

이전부터 컴퓨터 비전에서는 특정 Center의 의미를 부여하고 local descriptor를 할당해 global descriptor를 기술하는 VLAD 기반 방법론들이 좋은 성능을 보였었습니다. 딥러닝이 발달하기 시작하며, Center까지 학습하는 NetVLAD라는 방법론 또한 Image Retrieval 분야에서 좋은 성능과 함께 등장하였고 그 이후에 여러 후속 방법론들도 등장하였습니다. 오늘 리뷰할 논문은 앞서 언급했던 것처럼 VLAD encoding 기반 Text to Video alignment로 직접적인 유사도 비교를 하여 Text-to-Video Retrieval 문제의 해결책을 제시한 “T2VLAD: Global-Local Sequence Alignment for Text-Video Retrieval” 입니다.
1. Method
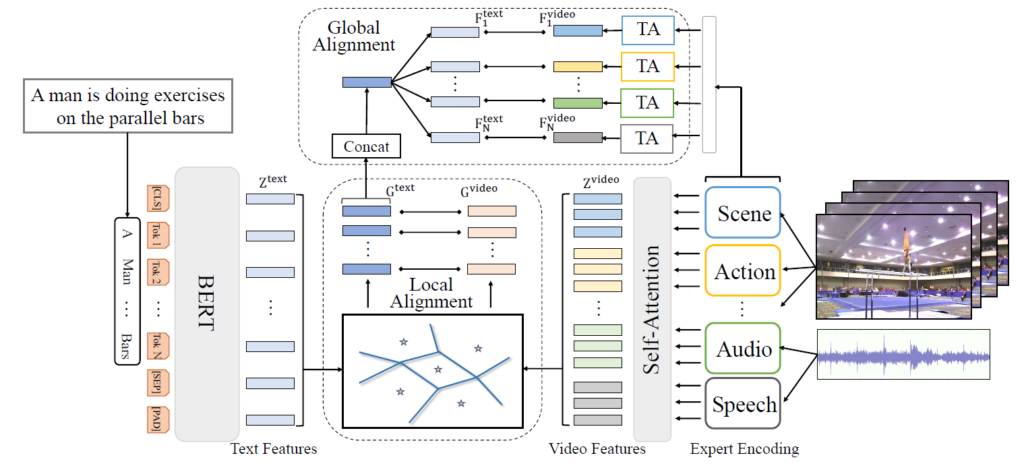
T2VLAD는 Text와 Video를 입력으로 둘 간의 유사도를 계산해주는 방법론 입니다. Text와 Video의 local한 semantic alignment를 위해 semantic center 학습 방식을 제안하였으며, Text와 Video 모두 shared center를 활용한 VLAD encoding으로 두 도메인 간의 semantic gap을 줄이고자했습니다. 제안된 방법은 Video Representation, Text Representation, Local Alignment, Global Alignment로 총 4 가지 순서로 구성되며 아래에서 각 순서별로 설명드리겠습니다. 참고로 이후 나오는 표현에서 global의 범위는 video-level을, local의 범위는 segment-level을 뜻합니다.
1.1 Video Representation
Video 에서는 Image 정보 뿐만아니라 Action, Audio, Speech 등과 같은 여러 multi modal information을 활용합니다. 여러 multi modal information을 처리하기 위한 backbone과 같은 방법론들을 experts라고 표현하며, N개의 multi modal experts에서 각 비디오 별로 segment-level의 multi experts feature를 T 개 추출합니다. 그리고 추출된 T x N feature를 이후 Global alignment에 활용하기 위해 max-pooling 하여 N개의 global expert feature F^{video}를 생성합니다. 이와 별개로 Local alignment에 활용하기 위해서 self-attention을 적용하여 local feature Z^{video}를 생성하며, 이때 self-attention layer는 local feature의 locality를 유지하기 위해 transformer 내의 하나의 encoder로 활용되었습니다.
1.2 Text Representation
Text를 입력으로 받을 때는 Pretrained된 BERT 모델로 local feature와 global feature 를 추출하여 사용합니다. 이외의 추가적으로 특별한 내용은 없습니다.
1.3 Local Alignment
앞서 얻은 Video local feature와 Text local feature는 서로 수가 달라 직접적인 일대일 유사도 비교가 어려운 단점이 존재합니다. 이를 해결하기 위해 NetVLAD에서 center를 활용하는 것처럼 T2VLAD 또한 Video local feature와 Text local feature를 각각 semantic center 에 할당해 G^{text}, G^{video}를 생성합니다. 그리고 생성된 G^{text}, G^{video} 간의 cosine similarity를 local similarity로 활용합니다.
1.4 Global Alignment
기존 VLAD 방법론들은local alignment만으로 global representation 하였으나, T2VLAD는 Global Alignment 과정이 추가되었습니다. 이는 global feature가 local feature의 상호 보완적이라는 점과 video-level의 supervision 정보에 비해 segment-level의 supervision 정보가 부족하여 optimization이 어렵기에 이를 완화하고자 하는 점을 이유로 추가되었습니다. Global alignment 과정에서는 우선 G^{text}를 모두 concatenate 하여 하나의 벡터로 변환한 뒤, video global experts feature F^{video}의 수인 N 개만큼 copy 하여 N개의 F^{text}를 생성하는 것으로 시작합니다. 이후 F^{text}와 F^{video} 를 weight sum 하여 global similarity를 계산하되, 사용되는 weight는 G^{text}를 linear projection하고 softmax normalization 한 값으로 설정합니다. 마지막으로 두 가지의 alignment에서 구해진 similarity의 평균을 최종 text-video similarity로 선정하며, NetVLAD와 같은 방식으로 학습을 진행합니다.
2. Experiments
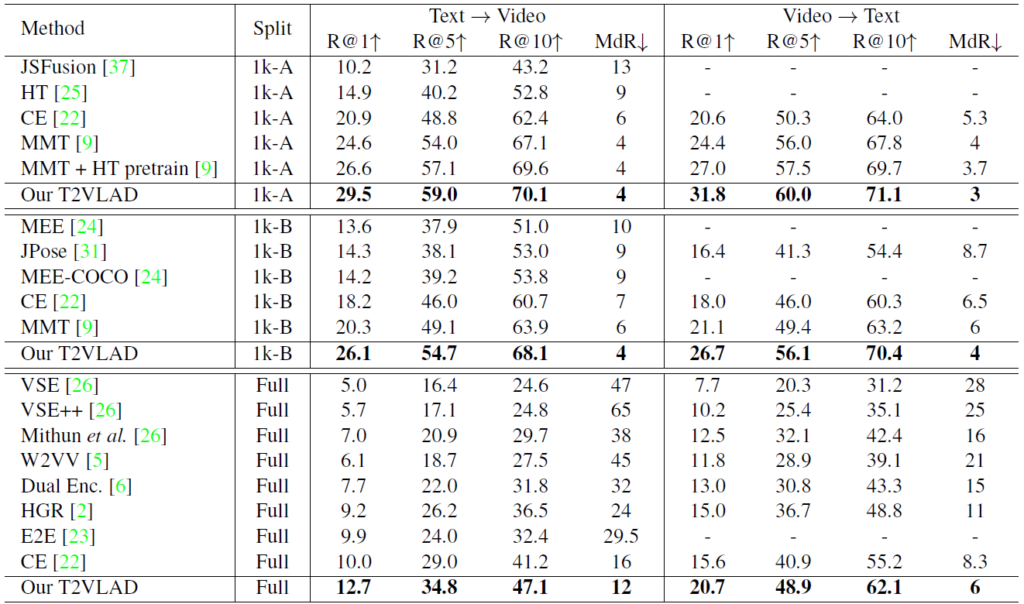

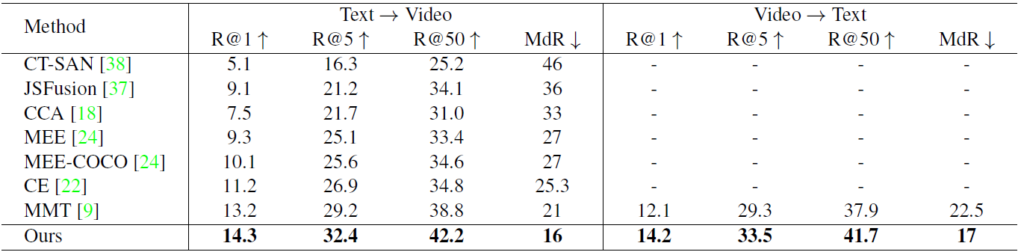
Table 1, 2, 3은 모두 Text-Video Retrieval 분야에서 자주 사용되는 Dataset 별로 SOTA와 T2VLAD의 성능 비교 테이블 입니다. 평가지표는 R@K(Rank K)와 MdR(Median Rank)가 사용되었으며 전자의 경우 높을 수록 후자의 경우 낮을수록 좋은 성능을 보인다고 생각하시면 됩니다. 모든 데이터 셋에서 이전 SOTA 들과의 성능 차이의 폭이 꽤 되는 것을 알 수 있습니다.


Table 4는 두 종류의 Alignment가 미치는 영향을 확인하기 위한 ablation study 입니다. 기존 VLAD 방법론에서 주로 사용하던 Local Alignment를 제거했을 때의 성능 하락 폭이 더 높은 것을 보이긴 하나 Global Alignment를 제거했을 시에도 꽤나 큰 성능 하락 폭을 보여 다른 SOTA 방법론보다 낮은 성능을 보입니다.
Table 5는 VLAD encoding 방식에서 semantic center의 shared 여부에 따른 ablation study 입니다. 해당 실험으로 서로 다른 두 도메인에서 같은 semantic center로 alignment 하여 비교한 것의 효용성을 알 수 있습니다.
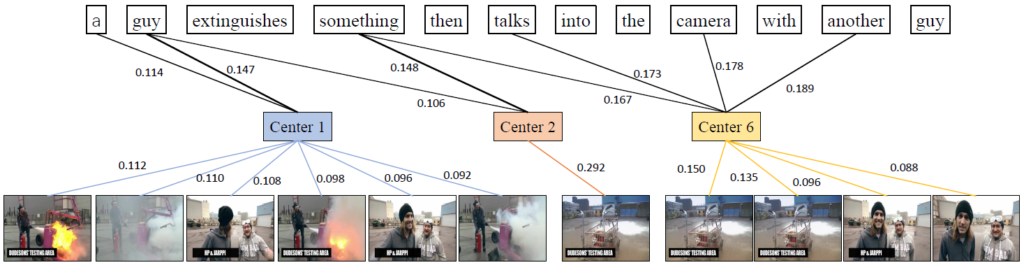
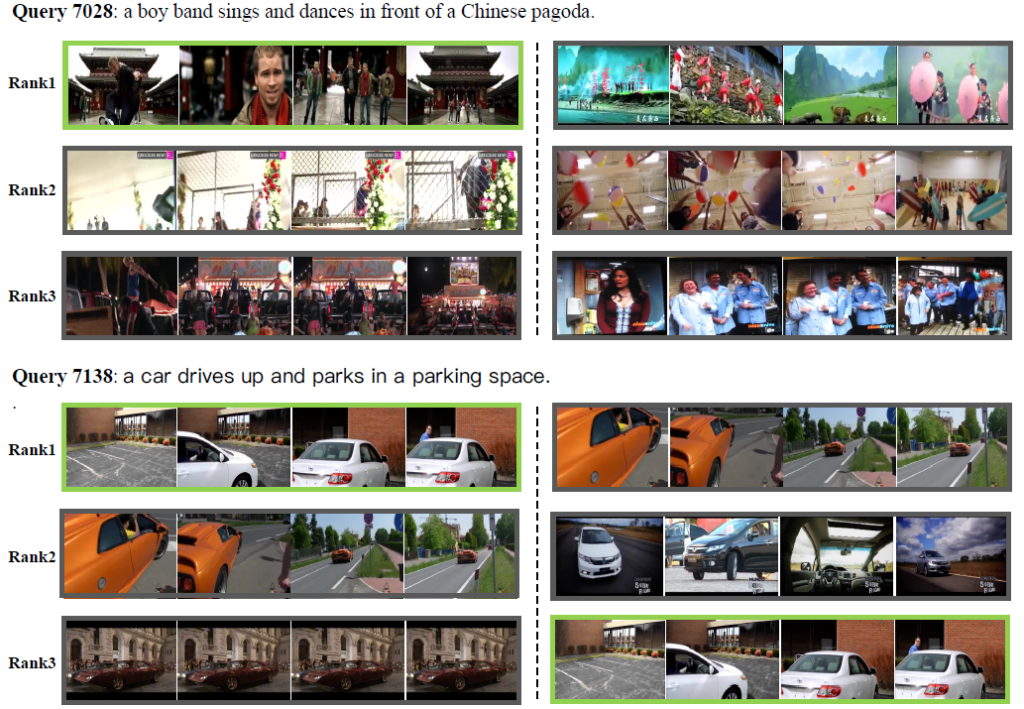
Fig 3과 4는 T2VLAD의 정성적 결과이며 전자는 Local alignment에 활용했던 weight를, 후자는 text-video similarity를 활용해 predict한 rank를 의미합니다.
3. Reference
[1] https://arxiv.org/pdf/2104.10054.pdf
semantic center 로 변환하는 과정이 궁금하네요. NetVLAD의 Soft assignment 과정과 같이 새로 네트워크에 태우는 것인가요?
넵. center에 align하는 과정은 NetVLAD의 그것과 동일하다고 합니다.