해당 논문은 ICARA2021에 accepted paper “MonStereo: When Monocular and Stereo Meet at
the Tail of 3D Human Localization” 에 선행된 논문입니다. MonStereo에 대한 이해를 위해 리뷰를 작성합니다.
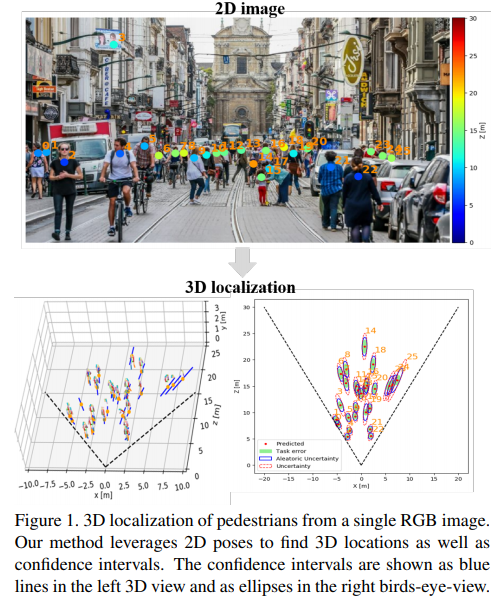
이번 리뷰는 단안 영상으로부터 검출된 보행자의 포즈 정보를 이용하여 위치를 추정하는 알고리즘에 대한 논문입니다. ICCV 2019에 다녀온 연구원들은 옆에 있는 논문이 낯에 익을 가능성이 높습니다. 당시에 포테닛/URP 과제로 보행자 검출에 관심이 큰 상황이었고, 3차원 공간의 보행자 위치 검출로 나온 논문은 해당 논문이 유일 했었습니다. 또한 보행자의 포즈 정보를 추론하여 거리 정보를 추정에 이용하는 컨셉도 포테닛/URP 과제에서 2d bbox를 검출과 동시에 depth regression을 사용한 방법과 유사해 보였기에 매우 인상 깊게 기억에 남은 방법론이었습니다.
++ 해당 방법론은 물체에 대한 d={x,y,z}, uncertainty를 추론하는 3D Localization입니다. 3D bbox를 예측하는 3D Object Detection과 다른 값을 예측하는 것이 목표입니다.
Intro
자율 주행에서 물체의 3차원 물체 검출은 매우 중요한 요소 중 하나입니다. 매우 높은 비용과 거리가 멀수록 point cloud가 희소해지는 단점에도 불구하고 LiDAR를 이용한 솔루션에 의존성이 큽니다. 이러한 이유로 상대적으로 비용이 값싸고 밀집한 point cloud를 생성할 수 있는 카메라 영상을 이용한 방법에 대한 연구가 많이 이뤄지고 있습니다. 단안 카메라를 이용한 예측을 할 경우, 깊이 정보에 대한 모호성이 발생하여 이를 스테레오 혹은 다중 카메라를 이용하여 제안되었습니다. 하지만 딥러닝의 발전을 단안 카메라에서도 깊이 정보를 추론할 수 있다는 가능성으로 인해 많은 연구가 제안되었습니다. 단편적인 예시로 Psuedo-Lidar 방법론이 있습니다.
수많은 3차원 물체 위치 연구로 이전보다 매우 높은 성능 향상을 가져왔습니다. 하지만 차량에 비해 보행자에서는 낮은 성능을 보여줍니다. 이러한 이유는 차량보다 보행자의 크기에 대한 분포가 매우 크기 때문입니다. 보행자마다 다양한 키와 모양을 가짐으로써 내부적인 모호성을 가져 모델이 예측하기 위한 충분한 분포를 학습하기 어렵습니다. 또한 충분한 분포를 학습하기 위한 데이터를 확보하기도 어려운 문제가 있습니다.
저자는 이러한 문제를 극복하고자 보행자의 포즈를 추론한 값을 입력으로 사용함으로써 내부적인 모호성을 극복하고, 예측값에 대한 불확실성을 예측함(fig 1, 하단 왼쪽 그래프의 파란색선, 오른쪽 그래프의 타원 )으로써 해당 태스크에 대한 더 많은 통찰력을 가지도록 합니다.
Localization Ambiguity
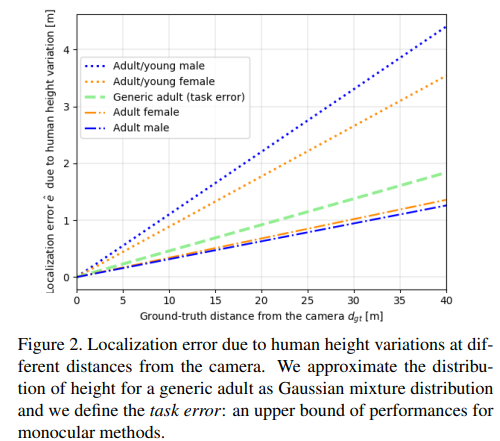
사실 단안 카메라에서 보행자의 위치 정보를 추론하는 것은 근본적으로 잘못된 문제에 해당합니다. 여기에 보행자의 키의 다양성은 문제를 더 어렵게 만듭니다. 만약 모든 보행자의 크기가 같다면 이런 모호성은 없을 것입니다. 저자는 이런 모호성의 한계를 정량화하고 최대 정확도에 대해 분석합니다. 즉, 모든 인간이 같은 크기 h를 가지고 있다는 전제하에서 저자는 task error라고 칭하는 오류를 분석 및 정의 합니다.
분석은 깊이 추정에서도 많이 사용하는 삼각형 닮음비를 이용하여 사람의 키와 카메라와 사람간 거리간 비를 이용합니다. 즉, d_{h-mean}/h_{mean} \equiv d_{gt}/h_{gt} 라고 가정하니다. d_{h-mean} 은 h_{mean} 라고 가정한 깊이에 해당합니다. 이러한 관계를 이용하여 task error는 아래와 같이 정의됩니다.
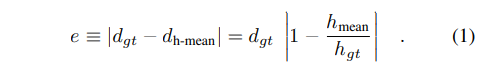
==========================================================================
++ 예측된 거리 값은 정확하게 측정된 거리와 보행자의 높이에서 상대적인 상대적인 focal length f’을 이용하여 아래의 수식을 통해 연속적으로 추론됩니다. f는 focal length에 해당합니다. Y는 real-world의 물체 height, y는 image-level에서의 물체 height에 해당합니다.
+++ 쉽게 풀어서 말하자면 저자는 단안 카메라에서의 물체의 위치 추정 한계를 정량화하기 위해 아래 수식의 모든 정보를 알고 있다는 전제에서 깊이 정보 Z를 추론합니다. 그 후, 수식 1을 적용하여 실제 GT와 차이를 측정합니다.
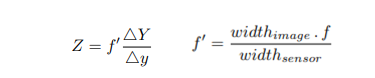
=========================================================================
저자는 63,000명의 유럽인을 기준으로 조사된 연구 정보를 토대로 남자는 평균 178cm, 표준편차 7cm, 여성은 평균 165cm, 표준편차 7cm를 가진 것으로 나옵니다. 남녀간 다른 분포를 가지지만 성별에 대한 정보를 사전 지식으로 주기에는 어려움이 있습니다. 그렇기에 남성과 여성의 모집단에 대한 분포가 가우스 분포를 따른다고 가정하여, 혼합 가우스 분포도 P(H)를 알려지지 않은 GT(높이 분포)로 사용한 경우, expected task error는 아래와 같이 정의 됩니다.
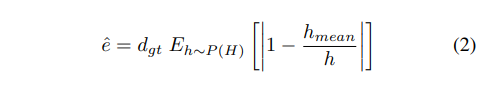
이는 내재적 모호성으로 인한 3D 보행자 위치 예측 오류 하한을 나타냅니다. Fig 2에서 다양한 케이스와 GT depth간 수식 2로 측정된 오류 관계를 확인 할 수 있습니다. (fig2에서 young은 14이하를 나타냅니다.)
즉, 태스크 자체의 한계로 내재적 모호성을 해결하지 않는 이상 모든 케이스에 강인한 위치 인식이 어렵다는 이야기입니다.
++ 설명이 더럽게 어려운데, 논문을 읽으면서 제가 이해한 저자가 전달하고자 하는 내용은 2가지로 보입니다.
1. 보행자의 다양한 형태로 일반화가 어렵다.
2. 모든 정보를 알고 있어도 태스크의 한계로 에러(task error)는 무조건 존재한다. 그러니깐 불확실성은 불가피한 요소이다.
Method
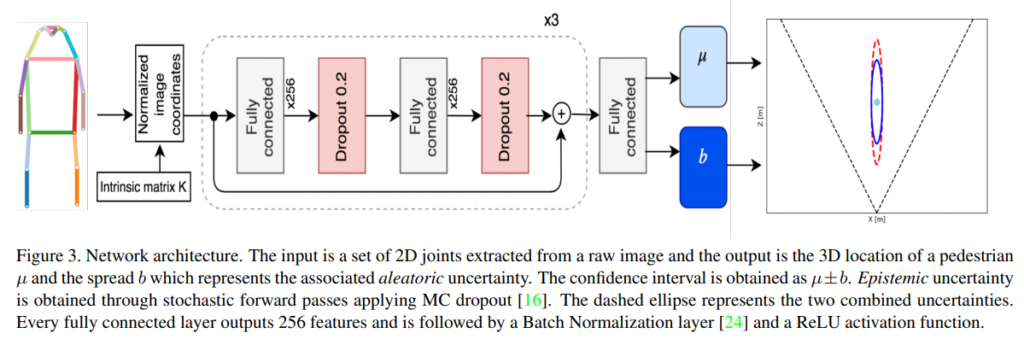
Fig 3에서 보이는 것처럼 방법은 비교적 간단합니다. 단, 저자가 주장하길 효율적인 3차원 보행자 위치 인식을 위해서는 정확한 추정 뿐만이 아니라 불확실성에 대한 현실적인 예측도 필요하다고 이야기합니다. 따라서 저자는 위치 정보를 지도 학습 정보로 사용하지 않고, 모호성을 학습합니다. 데이터로부터 점 추정을 예측하는 방식이 아닌 신뢰 구간을 예측하는 방법을 사용함으로써, 불확실성에 대해 예측합니다.
전체적인 파이프라인은 Fig 3과 같으며, 크게 두가지 단계로 구성됩니다. 하나는 pose estimation을 이용하여 pose 값을 입력 값으로 사용함으로써 이미지 도메인에서 벗어나고, 입력 정보의 차원을 줄입니다. pose estimation에서 추론된 pose 값은 보행자의 생김새, 스타일, 영상의 배경, 조도 변화에 불변하게 생성된 저차원의 정보로써 의미를 가집니다. 둘은 NN에 태워져 거리값과 불확실성을 예측합니다. 학습 단계에서는 모호성을 직접적을 학습하지 않고, 데이터로부터 암시적으로 분포를 학습합니다.
Setup
Input. 입력 정보로 pose estimation으로부터 얻은 영상내 생성된 pose들을 이용합니다. 데이터셋으로 촬영된 영상의 카메라 좌표에 오버피팅 되는 것을 방지하기위해 내부 카메라 행렬 값을 이용하여 정규화된 이미지 좌표로 좌표계를 옮겨 줍니다. 수식을 표현하자면 아래와 같습니다.
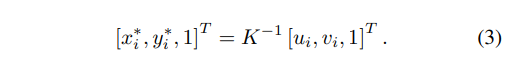
2D Human Poses. 사용된 Pose estimation 모델은 두가지 타입이 있습니다. 하나는 detection된 사람으로부터 포즈를 추정하는 bottom-up 방식에 해당하는 Mask-RCNN과 영상내 포함된 사람의 키포인트를 모두 추정하고, 키포인트간 상관관계를 분석하여 포즈를 추정하는 top-down 방식에 해당하는 PifPaf[S Kreiss et al. CVPR 2019]를 이용합니다. 두 모델 모두 pose keypoint GT가 존재하는 COCO에서 사전 학습을 한 모델을 사용합니다. 해당 논문에서 주로 평가한 KITTI와 nuScenes에서는 pose keypoint GT가 없기때문에 fine-tununing 없이 추론되어 사용되어집니다.
Output. 물체의 3차원 공간의 중심 [x, y, z]를 파라메타라이징하며, 영상에서의 물체 중심은 검출된 bbox(혹은 pose keypoint)의 중심 [u_c, v_c]에 해당한다고 가정합니다. 이런 가정하에서 3자유도에 2개의 구속 조건이 생김으로 3차원 공간 중심의 유클리안 거리 d를 추론하는 방법을 채택합니다. 즉, 거리가 같은 동일한 보행자가 영상 앞에 있든 가장자리에 있든 동일한 높이를 가진다고 가정합니다.
Base Network. Fig 3에서 표현된바와 같이, residual connections이 있는 256차원의 6층 FC와 BN, ReLU로 구성된 블록으로 구성되어 있습니다.
Uncertainty
앞서 이야기한대로 저자는 불확실성을 예측하는 것이 효율적인 보행자 위치 인식이라고 이야기 하였습니다. 불확실성을 다루기 위해 저자는 [A Kendall, 2017 arxiv]에서 제안된 Aleatoric Uncertainty과 Epistemic Uncertainty을 학습에 활용하는 방법을 사용합니다.
++
– Aleatoric Uncertainty는 데이터 자체의 불확실성에 해당합니다. depth와 segmentation을 예를 들면, 물체간 경계에서 발생하는 불확실성에 해당합니다. 즉, 데이터를 늘린다고 해결되지 않는 내재된 모호성에 해당합니다.
– Epistemic Uncertainty는 모델 예측에 대한 불확실성에 해당합니다. 파라미터의 최적화가 덜 되어 생기는 불확실성입니다. 이는 보다 많은 데이터를 이용하여 학습함으로써 해결이 가능한 불확실성에 해당합니다.
Aleatoric Uncertainty는 모델의 예측 값 {평균과 분산}을 GT에 대한 확률 분포(Laplacian Probability distribution)를 최적화함으로써 가져갑니다. Epistemic Uncertainty은 MC dropout을 적용함으로써 파라미터의 분산의 최적화를 앞당깁니다. 어려워 보이지만 결론은 익숙한 아래의 수식 형태를 따릅니다.
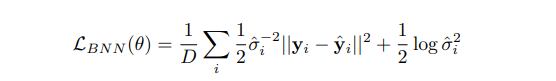
위 수식의 1항 중 L2항은 Epistemic Uncertainty에 해당하는 항으로 모델의 예측값과 GT의 차이를 줄이는 역할을 합니다. 1항의 나머지 요소 중 시그마는 Aleatoric Uncertainty가 큰 예측 값에 대해서는 residual을 적게 반영하도록 하는 역할을 합니다. L2 regularization에 해당하는 2항은 Aleatoric Uncertainty가 모든 데이터에서 대해 무한히 커지는 상황에 대해 제약을 하는 역할을 합니다. ++ 그리고 MC dropout은 우리가 아는 dropout에 test에도 dropout을 적용한다고 생각하시면 됩니다.
최종적으로 생성되는 예측값은 평균값을 u를 이용합니다.
Experiments
Datasets. KITTI와 nuScene을 이용하여 분석하였으며, nuScene인 경우, 논문이 나온 당시에 teaser만 공개된 상태라 일부만 사용하여 평가하였다고 하니다.
Evaluation.
– Average Localization Error(ALE).
– Average Localization Precision (ALP) ~ 오차가 일정 임계값보다 낮은 경우, true로 판단
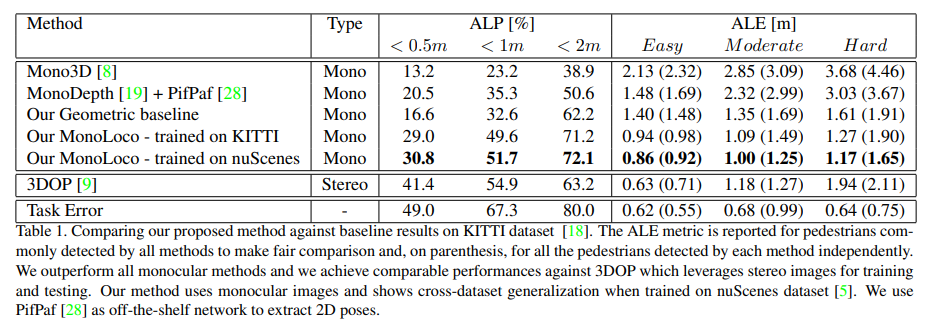
3차원 물체 검출 알고리즘에 해당하는 Mono3D의 결과값을 자신들의 task에 맞게 변형하여 평가를 하였다. 2016년 방법론과 비교하여 아이러니한 부분이 있긴하다(해당 논문이 나올 당시에 3D Object detection 방법론이 별로 없었는지 확인이 필요해 보임)… 어찌하였든 성능을 2배 이상 향상 시킨 모습을 보여준다.
++ Geometric baseline은 pose keypoint의 엉덩이와 어깨 정보를 토대로 신체 기하학적 정보를 이용하여 거리를 예측한 방법이다.
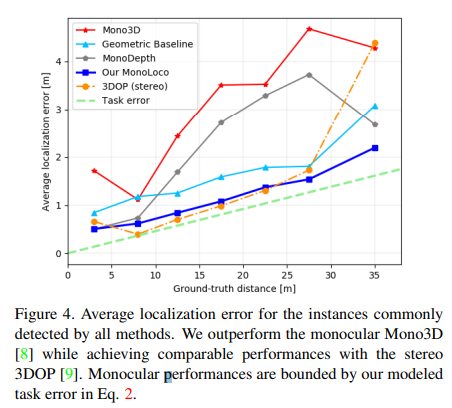
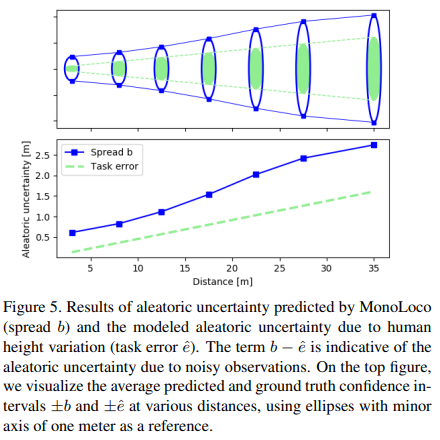
Fig 5를 통해 aleatoric uncertainty(task error)와 예측 b를 비교 합니다. 이를 통해 모델이 깊이만 예측하는 것이 아닌 불확실성도 함께 예측한 것을 볼 수 있습니다.
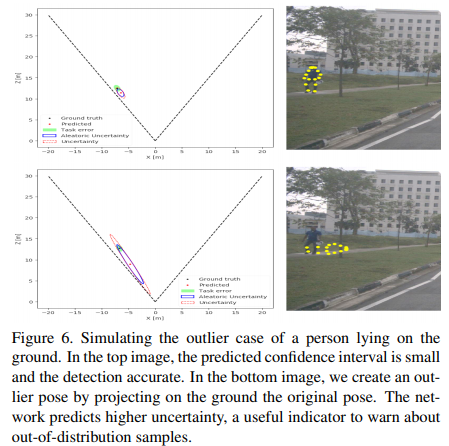
또한 Fig 6을 통해 잘못된 pose가 입력될 경우 왼쪽의 그림에서 불확실성을 뜻하는 타원이 명확하게 커짐을 확인 할 수 습니다.
============================================================================
사실 해당 논문을 처음 읽었을 때, pose 정보와 보행자의 키정보를 분석한 정보를 토대로 깊이 예측에 도움을 주는 방법론으로 생각하였다. 하지만 막상 읽어보니… 포즈 정보를 인풋으로 사용하여 만든 예측 값과 GT를 L2 loss와 L2 regularization을 사용하는 방법이다… 그런데 해당 논문이 ICCV에 붙인 이유는 수학적인 증명과 다른 논문의 실험적 증명을 정말 잘하였고 셀링을 정말 잘한 논문에 해당한다고 생각이 든다.