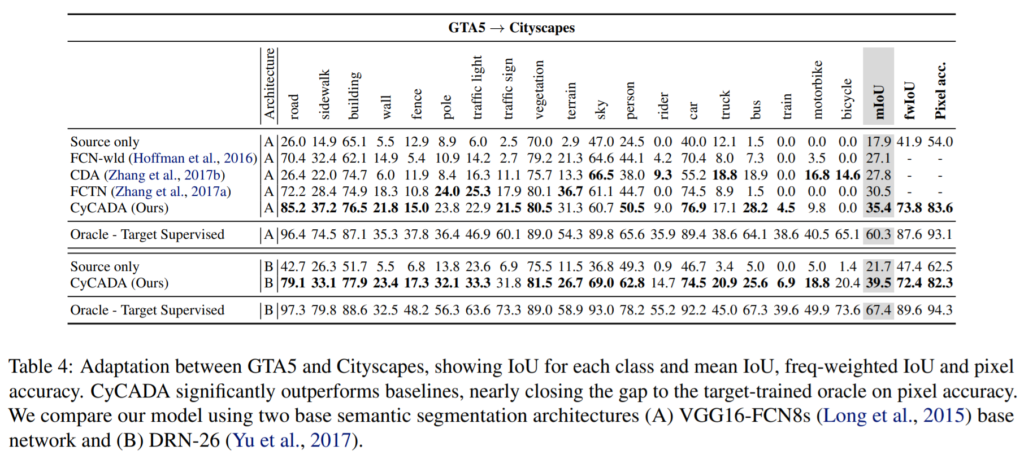
두번째로 특이하게도 Semantic Segmentation에 대한 DA 성능을 보여줍니다. 데이터셋으로는 GTA와 Cityspace를 사용했는데 Source는 Cityspace로 Target은 GTA로 설정하여 GTA5 -> Cityspaces task에서의 성능을 보여줍니다. 이 때 성능은 CycleGAN, ADDA가 각각 효과적이지만 이 둘을 합쳤을 때 가장 성능이 우수하다는 점을 Table 4에서 확인할 수 있습니다. 올해 CVPR 2018에 나온 Learning to Adapt Structured Output Space for Semantic Segmentation 이라는 논문에서도 같은 실험을 했었는데 동일한 아키텍쳐에 대하여 mIoU가 35.0 정도 수준이였습니다. CyCADA는 직관적이고 구현하기도 쉽지만 높은 성능을 보여준다는 것을 다시 한 번 확인할 수 있습니다.
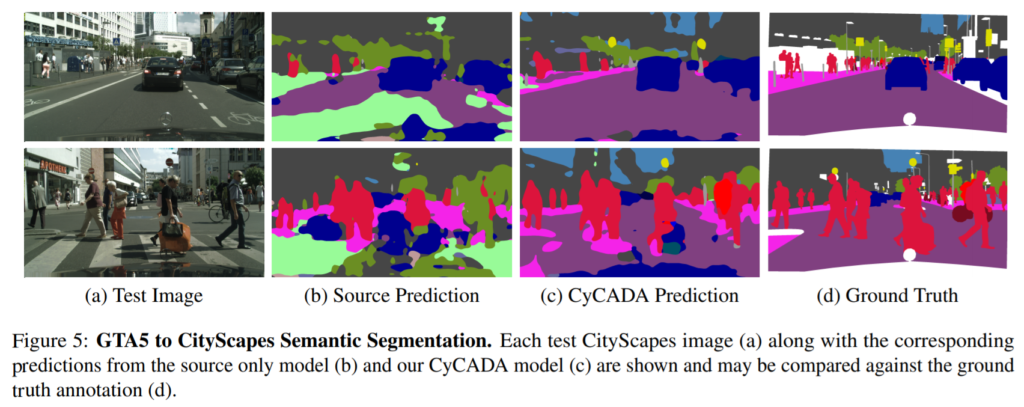
GTA5를 CityScape Semantic Segmentation한 정성적 결과는 아래 그림 5에서 확인할 수 있습니다.
GTA5를 CityScape로 Translation한 정성적 결과는 아래 그림 6에서 확인할 수 있습니다.

기존 ADDA는 Generator 없이 source 에서 target feature로 바로 domain adaption을 진행하기 때문에.. 어느정도 한계가 있지 않을까 라고 생각이 들었습니다만.. 이 간격을 줄이고자 Generator를 통한 1단계 이미지 변환 후 feature adaptation이라니 .. Generator를 사용하겠구나 예상은 했지만.. 성능과는 별개로 이런 생각을 하는게 신기할 따름입니다. 이제부터는 논문을 단순히 읽고 결과를 받아들이기 보다는 이를 적용할 수는 있을지, 혹은 이 실험을 통해 무엇을 알 수 있을지 비판적으로 읽는 습관을 길러야겠습니다.