최근 Anomaly Detection에서 MLPD의 확장연구로 연구 방향을 전환하며, Domain Adaptation 에 대해 알아보기 위해 읽어본 논문입니다. 참고로 최근에 김지원 연구원이 리뷰한 논문의 기반이 되는 논문이라고 할 수 있습니다. 따라서 이 리뷰를 읽고, 김지원 연구원의 리뷰를 통해 어떻게 MLPD에 적용이 되는지 읽어보시는 것을 추천드립니다!
Background
이번에도 논문의 이해를 돕기 위해 사전에 알면 좋을 내용을 정리하고 넘어가보고자 합니다. 많은 분들이 아시겠지만 Advervarial 가 계속 논문에서 언급되기에 찾아보았는데, 그 중 Adversarial learning 에 대해 잘 정리해준 블로그가 있어 첨부하니 읽어보시면 좋을 것 같습니다.
그렇다면 Domain Apataion 이란 무엇일까요? Train(source) 와 Test(target) 분포 간 차이가 있을 때 사용되는 Task입니다. 예를 들어, Train은 낮에 찍힌 사진이고 Test는 야간에 찍힌 사진일 때, 데이터 분포 간 차이가 있는데, 이 격차를 줄여주는 방법이 Domain Adaptation이라고 합니다.
Adversarial Discriminative Domain Adaptation – [ 논문 바로가기 ]

Introduction
기존 Deep Convolutional Network는 대규모 데이터셋을 이용하여 학습하지만, Dataset bias 혹은 Domain shift이라고 알려져 있는 현상으로 인해 일반화가 어렵고 새로운 데이터에 대한 성능 저하가 발생하곤 합니다. 따라서 Domain Adaptation (DA)이라는 방법론은 Domain shift 이슈를 완화시키고자 제안되었으며, 최근 DA 방법론으로는 source와 target 도메인을 공통 feature space으로 매핑하거나 source에서 target 도메인으로 reconstruct 방법을 사용하곤 합니다.
Adversarial Adaptation은 Domain 간 차이를 좁히고자 하는 방법에서 제안된 방법으로, GAN 밀접하다고 할 수 있습니다. GAN에서의 Generator는 real image와 비슷한 이미지를 생성하도록 학습되고, Discriminator는 생성 이미지와 real 이미지를 구분하도록 학습됩니다. Domain Adaptation에서는 train과 test 도메인을 서로 구분할 수 없도록 학습됩니다. 따라서 본 논문에서는 adversarial learning과 discriminative feature learning 을 결합한 Unsupervised Domain Adaptation 방법론인 Adversarial Discriminative Domain Adaptation을 제안합니다. 다시 말해, 인코딩된 target 이미지를 Source와 구별하려는 Domain Discriminative를 속이며, target 이미지를 Source Feature 공간으로 mapping하는 방법을 학습합니다.
Method

ADDA의 프레임 워크는 위 그림과 같이 총 세 단계로 구성됩니다.
- Pre-training : Source Dataset으로 Source CNN을 학습시킵니다.
- Adversarial Adaptation : 이미 학습이 완료된 Source CNN과 Target CNN을 학습하는데, GAN에서의 Generator가 Discriminator를 속일 수 있는 Fake Image를 생성해내듯, target mapping을 source domain에서 왔다고 생각하도록 속이도록 Target CNN을 학습시킵니다. 단, Discriminator는 어느 CNN의 결과인지 잘 구별하도록 학습됩니다.
- Testing : 마지막으로 target 이미지를 target CNN에 통과시킨 feature map을 source 이미지로 pre-training 된 classifier에 넣어 label을 분류합니다.
[1] Pre-training
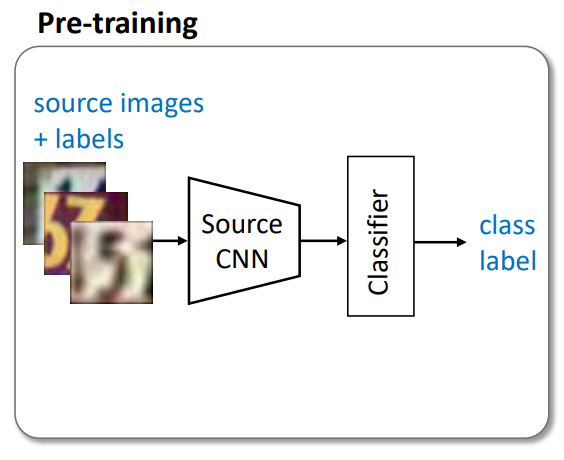
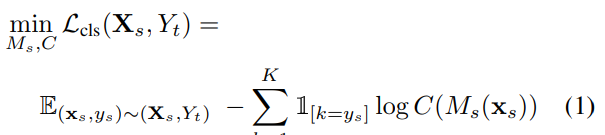
Unsupervised adaptation에서의 목표는 Target에 대한 Domain Annotation이 없더라도, Target을 정확하게 분류할 수 있도록 Target 표현인 M_t와 분류기 C_t를 학습하는 것입니다. 이 때 Annotation의 부재로 인해 Target에 대한 supervised 학습이 불가능하므로, Domain Adaptation에서는 source 표현인 M_s와 source 분류기인 C_s를 학습한 다음, Target Domain에서 사용할 수 있도록 모델을 조정하는 방법을 학습합니다.
Adversarial Adaptation에서의 주요 목표는 source와 target 간 매핑 함수를 정규화하는 것입니다. 이럴 경우, source의 분류기를 target에 직접 적용할 수 있으므로 target에 대한 분류기를 별도로 학습할 필요 없이 C = C_s = C_t 라고 설정할 수 있습니다.
따라서 source classification 모델은 아래 보이는 loss처럼 기존에 흔히 사용하던 supervised loss를 사용하여 학습을 진행합니다. 즉, loss function 역시 source mapping이 label을 잘 분류할수록 낮아지도록 설정되었습니다.
[2] Adversarial Adaptation
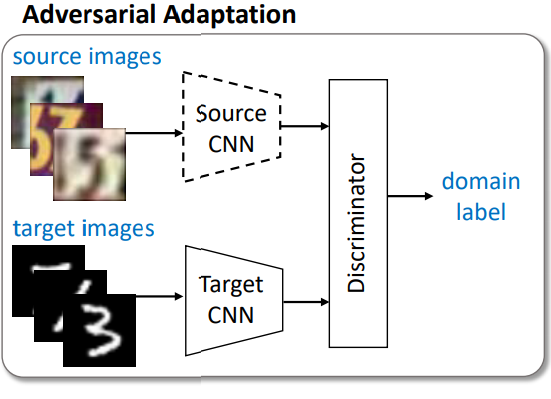
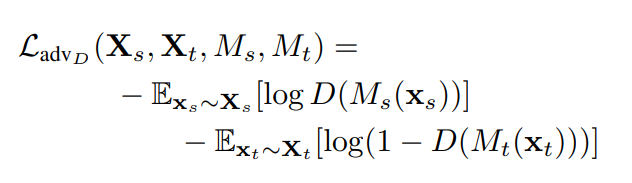
그림에서의 점선은 학습하지 않는다는 것을 의미합니다. 즉, Source CNN은 pre-trained 된 것을 그대로 사용합니다. 2번째 단계에서는 source 이미지를 source CNN에 통과시킨 feature map과, target CNN에 통과시킨 feature map을 discriminator가 구별합니다. 당연히 Target CNN은 Discriminator가 source의 feature map인지 Target의 feature map인지 구별하지 못하도록 학습이 되며 이를 위해 Loss 함수는 다음과 같이 설계됩니다.
Adversarial loss : Source mapping(M_s)과 Target mapping(M_t)은 L_{{adv}_M}을 최소화합니다. 다만 이 loss function 에서는 log D(M_t(x_t)), target mapping에 대해서만 adversarial한 목적식을 가진다고 합니다. D(M_t(x_t))=1이 되는 것이 목표로, Discriminator가 target mapping을 source domain에서 왔다고 생각하도록 속이는 것을 목표로 합니다.
[3] Testing
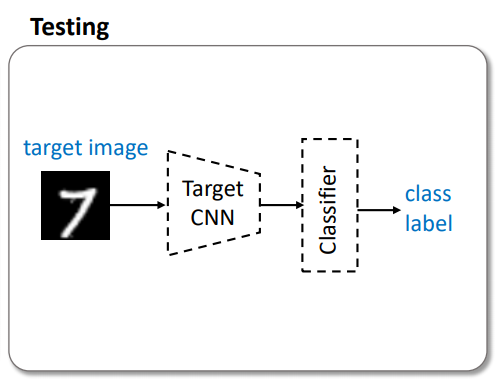
앞서 언급했 듯, 점선은 학습하지 않고 파라미터가 Fixed 된 것입니다. 따라서 loss 함수는 필요하지 않습니다. 앞서 [2] 단계를 통해 target CNN은 source domain에 가장 비슷한 feature map을 출력하도록 학습되었습니다. 이 Target CNN에 target image를 넣고 [1] 단계에서 학습된 Classifier 에 넣고 나온 label 을 통해 unsupervised adversarial domain adaptation이 수행됩니다.
Experiment
ADDA의 Domain Adaptation 성능을 보이기 위해 크게 3가지에 대한 실험 결과를 보여줍니다. 먼저 숫자 이미지이면서 난이도는 다양한 MNIST, USPS, 그리고 SVHN에 대한 성능을 보입니다. 그리고 여러 modalities에 걸친 연구를 위한 NYU Depth 데이터셋을 이용한 실험을 진행하였습니다. 마지막으로 표준 Office 데이터셋을 이용하여 이전 연구들과의 성능을 비교합니다. 아래 이미지는 해당 실험 데이터셋에 대한 sample 이미지입니다.

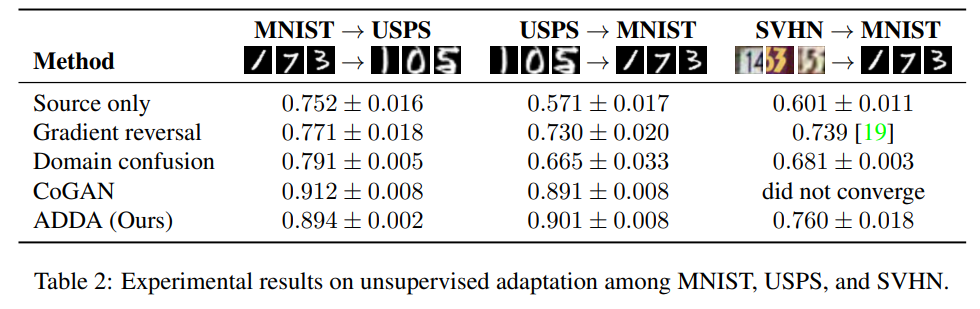
먼저 unsupervised adaptation에서의 성능을 평가하기 위해 digits datasets 인 MNIST, USPS, 그리고 SVHN 데이터를 사용하여 실험을 진행합니다. 모든 실험은 unsupervised 한 환경에서 수행되며, target label은 사용되지 않으며 진행된 실험은 다음과 같습니다.
Target -> Source
(1) MNIST -> USPS
(2) USPS -> MNIST
(3) SVHN -> MNIST
실험 결과는 아래에 있는 Table 2에서 확인할 수 있습니다. MNIST와 USPS의 경우 shift가 쉬워질수록 CoGAN보다 좋은 성능을 냈다고 합니다. 게다가 꽤 어려운 shift인 SVHN -> MNIST 실험 결과는 다른 방법론들에 비해 좋은 결과를 보인다고 합니다. 게다가 당시 최신 방법론인 CoGAN의 경우 도메인이 너무 분산되어 있어 coupled generator를 학습시킬 수 없어 수렴하지 않은 결과를 보였다는 것을 통해 충분히 설득력 있는 결과를 보였다고 합니다.
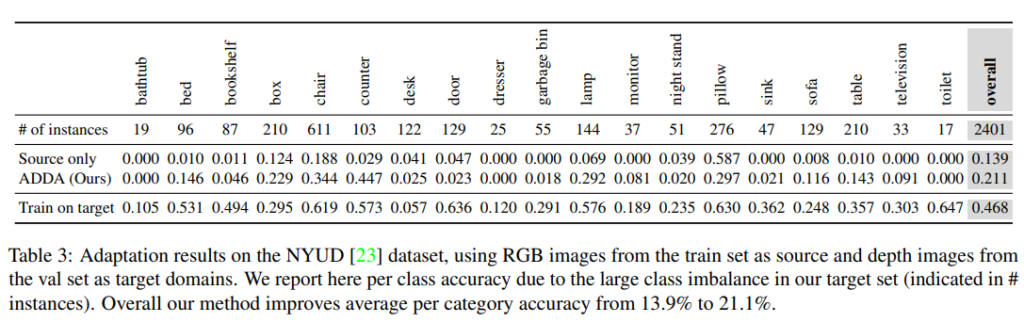
2번째 실험을 통해 Modality Adaptation 성능을 보입니다. 실내 장면으로 19개 class에 대한 bounding box annotation을 포함하는 NYU depth 데이터셋을 사용하는데, classification task 이기 때문에 bounding box를 crop 하여 사용하였습니다. 이 때, RGB를 소스 도메인으로 사용하고, depth 를 target 도메인으로 사용하였습니다.
분류 성능의 경우 source 단독으로 학습한 것보다는 성능이 낮았다고 합니다. 그 이유는 bounding box로 crop 하였기 때문에 해상도가 상대적으로 낮아 평가 시 정확한 분류가 어려운데다 특정 클래스의 example이 거의 없던 것도 원인이었다고 합니다. 다만 ADDA가 counter 같이 특정 클래스의 분류 정확도를 source only에 비해 20배 이상 향상시킨 것을 확인할 수 있었습니다.
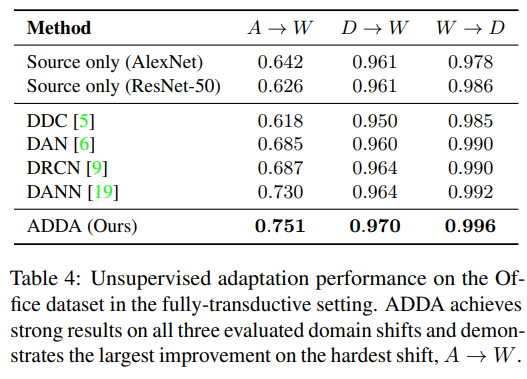
마지막으로 benchmark Office visual domain adaptation 데이터셋에 대한 성능 평가입니다. Adaptation은 amazon(A) 에서 웹캡(W) 으로, DSLR (D) 에서 웹캠(W)으로, 웹캠(W) 에서 DSLR(D)로 전환되며 각 실험 성능은 아래 표와 같습니다. 가장 어려운 A -> W가 크게 증가한 것을 통해 실제 adapation의 성능이 효과적이며 기존 방법론들에 비해 SOTA임을 검증하였습니다.
Conclusion
본 논문을 통해 Adversarial Learning 기반의 Unsupervised Domain Adaptation 방법론을 제안하였으며, 최근 제안된 방법론 사이의 유사한 점과 차이점을 이해할 수 있는 관점을 확인할 수 있습니다. 각각의 접근 방식에서 얻을 수 잇는 이점과 핵심 아이디어를 이해함으로써 각 방법을 ADDA로 결합할 수 있었으며, 해당 방법론이 잘 일반화되어 좋은 성능을 낼 수 있었다고 합니다.
Domain Adaptation에 대해 처음 접해보는 논문으로 어려움이 많았던 것 같습니다. 여러 수식이 등장하는데, 이에 대한 디테일한 설명을 놓쳐 리뷰가 조금 가벼운 것 같습니다. 앞으로 Domain Adaptation에 대해 깊이있게 알아보기 위해서는 재정비가 필요할 것 같아 아쉬움이 있네요. 다음에는 더 심도있고 전문성 있는 리뷰를 작성해보도록 노력하겠습니다.
좋은 리뷰 감사합니다!
Source CNN은 classification을 위한 네트워크라고 생각하면 될까요?
source와 target 간 매핑 함수를 정규화하는 것이 목표라 되어있는 데 target 이미지를 source 이미지로 매핑 시키는 것이 아니라
target CNN은 Source CNN을 통과한 Feature와 유사한 Feature를 만들어 discriminator를 이용해 유사한 Feature를 만들도록 학습하고 Test에는 target CNN을 통과시킨 feature를 이용해 분류를 진행하는 것이 맞나요?
댓글 감사합니다 🙂
말씀하신대로 Source CNN은 Claasification을 위한 네트워크가 맞습니다.
그리고 두번째 질문이 제가 리뷰한 논문의 main idea로 제대로 이해해주신 것 같습니다 :>