
Youtube : https://youtu.be/O6GQGia4VdE

올해 들어 transformer 구조가 기존 Computer vision을 장악했던 CNN 구조를 대체하기 시작하면서, CNN 구조를 지닌 모델들에 적용했던 방법들 또한 transformer 구조 방법론에 적용되고 있습니다. 그 중 transformer 구조 방법론 또한 실생활에 결국은 응용되어야하기에 CNN 구조에서처럼 모델의 가속화가 필요했고 이를 해결하고자 한 논문이 오늘 리뷰할 DynamicViT 입니다.
1. Method
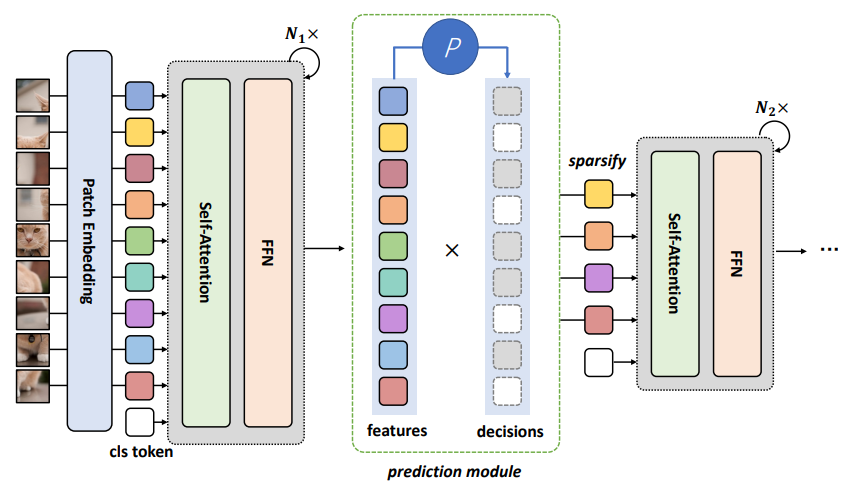
1.1 Overview
본 논문에서 제안하는 DynamicViT는 Fig 2와 같은 framework를 지니며, 일반적인 vision transformer 구조인 backbone network와 몇 개의 prediction module로 구성됩니다. 새롭게 제안된 prediction module은 특정 token의 drop or keep 는 여부를 결정하는 token sparsification을 계층적으로 반복하여 attention masking 전략을 사용합니다.
1.2 Hierarchical Token Sparsification with Prediction Modules
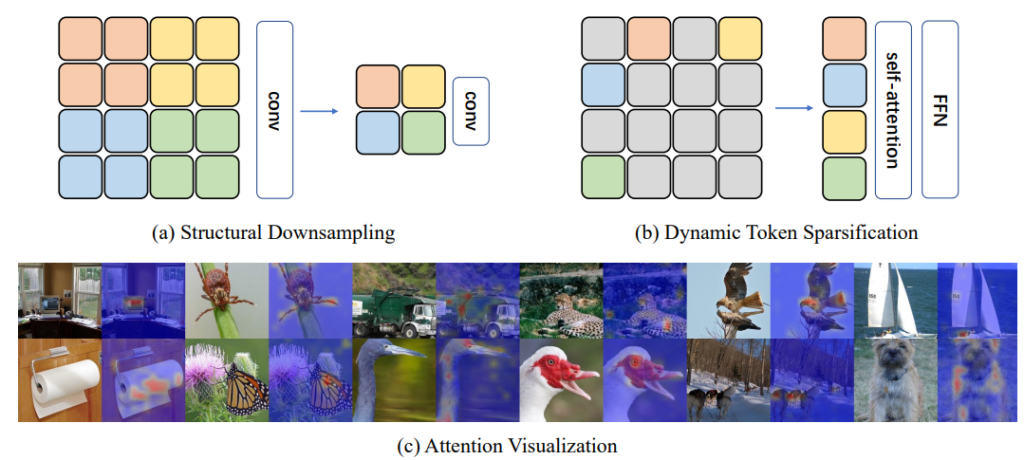
Fig 3-(a)가 기존 CNN 구조에서 흔하게 볼 수 있는 연산과정이었다면, 지금 설명드릴 DynamicViT의 token sparsification 과정은 Fig 3-(b)와 같이 나타납니다. 이는 한번에 결정되는 것이 아닌 여러번의 계층적인 반복을 거치며 token 중 drop시킬 token을 선정하여 Decision mask \hat{D} \in (0,1)^N 를 매 token 별로 지니게 됩니다. 또한 Initial Decision mask는 1로 시작합니다.
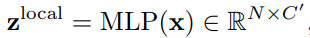
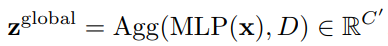
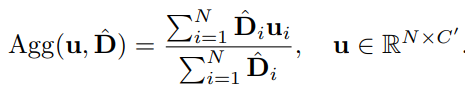
Prediction module에서는 앞선 backbone network에서 생성된 token feature x와 Decision mask를 입력으로 식 (1)과 같이 z^{local}, z^{global} 을 만들어 내게 됩니다. 식 (1)의 첫번째 식과 같이 크기가 NxC (token num of one image x dim)인 token feature x를 입력으로 각각 두어 MLP Layer에서 연산하여 크기가 NxC’인 z^{local}를 만듭니다. 여기서 C’은 C/2를 의미합니다. 이와 유사하게 global feature인 z^{global} 를 연산하기위해 Decision mask에서 1로 나타난 위치들의 평균을 내주는 Agg 함수로 average pooling을 취합니다.
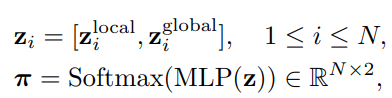
이후, 특정 token을 표현하는 local feature z^{local}와 한 이미지 전체를 표현하는 global feature z^{global}를 묶어 MLP 연산을 하는 local-global embedding 과정을 통해 drop or keep 여부를 예측하게 됩니다.
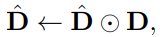
이후 i번째 token의 drop 여부와 keep 여부는 각각 \pi_{i,0}, \pi_{i,1}로 표현되며, 식(3)과 같이 새롭게 \pi 로부터 생성된 Decision mask \hat{D}와 기존 Decision mask D와의 Hadamard product 연산을 통해 새로운 Decision mask \hat{D}을 update 하게 됩니다. 여기서 Hadamard product는 동일한 크기의 matrix에서 동일한 위치의 원소 곱을 의미합니다.
1.3 End-to-end Optimization with Attention Masking
앞서 설명드린 Prediction module에서 attention masking 하는 방식을 End-to-End로 학습하기 위해 저자는 다음과 같은 두가지 문제를 해결하였습니다.
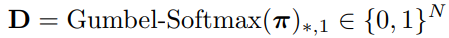
첫번째로는 \pi로부터 Decision mask D를 생성하는 과정을 미분가능하도록 설계하고자 식(4)와 같이 Gumbel Softmax 연산을 적용하였습니다. Gumbel Softmax는 Softmax가 미분가능하도록 근사한 방법입니다.
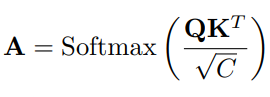
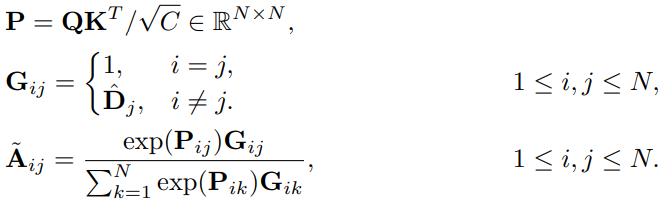
두번째로는 Decision mask D에서 drop으로 선정되는 token의 수가 일정하지 않아, 연산 시 만약 drop에 해당하는 token을 drop시키고 나머지 token만 단순히 연산하게 되면 불규칙한 입력 개수로 병렬 연산하기 힘들기에 식 (5)와 같았던 연산을 식 (6)으로 변경해 연산을 진행하였습니다. Query, Key vector로 연산하는 과정은 병렬 연산의 편의성을 위해 모든 token feature에 대해 연산하되 결과값으로 나온 matrix에 Softmax 연산 적용 시, Decision mask를 통한 masking으로 drop 시켰습니다.
1.4 Training and Inference
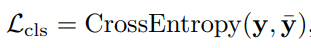
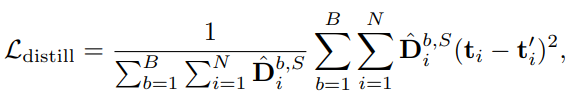
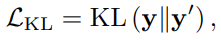
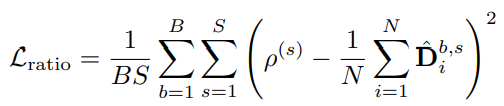
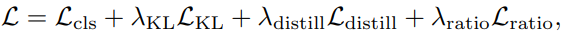
DynamicViT 학습 시, Prediction module이 prediction을 잘하도록 만드는 것이 목표이기에 모델에서 나온 출력값에 일반적인 CrossEntropy Loss(7)를 적용하였습니다.
그리고 DynamicViT에서 모델 가속화를 위해 attention masking을 진행하는 과정이 학습을 저해하는 것을 막고 최대한 backbone network와 동일하게 성능을 보이고자 backbone network를 teacher로 두고 식 (8)과 같은 Distillation Loss도 적용하였습니다. 여기서 t_{i}와 t_{i}'는 Dynamic ViT와 teacher newtork의 마지막 attention block을 통과한 i번째 token feature 입니다. 이는 prediction module 전후의 표현력을 유사하게 만드는 self-distillation에 해당하며, 이전 리뷰에서 다루었던 visual cloze task와 유사합니다. 이처럼 teacher network와 비슷한 성능을 보이게 하기 위해 feature-level에서의 optimization 뿐만아니라 prediction-level의 optimization을 식 (9)와 같이 KL divergence로 적용하였습니다.
마지막으로 Decision mask를 선정하기위해 여러번 반복하며 masking을 진행할 때, 각 반복 별로 사전에 정해놓은 비율에 맞게 masking을 진행하고자 식 (10)과 같은 Ratio Loss를 적용하였습니다. 여기서 \rho^{s}는 사전에 정해진 s번째 반복의 masking ratio 입니다.
위와 같은 세가지의 Loss를 각각 \lambda{KL}=0.5, \lambda{distill}=0.5, \lambda{ratio}=2의 가중치로 합하여 최종 Loss를 설계하였습니다.
Inference 시에는, Prediction module 내의 매 반복에서 \pi_{*,1}의 값이 높은 순으로 \rho^{s}에 맞게 keep하였습니다.
2. Experiments
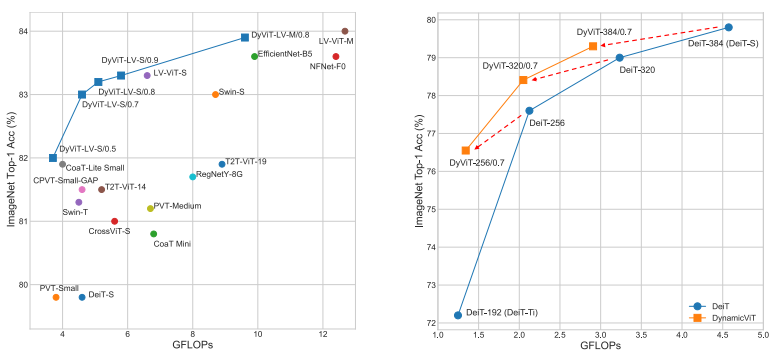
[Right] Comparison of our dynamic token sparsification method with model width scaling.

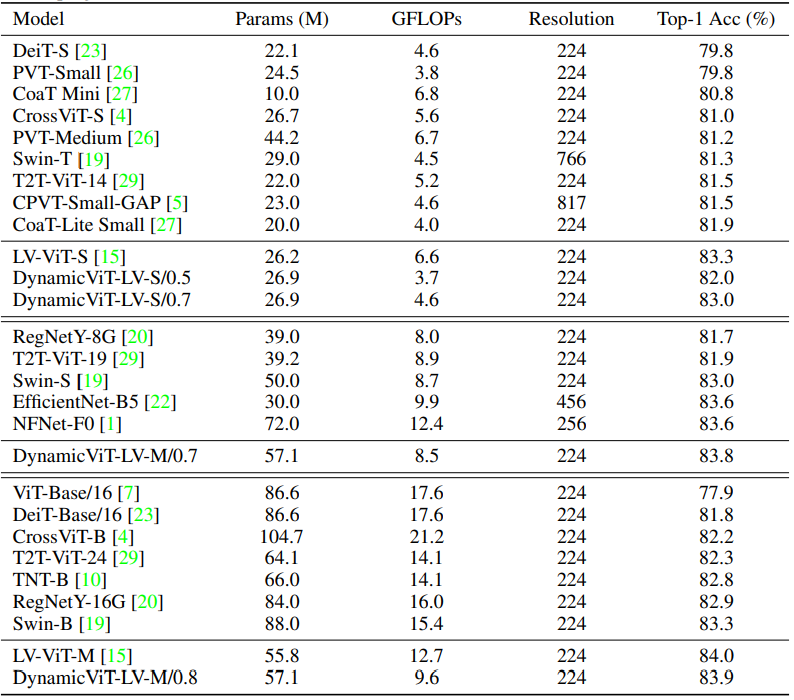
Table 1과 Fig 4는 다른 SOTA와 DynamicViT의 성능 비교입니다. 주의해서 봐야할 점은 다른 비슷한 성능대의 방법론들과 비교했을 때 GFLOPs가 낮다는 점입니다. 이를 통해 제안된 방법론의 Attention masking 방식이 효율면에서 뛰어나다는 점을 알 수 있습니다. 그리고 DynamicViT의 정성적 결과인 Fig 5를 통해 이미지에서 Object를 잘 masking 한다는 부분이 DynamicViT의 효율성에 기여하고 있는 것을 알 수 있습니다.
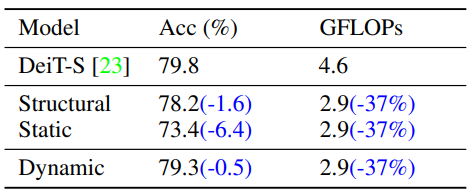
마지막으로 Table 2는 base backbone network로 사용되었던 DeiT-S에 제안된 attention mask을 사용했을 때(Dynamic)와 기존 CNN에서 사용되던 Pooling 방식을 사용했을 때의 정확도 및 GFLOPs를 비교한 표입니다. 제안된 방식이 GFLOPs 면에서는 기존 방법론과 비슷한 수준을 보이나 정확도 면에서 볼 때 기존에는 성능 하락이 심했던 반면 제안된 방식은 baseline과 비슷한 성능을 보였습니다.
3. Reference
[1] https://arxiv.org/pdf/2106.02034.pdf