제가 이번에 리뷰할 논문은 segmentation을 depth에 이용하는 또 다른 논문입니다.
이미지를 object instance와 background stuff class로 분해한 뒤 각 부분에 대해 크기와 shift canonical depth map을 예측한다. 이때 canonical depth란 [0,1]의 갓으로 정규화된 depth map을 의미하고, 동일한 클래스는 같은 decoder를 공유한다. 이를 통해 전역에 대한 깊이 추정 task를 단순화하여 학습하고 새로운 장면에 일반화하기 쉬운 카테고리별 예측 task로 분해한다. 이후 각 depth segment를 입력 이미지로부터 얻은 global context 정보를 이용하여 모은다. 이 방법은 파라노마적 segmentation과 깊이 추정을 위한 multi-task loss를 이용하여 end-to-end로 학습할 수 있다.
Semantic Divide-and-Conquer Network for Monocular Depth Estimation
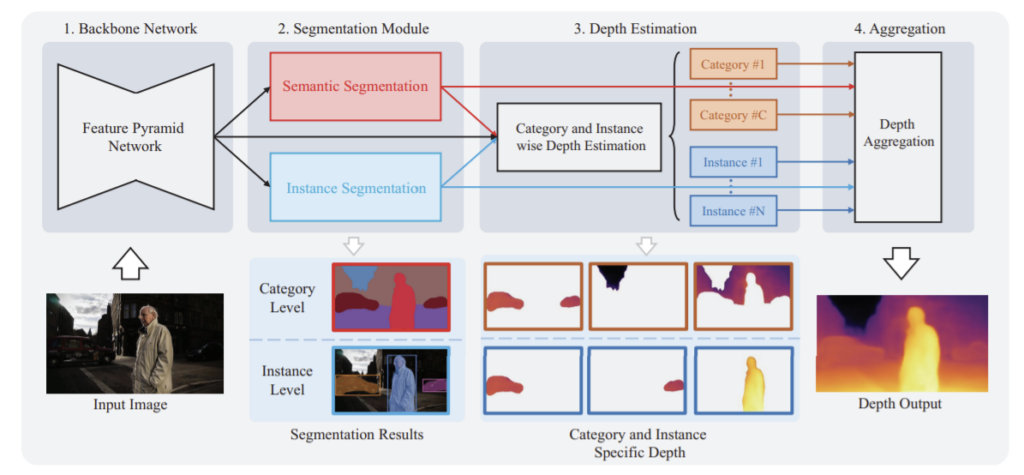
SDC-Depth 네트워크는 end-to-end로 학습할 수 있는 깊이 추정 방식으로 4개의 모듈로 이루어져 있다. 이미지의 특징을 추출하고 segmentation과 depth estimation 모듈이 공유하는 backbone, semantic과 instance segmentation이 이뤄지는 segmentation 모듈, 각 semantic segment마다 canonical 공간에서의 카테고리별 depth map과 크기, shift 파라미터를 추정하는 depth estimation 모듈, 각 부분들의 depth map을 모으는 aggregation 모듈이 있다.
backbone은 feature pyramid net(FPN), semantic segmentation은 fully convolutional net(FCN), instance segmentation은 Mask R-CNN을 이용한다. 이때 전체 C클래스 중 K개는 object에 속하고 나머지는 stuff클래스에 속하며 instance는 K개의 클래스에 대해 이뤄진다.
Per-Segment Depth Estimation
semantic segment에 대해 깊이 추정 모듈은 segment-중심의 canonical depth map과 global depth로 바꾸기 위한 transformation을 예측한다. 그리고 semantic과 instance 부분이 있는데 semantic은 카테고리 레벨로 그 카테고리에 해당하는 전체에 대한 depth를 예측하고 object 클래스에 대해 장면에서의 위치에 따라 depth가 달라지므로 instance별로 depth map을 더 좋은 depth map을 예측할 수 있다.
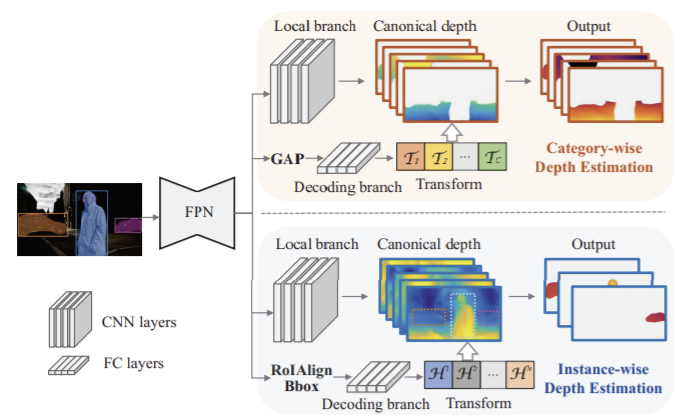
1. Category-wise Depth Estimation
2개의 branch 구조를 이용해 canonical depth와 global transformation을 예측함. 그림2에서 볼 수 있듯 local branch는 convolution 레이어로 구성되고 각 segment별로 canonical depth를 예측한다. 이때 시그모이드 함수를 이용한다. global depth decoding branch는 Global Average Pooling 레이어를 포함하는 fully connected 레이어로 구성되어 있고, 입력 feature의 전역 context를 특징짓는 벡터와 매핑되며 c-th 카테고리의 global transformation인 를 ![]() 정하는데 사용된다.
정하는데 사용된다.
![]()
![]()
![]()
2. Instance-wise Depth Estimation
기존의 ROI Align 방식은 해상도가 낮아 정확한 예측이 어렵다는 문제가 있었고 이를 해결하기 위해 fully convolutional local branch와 instance depth decoding branch로 구성된 구조를 제안한다. local branch를 통해 category-agnostic depth map ![]() (HxWxZ크기, Z는 이 실험에서는 32로 설정됨)을 예측하고 i번째 instance의 bounding box에 대해
(HxWxZ크기, Z는 이 실험에서는 32로 설정됨)을 예측하고 i번째 instance의 bounding box에 대해 ![]() 가 크롭된
가 크롭된 ![]() (Hi와Wi는 bounding box의 공간 정보를 의미)를 예측한다. i번째 instance의 depth를 예측하기 위해 depth decoding branch는 ROIAlign로 얻은 feature를 입력으로 하여 일정한 특징 백터를 추출해 linear depth decoding 함수
(Hi와Wi는 bounding box의 공간 정보를 의미)를 예측한다. i번째 instance의 depth를 예측하기 위해 depth decoding branch는 ROIAlign로 얻은 feature를 입력으로 하여 일정한 특징 백터를 추출해 linear depth decoding 함수 ![]() 를 예측한다. (Gi는 affine transformation, Ci는 Z채널의 instance depth map을 선형으로 결합하기 위한 1×1 convolutional 레이어) depth decoding branch에서 각 카테고리별로 함수가 만들어져 canonical depth의 크기와 이동을 조정할 수 있다.
를 예측한다. (Gi는 affine transformation, Ci는 Z채널의 instance depth map을 선형으로 결합하기 위한 1×1 convolutional 레이어) depth decoding branch에서 각 카테고리별로 함수가 만들어져 canonical depth의 크기와 이동을 조정할 수 있다.
Segmentation Guided Depth Aggregation
카테고리 depth map { Dc ∈RH×W |c = 1, . . . , C }과 object instance depth map { Fi ∈ RHi×Wi | i = 1, 2, . . . , N }을 이용해 최종 depth 추정을 만든다. aggregation모듈은 2단계로 이루어져있다.
첫번째 단계는 각 instance가 해당하는 category depth map을 지역적으로 update한다. 그다음 카테고리 depth map Dc를 1로 초기화 한 정규화 마스크 Mc와 연관시킨다. 이 마스크는 각 인스턴스 depth map의 업데이트를 기록하기 위해 사용되곡 각 최종 depth map을 정규화한다. depth map과 정규화 마스크는 다음 방식으로 지역적으로 업데이트된다.
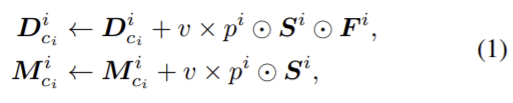
v는 instance depth map의 균형을 위한 하이퍼파라미터로 (이 논문에서는 10으로 설정됨) ⊙는 원소별 곱셈, pi는 i번째 인스턴스가 ci카테고리에 해당할 확률이다. Si는i번째 인스턴스의 Hi × Wi의 upsamped segmentation mask를 나타낸다. pi와 Si는 instance segmentation 모듈에서 생성된다.
모든 인스턴스의 영역이 업데이트되면 카테고리 depth map Dc는 다음식으로 계산된다.


두번째 단계는 semantic segmentation에 해당하는 카테고리 depth map Dc를 전부 업데이트한다.
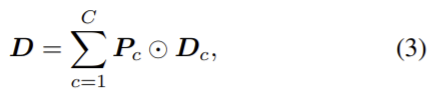
D는 최종 depth map을 의미하고 Pc는 클래스당,픽셀당 semantic segmentation 모듈의 c 클레스에서의 (x,y)위치에 대한 segmentation 결과다.
Network Traning
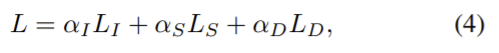
LI는 instance segmentation loss, LS는 semantic segmentation losses, LD은 depth prediction lossdlek. L1 loss를 사용하고 DIW dataset에서 제안된 ranking loss를 사용한다. 자세한 설명은 supplementary material을 참고하라 되어있는데 없었다…
Experements
사전학습된 ResNet-50을 이용하였고 random flipping, scaling, color jitter를 데이터 augmentation에 이용하였다. 마찬가지로 더 자세한 건 supplementary material을 참고하라고 되어있는데 없었다.
- Cityscapes 결과
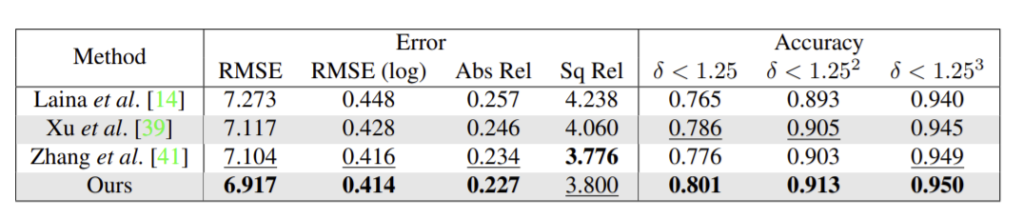

성능이 대체로 좋고, 기존의 두 방법과 비교했을 때 error map을 보면 좋은 결과를 확인할 수 있다.
supplementary material을 참고하라 되어있는데 찾을 수가 없어서 당황스러웠습니다…..depth방법론에 semantic과 instance segmentation을 모두 사용하면 단순한 방법은 아닌 것 같습니다.
본 논문의 제목에 Divide and Conquer Network라고 표기한 이유는 무엇인가요?
뭔가 리뷰를 읽었을 때는 분할 정복에 대한 컨셉이 드러나 있지 않는 것 같아서 질문드립니다.
또한 당시의 방법론과는 다른 본 논문의 Contribution은 무엇인가요?
Depth Estimation쪽 동향은 잘 몰라서 질문드립니다!
우선 논문은 object class와 background class로 분류하여 instance segmentation과 semantic segmentation을 따로 진행하며 각각의 class에 대해 depth를 예측합니다. 이렇게 각각 구한 depth를 합쳐 하나의 depth output을 만들기 때문에 semantic divide and conquer Network라 표현한 것입니다. Segmentation Guided Depth Aggregation에 소개된 방식이 conquer에 대한 설명입니다.
본 논문의 Contribution이 명시되어있지 않지만 정리해보면 카테고리별로 분류해 depth를 예측하기 때문에 새로운 장면에 일반화하기 쉽다는 것과 multi-task loss를 이용해 end-to-end로 학습할 수 있다는 것입니다. 기존에 방법들(depth + segmentation)은 이미지를 가지고 한번에 depth를 예측하였는데 이 논문의 경우 segmentation으로 카테고리를 분류한 뒤 각각에 해당하는 depth를 예측한다는 점에서 차별성을 띄는 것으로 이해하였습니다.