제가 이번에 리뷰할 논문도 depth estimation에 semantic segmentation을 이용하여 scene을 조금 더 잘 이해하기 위한 논문입니다.
우선 인간의 경우 depth를 추정할 때 geometric 단서와 semantic 정보를 이용합니다. ‘하늘’이라는 라벨에 대해서는 depth 값이 크다는 것을 인식하고 있는 것과 object의 경계에서는 depth가 크게 변한다는 것 등을 알고 있다는 것입니다. 따라서 depth 뿐만 아니라 segmentation 학습도 이뤄지는 SceneNet라는 네트워크를 제안합니다.
SceneNet은 encoder-decoder 기반의 네트워크로 encoder는 scene 이미지를 받아 representation으로 인코딩합니다. 그리고 decoder는 representation으로 부터 depth나 segmentation을 예측하는 classifier를 공유합니다. 따라서 SceneNet은 depth와 segmentation을 묶는 cross-modal 네트워크라 볼 수 있습니다.
기하학적이고 의미론적인 이해를 강화하기 위한 left-right semantic consistency와 semantic-guided disparity smoothness를 소개합니다. 두 self-supervised objective function을 이용해 semantic 예측을 통해 depth를 더 정확하게 예측할 수 있습니다.
다음은 이 논문의 contribution입니다.
Contribution
- left-right consistency를 이용하는 monocular depth estimation의 mismatch 문제를 지적함
- SceneNet은 기하학적, 의미론적 정보를 결합해 장면을 이해함.
제안된 모듈은 task 식별 (depth 혹은 segmentation), left-right의 의미론적 일관성, semantic-guided disparity smoothness를 유지함 - 스테레오 영상과 semantic 라벨이 지정된 이미지의 분리된 cross-modal 데이터셋에서 end-to-end로 학습함
- benchmark 데이터셋에서 정성적, 정량적으로 효과와 강인성 증명
Method
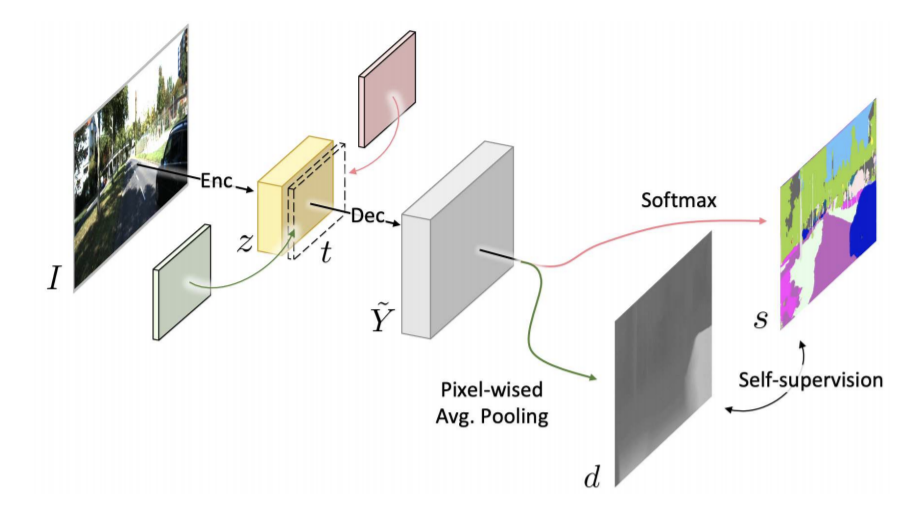
제안된 SceneNet의 목표는 monocular 이미지로부터 바로 depth map을 얻는 것이고 학습에는 stereo pairs와 RGB-segmentation pairs를 이용한다. 다른 모델들과는 다르게 두 데이터는 paired일 필요가 없다.
그림 1에서 볼 수 있듯 이미지 I를 입력으로 받아 scene represnetation z로 인코딩하고 이를 task 식별 계층 t와 함께 decode에 입력으로 넣어 cross-modal 예측 \tilde{Y}를 출력으로 얻는다. t에 따라 semantic segmentation 결과 s와 depth estimation 결과 d로 변환될 수 있고 이 두 출력은 대응하는 의미론적 정보에 기반해 정렬될 수 있다. SceneNet을 학습할 때 비지도 학습인 depth와 지도학습인 semantic segmentation을 위해 objective function을 적용한다. 두 self-supervised objective function(left-right semantic consistency와 semantic grounded disparity smoothness)를 이용해 cross-modal prediction을 조정한다. objective function에 대한 설명은 뒤에서 다루겠 습니다.
Task Identity for Cross-modal Prediction
disparity 예측과 semantic segmentation를 위해 task별 classification/regression 서브네트워크를 이용해 disparity map과 segmentation mask를 얻는다. 하지만 서로 다른 branch를 걸쳐 있는 sharing와 non-sharing layer의 하이퍼파라미터는 task 이동에 따라 조정과 결정을 해야한다. 이는 모델의 실용성을 제한하고 특히 다른 데이터셋의 적용을 어렵게 한다. 따라서 task 식별 t로 조건화된 통일된 decoder를 이용하여 cross-modal prediction을 병합한다. 논문에서는 t=1일 때 disparity, 0일 때 semantic segmentation으로 설정했다. cross-modal 예측 \tilde{Y}은 다음 식으로 구할 수 있다. 이때 δ는concatenation연산자이고 D는 마지막에 활성화 함수가 없는 cross-modal decoder 이다.
\tilde{Y}=D(δ(z,t))····(1)다음은 semantic segmentation s를 계산하는 식으로 \tilde{Y}_{s}=D(δ(z,t=1))이고 σ_{c}는 softmax 함수이다.
s=σ_{c}(\tilde{Y_{s}})····(2)다음은 disparity map 예측 d를 계산하는 식으로 \tilde{Y}_{d}=D(δ(z,t=0))이고 f_{µ}는 pixel-wise average pooling을 의미하고 σ_{d}는 sigmoid 함수이다.
d=σ_{d}(f_{µ}(\tilde{Y_{d})})····(3)통일된 decoder를 이용하므로 기하학적 정보와 의미론적 정보를 다른 모달리티를 통해 공유할 수 있으며 두 task에 긍정적으로 기여할 수 있다.
Depth Estimation &Semantic Segmentation
1. Unsupervised Depth Estimation
disparity map을 얻기 위해 학습에는 stereo 이미지 쌍인 I^{l}, I^{r}을 이용하고 inference 단계에는 monocular 이미지를 이용한다. 모델은 left 이미지인 I^{l}가 주어지면 disparity map d^{l}를 구하고 이는 right 이미지를 left로 재구성한 이미지 I^{r→l}를 만들 때 적용된다. 이미지 reconstruction loss L_{re}는 L1 loss를 사용하고 다음 식으로 계산할 수 있다.
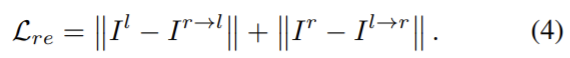
양쪽의 disparity를 일관성 있게 맞추고 smoothness를 유지하기 위해 monodepth1에서 제안된 loss를 이용해 depth를 학습하기 위한 loss는 다음 식으로 정리할 수 있다.
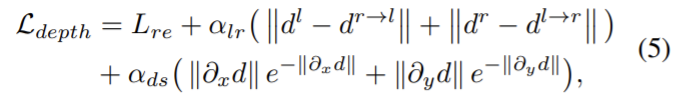
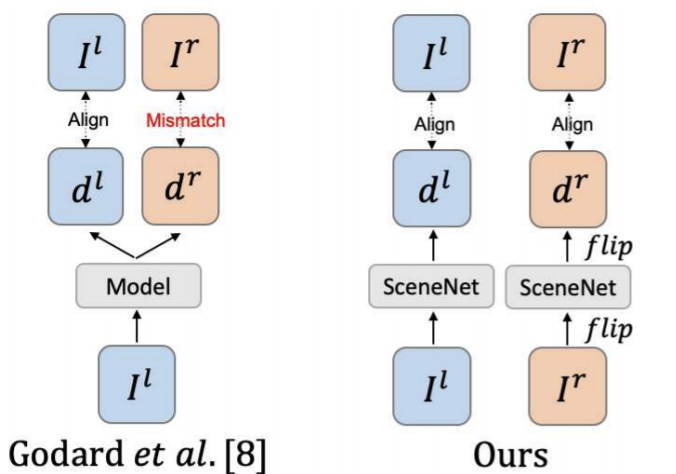
2. Mismatching Problem
contribution중 하나인 mismatching 문제는 left이미지로부터 생성된 right disparity mapd^{r}과 RGB 이미지 I^{r}의 구조적 alignment가 맞지 않다는 것이다. 이는 구조와 질감 정보가 없기 때문이다. 따라서 단일 이미지로부터 두 disparity map을 구하는 대신 input 이미지와 aligne이 맞는 하나의 disparity map만 사용하고 반대쪽의 disparity map을 얻기 위해서는 이미지를 수평으로 flip을 하여 얻었다.
3. Supervised Semantic Segmentation
depth estimation방법은 픽셀단위의 disparity 추정에 집중하며 이미지의 모든 픽셀이 공간적으로 동일하다고 여기고 이로인해 객체의 경계에서 부적절한 예측으로 이어진다. 따라서 semantic 정보를 이용하며, semantic segmentaation loss는 다음 식으로 정의되며 이때 ![]() 는 cross-entropy loss를 나타내고 s_{gt}는 gt 라벨을 의미한다.
는 cross-entropy loss를 나타내고 s_{gt}는 gt 라벨을 의미한다.
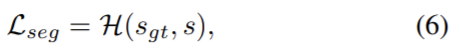
Self-supervised Learning of SceneNet
1. Left-Right Semantic Consistency
빛 반사 등의 이유로 왼쪽과 오른쪽 이미지 사이에 광학적으로 변화(차이)가 있을 수 있으므로 광학적 변화에 덜 민감한 semantic 레벨로 left-right consistency를 관찰하고 다음 식으로 정의할 수 있다.
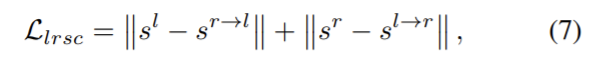
stereo 이미지였던 I^r, I^l에서 semantic segmentation s^r, s^l로 바꾸고 s^{r→l}은 d^l을 이용해 s^{r}을 와핑하여 얻을 수 있다.
2. Semantics-Guided Disparity Smoothness
마찬가지로 각 segmentation mask에서 disparity smoothness를 조정하고 다음 식으로 정의한다.
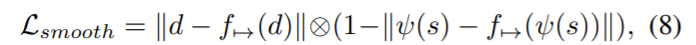
ψ는 각 채널에서 최대값을 1로 나머지를 0으로 설정하는 연산자이고 ⊗는 원소간의 곱을 나타내고 f_{→}는 수평 축을 따라 1픽셀 이동하는 연산자이다.
SceneNet의 전체 objective는 다음 식으로 정의할 수 있다.
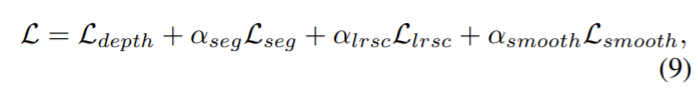
Experiments
KITTI 데이터셋의 stereo 이미지 쌍으로 학습하고 전체 어노테이션이 된 Cityscapes 데이터셋을 이용하여 semantic segmentation을 학습했다.
- Eigen Split: 선행 연구와 공정한 비교를 위해 동일한 세팅을 따라 22600 이미지를 학습에 쓰고 나머지는 test로 사용
- KITTI Split: monodepth1과 동일한 데이터 세팅. disparity map과 semantic segmentation 라벨 gt가 있어 depth와 segmentation에 사용
- Cityscapes Dataset: segmentation에 사용
DispNet을 수정한 encoder, decoder 쌍으로 구성하며 DRNs(dilated residual network)의 encoder 활용하여 더 나은 이미지 feature를 이해한다. 또한 decoder는 monodepth1에서 착안한 것으로 encoder로부터 4개의 skip connection을 이용해 예측 해상도를 강화한다.
추가적인 모델, 학습과 관련된 디테일은 논문을 참고해주세요.
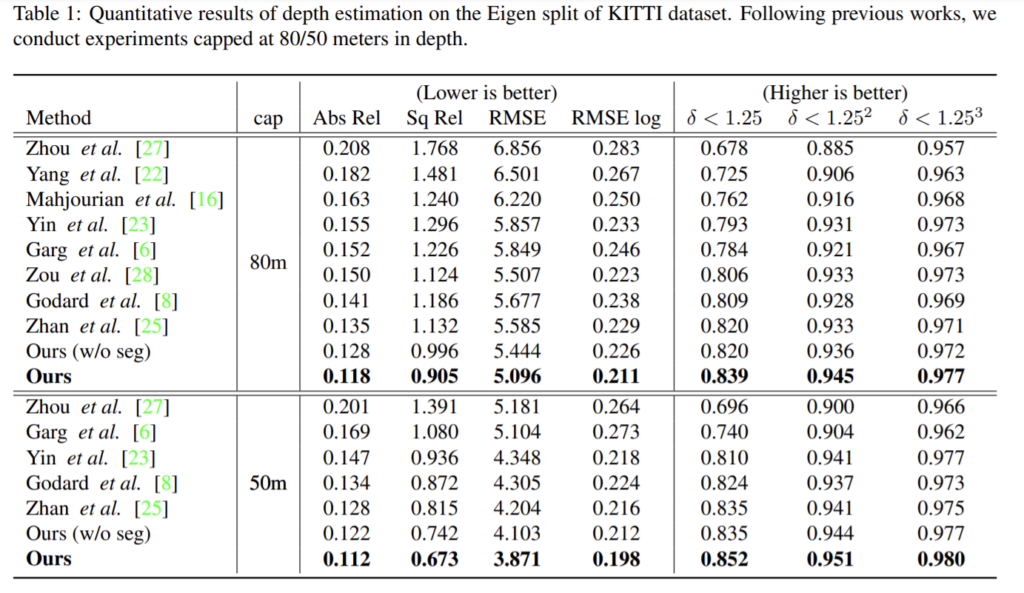
Eigen split에서 평가했고 해당 방법론이 가장 높은 성능을 달성했다.
Ablation Study
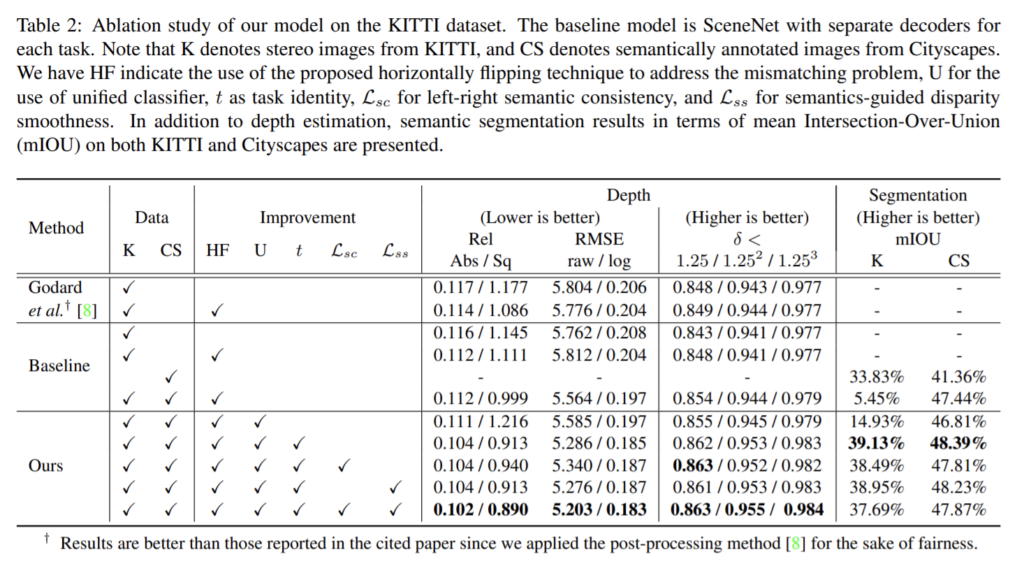
KITTI split에서 SceneNet의 semantic segmentation 평가했고 baseline은 encoder는 공유하고 decoder는 각각 사용하는 방식이다. mismatching은 horizontally flipping을 이용하므로 HF로 표시하고 [8]에 적용해 성능 비교를 해보았고 mismatching을 성공적으로 다룸을 확인했다. 또한 하나의 decoder를 사용하는 해당 논문의 모델과 각각의 decoder를 사용하는 baseline을 비교하여 동일한 decoder를 이용하는 것이 좋다는 것을 확인했다. 또한 loss의 각각에 대해서도 효과를 확인했다.

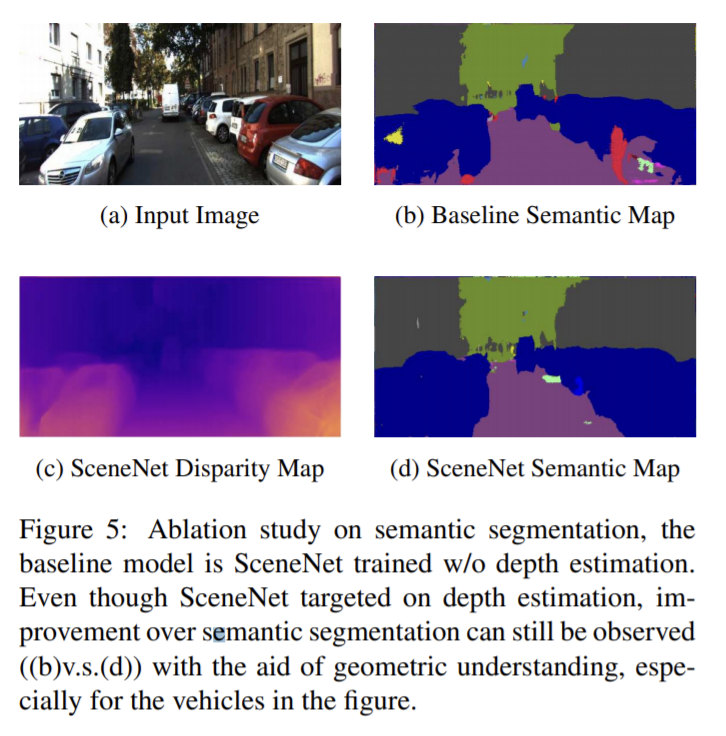
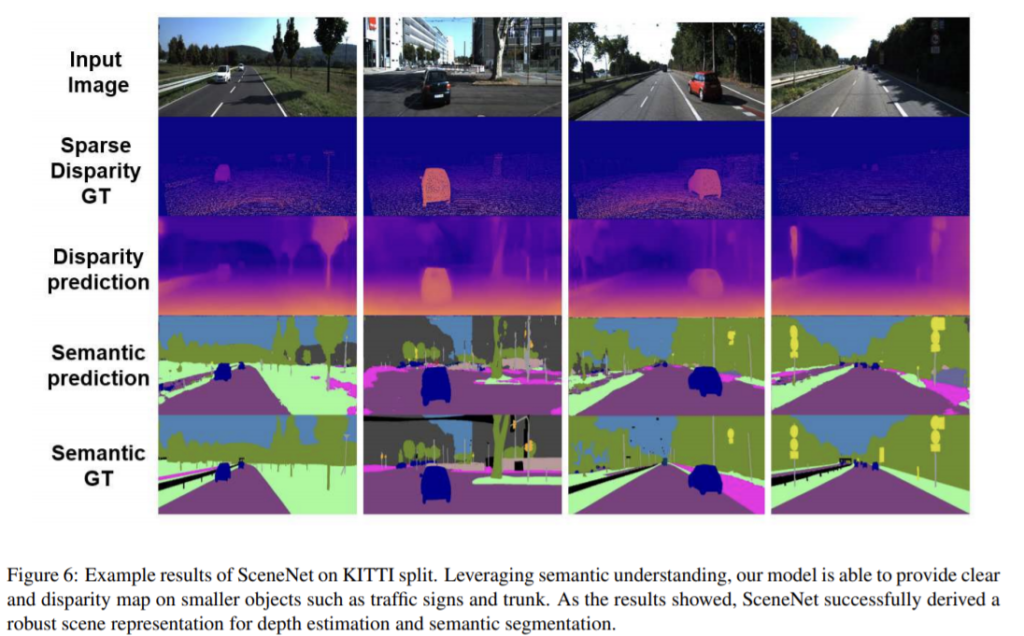
해당 논문은 mismatching문제를 해결하는 방법과 depth estimation과 semantic segmentation을 하나의 decoder를 이용하는 방법을 제안하며 장면의 의미론적 이해를 향상시켰음을 확인했다. 이 방법은 end-to-end로 학습된다.
해당 논문은 정리가 잘 된 논문인 것 같습니다. 기존의 방법론에서 문제라 생각한 mismatch부분에 대해 조금 더 실험적으로나 시각적으로 증거를 제시했다면 더 좋았을 것 같습니다.