Before Review
이번 리뷰는 Temporal Localization은 아니고 , Video Retreival에 관련한 논문을 가져왔습니다. Video Retreival을 간단하게 서술하면 Query 비디오를 던졌을 때 이와 유사한 비디오를 searching 하는 Task를 의미합니다. 사실 저도 Video Retrieval 논문을 많이 읽은 것은 아니라 내용을 서술할 때 부족한 부분이 있을 수 있습니다. 이 점 감안해서 읽어주시면 감사하겠습니다.
Introduction
대부분의 Video 관련 논문의 Introduction은 비슷한 거 같습니다. 미디어 콘텐츠 시장의 발달로 인해 content-based video retrieval의 중요성이 날로 점점 증가하고 있다고 합니다. 현재 저희가 자주 애용하는 YouTube , Netflix , Tik-Tok 등의 플랫폼을 생각해보면 , Video 분야의 연구 필요성은 어떻게 보면 자연스러운 흐름인 것 같습니다.
본 논문에서는 그러한 Video Retreival 시에 video 끼리의 유사도를 측정하는 부분의 문제점을 제기하며 이를 video retrieval system의 핵심적인 문제점이라고 지적합니다.
기존의 방법론까지 제가 리뷰를 다룬 것은 아니라 저도 확 와닿지는 않았는데 설명을 해보자면 비디오 Retreival을 하기 위해서 이전의 work들은 비디오의 전체 frame 혹은 일부분을 이용하여 feature를 추출하고 이를 이용해 Video descriptor를 만든다고 합니다. 하지만 이렇게 Video 간의 Similarity를 고려하지 않고 Video descriptor를 만드는 것은 Video 간의 시공간적인 관계를 잃게 만든다고 합니다. 이 부분에 대해서는 기존의 연구가 어떻게 이루어졌는지 확인을 해봐야 어떤 의미인지 깨달을 수 있을 것 같습니다.
우선은 ViSiL의 경우는 Video descriptor를 만들고 유사도를 비교하는 메커니즘이 아니라 , Similarity map을 가지고 inference를 하는 구조입니다.
논문을 읽으면서 조금 특이하다고 생각했는데 ViSiL은 Video 간의 Similarity map을 만들어주고 이를 Network에 던져서 학습을 진행한다고 합니다. 이렇게 설계를 해주면 시각적 유사성의 spatial(intra-frame) , temporal(inter-frame) 구조를 모두 고려해줄 수 있다고 합니다.
Preliminaries
본 논문의 내용을 이해하기 위해 사전적으로 알아야 하는 개념들을 설명하도록 하겠습니다.
Tensor Dot(TD)
고차원의 Tensor끼리 Dot Product를 설명해주고 있습니다. 처음에는 조금 헷갈렸는데 좀 만 생각해보니 어렵진 않았습니다.
연산하려는 두 Tensor의 차원 중에서 길이가 같은 축은 적어도 하나 존재해야 합니다. 즉 , 어느 축으로 dot product 하는 것은 상관없지만 , 그 축의 차원은 동일해야 한다는 점입니다.
- A\in R^{N_{1}\times N_{2}\times K}
- B\in R^{K\times M_{1}\times M_{2}}
Tensor A , B가 차원수가 K인 축을 하나씩 포함하고 있습니다. 이 축을 중심으로 내적을 해주면 어떻게 될까요? dot product는 벡터와 벡터를 받아와서 하나의 스칼라 값을 반환해줍니다. 따라서 Tensor Dot을 해주면R^{N_{1}\times N_{2}\times M_{1}\times M_{2}} 이렇게 되겠죠?
- C=A\cdot_{(i,j)} B
- C\in R^{N_{1}\times N_{2}\times M_{1}\times M_{2}}
이 Tensor Dot이 등장한 이유를 생각해보면 , Video가 3D data이다 보니 , 이러한 Tensor Dot을 사용하지 않았나 싶습니다.
Chamfer Similarity(CS)
처음 보는 개념이었습니다. Chamfer Distance와 대비되는 개념이라고 소개는 되어 있습니다. Chamfer Distance가 무엇인지는 찾아봤지만 , 이해가 잘 안 갔습니다.. 하하 아무튼 Chamfer Similarity를 소개해보면
- CS(col,row)=\frac{1}{N} \sum^{N}_{i=1} \max_{j\in [1,M]} S(i,j)
수식으로 보면 위와 같은데 , 설명을 해보자면 similarity matrix S\in R^{N\times M}이 있을 때 각 Row 별로 최댓값만 추출해오면 길이 N의 1D vector가 생성될 것이고 , 그 Vector들의 원소를 가지고 평균 내준 것이 Chamfer Similarity라고 합니다.
본 논문에서는 Frame to Frame Similarity , Video to Video Similarity를 계산해줄 때 이 Chamfer Similarity를 사용해주게 되고 , 꽤나 핵심적인 개념이니 그림으로도 한번 보도록 하겠습니다.

각 Row 혹은 Column에서 최댓값만 Sampling해와서 1D Vector를 만들어주고 , 1D vector의 원소들을 모두 평균 내준 것이 Chamfer Similarity라고 저자가 정의하고 있습니다.
Triplet Loss
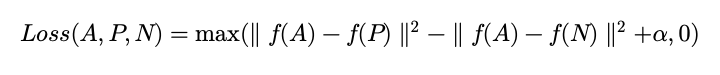
A = anchor , P = positive input , N = negative input
Triplet loss는 baseline인 anchor , positive , negative input들과 비교하는 Loss함수입니다. 여기서 anchor라는 의미가 저는 좀 와닿지는 않았는 데 , 그냥 base input으로 생각했습니다. Positive input은 base input과 같은 class를 의미하며 , Negative input은 다른 class input을 의미합니다.
Base input과 Positive input 사이의 거리는 최소화되는 방향으로 , Negative input과는 거리가 최대가 되는 방향으로 학습이 진행된다고 합니다. 저는 손실 함수를 본 논문을 통해 처음 알게 됐는데 , 보통 워드 임베딩 , 벡터 , 행렬 학습과 같은 유사성을 학습하는 데 사용된다고 합니다.

ViSiL description
자 이제 , 본 논문에서 제안하는 ViSiL이 무엇인지 살펴보도록 하겠습니다.

Feature Extraction
Input으로 Video frame이 들어왔을 때 Feature 추출까지의 과정을 얘기해보도록 하겠습니다.
그림에는 Regional pooling으로 시작이 되어 있습니다. 정확히는 Regional Maximum Activation of Convolution(RMAC)을 적용해준다고 합니다. 논문에는 자세히 설명하고 있지 않아서 찾아보니 max-pooling과 비슷하지만 여러 크기의 Regional로 진행을 해준다고 합니다. 이때 RMAC에 K개의 Convolutional layer가 존재하는 데 각각의 layer를 통과한 Feature map을 Concat을 해준다고 합니다. (Code를 찾아보니 K=9개였습니다.)
그다음으로는 Whitening인데 , 해주는 이유는 설명해주고 있지 않습니다. 찾아보니 Feature들을 uncorrelated 하게 만들어주고 , 각각의 variance를 1로 만들어주는 작업이라고 합니다. 보통 PCA를 해주기 전에 전처리 작업으로 진행해준다고 합니다. Code를 살펴보니 PCA에 처리를 확인할 수 있어서 여기에 사용이 되었음을 추측할 수 있었습니다.
마지막으로 attention을 준다고 합니다. 위의 그림을 보면 whitening 다음으로 l_{2}-norm을 적용해주고 있는 데 , 이 과정에서 영상에 의미 없는 부분들도 동일하게 영향을 미치게 되는 데 attention을 줌으로써 frame의 관심도(saliency)에 따라 weight를 다르게 부여해준다고 합니다. 그렇다면 frame마다 그러한 중요도는 어떻게 정하냐면 다음과 같이 정의합니다.
- weight score : a_{i,j}=u^{T}r_{i,j}
- new regional vector with attention : r^{\prime }_{i,j}=(\frac{a_{i,j}}{2} +0.5)\times r_{i,j}
weight score를 계산해주고 이를 이용하여 새롭게 feature vector들을 정의해준다고 합니다.
weight score를 계산해주는 부분에서 u 는 visual context unit vector라고 해서 random 하게 생성했다가 학습이 되는 구조라고 합니다. 저는 이 부분이 신기해서 Code에서 찾아보니 torch.nn.Linear 이렇게 세팅을 해주고 있었습니다. 아마 각각의 Weight의 제곱의 합은 1로 세팅해주고 학습을 시키는 구조인가 봅니다.
여기까지 해서 Feature Extraction 부분이었습니다. 저는 논문의 설명만 봐서는 이해가 잘 가지 않아 저자가 공개한 Code까지 많이 참고를 하였습니다.
Code : https://github.com/MKLab-ITI/visil
Frame to Frame similarity
이제 서로 다른 두 프레임 간의 유사성을 어떻게 구하는지 알아보도록 하겠습니다.
Feature Extraction을 통해서 regional feature map을 얻을 수 있었습니다. M_{d},M_{b}\in R^{N\times N\times C}
아래의 사진을 보면 이해가 쉬울 텐데 , 길이가 C인 region vectors d_{i,j}b_{k,l}\in R^{C} 끼리 dot product를 해주면 N^{2}\times N^{2} 차원의 2D similarity map이 나올 것이고 이 구해준 similarity map에다가 chamfer similarity 방식을 적용해주면 하나의 scalar값 즉 , 두 frame 간의 유사도를 구해준 것이 됩니다.

이렇게 구해준 frame 간의 similarity는 어느 정도의 spatial invariance를 가진다고 합니다. similarity map에서 최댓값만 Sampling 해주고 평균을 해주기 때문에 공간적인 구조가 조금 바뀌어도 그 값은 영향을 많이 받지 않기 때문입니다.
Video to Video similarity
자 이제 , Video level로 넘어가 보도록 하겠습니다. Video는 간단합니다. 간단한 이유는 사실 비디오는 프레임의 집합이기 때문에 단순히 Frame similarity를 여러 번 적용해주는 것뿐이기 때문입니다.
비디오 Q는 X개의 frame으로 구성되어 있고 , 비디오 P는 Y개의 Frame으로 구성되어있습니다. frame 각각 가져와서 frame to frame similarity를 구해주면 결과적으로 video similarity map은 S_{P,Q}\in R^{X\times Y} 이렇게 정의가 될 것입니다. 논문에는 공식으로도 서술이 되어 있는 데 frame to frame similarity를 그냥 각각의 frame끼리 계산해준 것을 matrix형태로 모아주었다고 보시면 됩니다.
이렇게 구해준 Video 끼리의 Similarity map을 CNN에 넣어주게 됩니다. 즉 , Video similarity map을 가지고 학습이 진행된다고 보시면 됩니다.

이 Network를 통과해서 얻어진 output을 다음과 같이 정의하겠습니다. S^{\prime }_{P,Q}\in R^{X^{\prime }\times Y^{\prime }}
그러고 나서 최종 Video Similarity score를 구하기 위해 역시나 Chamfer Similarity를 적용해주지만 , 여기서는 그 값들을 [-1,1]로 mapping 해주기 위해 hard-tanh function을 사용해준다고 합니다.

- 최종 Video score : CS_{v}(q,p)=\frac{1}{X^{\prime }} \sum^{X^{\prime }}_{i=1} \max_{j\in [1,Y^{\prime }]} Htanh(S_{Q,P}(i,j))
간단하게 설명하면 , CNN을 통과해서 나온 output에다가 Chamfer Similarity를 통해서 유사도를 구할 것인데 , 각 matrix 값에 Htanh값을 적용해준 것뿐입니다.
이렇게 해서 구해준 Video 유사도 점수는 Temporal Invariance를 가진다고 합니다. frame과 같은 맥락으로 Video에서 frame의 값들이 조금 변해도 그 유사도 값은 크게 영향을 받지 않는 그런 구조입니다.
Loss function
Loss 함수를 살펴볼 것인데 , 아까 위에서 Triplet Loss function을 이용한다고 했습니다.
- positive video 와 base video간의 유사도 점수 : CS_{v}(v,v^{+})
- negative video 와 base video간의 유사도 점수 : CS_{v}(v,v^{-})
결국 , Triplet Loss 함수를 사용한 목적은 base video와 유사한 video라면 높은 video similarity를 가지게 하고 유사하지 않은 video 라면 낮은 video similarity를 가질 수 있도록 하는 것입니다.
또한 regularization loss를 추가해주는 데 이는 Hard tanh 함수에 들어가는 입력이 너무 saturated 않게 끔 해주기 위함이라고 합니다.
- L_{tr}=max\{ 0,CS_{v}(v,v^{-})-CS_{v}(v,v^{+})+\gamma \}
- L_{reg}=\sum^{X^{\prime }}_{i=1} \sum^{Y^{\prime }}_{j=1} \parallel max\{ 0,S_{Q,P}(i,j)-1\} \parallel +\parallel min\{ 0,S_{Q,P}(i,j)+1\} \parallel
- L=L_{tr}+\gamma \times L_{reg}
뒤에 실험 부분에서 Regularization loss를 추가했을 때와 안 했을 때의 성능 차이도 Reporting 되어 있으니 확인하시기 바랍니다.
Experiments
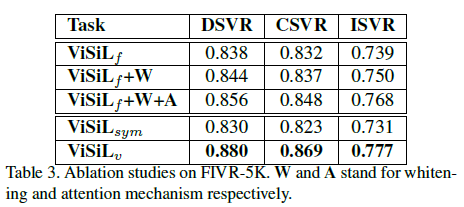
- Ablation Study
ViSiL의 각 파이프라인을 하나씩 추가하면서 실험을 진행했을 때 성능을 비교한 Table입니다.
W는 whitening을 의미하며 , A는 attention mechanism을 적용한 것을 의미합니다.
whitening과 attention을 적용할 때를 보면 성능이 나름 올라가는 것을 확인할 수 있습니다. ViSiL_{v}는 frame level의 similarity가 아닌 video level의 similarity를 계산한 성능이라고 합니다.
Frame level의 base 성능으로부터 추가적인 모듈을 하나씩 붙일 때마다 성능이 개선되는 것을 확인해보았을 때 ViSiL의 파이프라인이 잘 설계가 되었다는 생각이 듭니다.
다음은 위에서 설명했던 similarity regularization loss를 통한 비교분석 실험입니다.
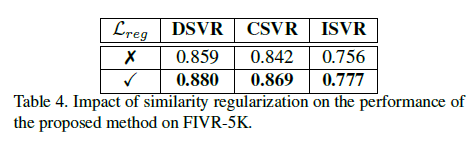
성능이 나름 유의미하게 개선이 된 것을 확인할 수 있습니다.
- Comparison against state of the art
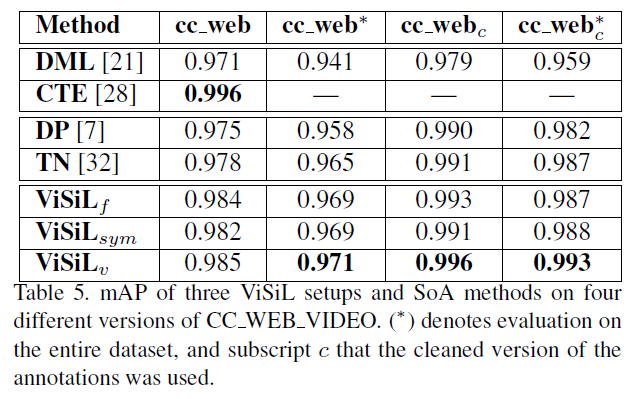
다음은 여러 가지 데이터셋을 가지고 , 각각의 데이터셋의 SOTA 방법론들과의 비교분석입니다.
놀라운 것은 Video Retreival task에서는 dataset의 특성마다 알고리즘이 특정 데이터셋에서는 잘 작동하지만 , 특정 데이터셋에서는 잘 작동하지 못하는 경우가 있습니다. 하지만 본 논문에서 제안된 ViSiL의 성능을 보면 모든 데이터셋에서 SOTA의 성능을 보여주고 있습니다.
Near-duplicate video retrieval(cc_web_video)
Fine-grained incident video retrieval(FIVR-200K)
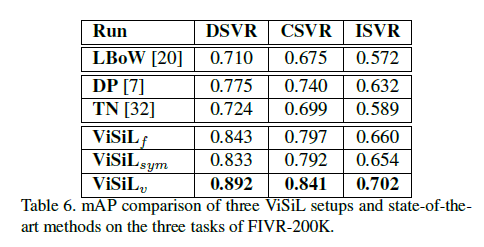
Event video retrieval(EVVE)
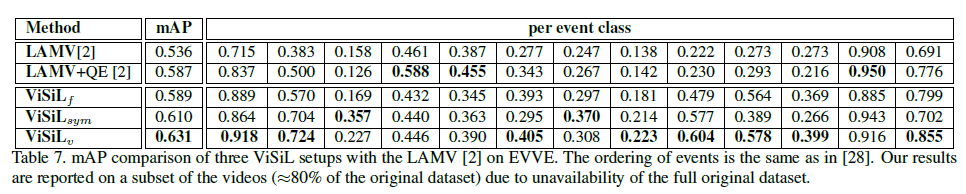
Action video retrieval(ActivityNet)
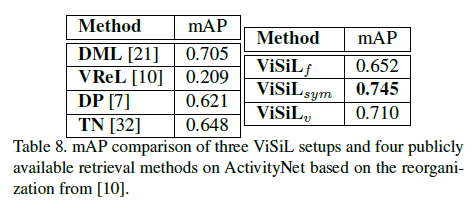
각각의 테이블을 살펴보면 알겠지만 , 각각 데이터셋마다 , SOTA를 찍은 방법론이 다릅니다. 하지만 ViSiL 같은 경우는 모든 데이터셋에서 SOTA의 성능을 달성하고 있고 , 참 General 하면서 Performance가 뛰어나구나(이 정도는 되어야 논문을 쓰는 건가..?) 생각이 들었습니다.
Conclusion
본 논문의 Contribution을 정리하면서 리뷰를 마치겠습니다. 본 논문의 저자는 비디오끼리의 similarity를 학습하는 network를 만들었으며 이 Network는 다음의 특징이 있었습니다.
- regional level의 similarity를 잡아주는 frame to frame similarity를 계산해주는 방법을 제안했습니다.
- video to video의 similarity를 Network에 학습시키는 Framework를 제안하면서 다양한 데이터셋에서 SOTA의 성능을 달성한 것
즉 , Video similarity의 fine-grained spatial 하면서 temporal 한 특성을 고려하는 Video Similarity를 계산하는 방법을 고안했고 , 이것을 학습시켜 Video Retrieval 부분에서 SOTA의 성능을 달성한 것에 있는 것 같습니다.
저자가 밝히는 Future work로는 계산 복잡도를 줄이고 , 또한 제안된 방법들이 다른 분야(video copy detection , video re-localization)에 적용시키는 것이라고 합니다.
논문을 읽으면서 ViSiL이전의 연구 동향에 대해서 읽어 본 적이 없어서 , 저 스스로도 이해가 가지 않았던 부분이 있었습니다. 부족한 이해 부분은 Video Retrieval 논문을 더 읽어보면서 채워가도록 하겠습니다. 리뷰 읽어주셔서 감사합니다.
Ablation Study에서 ViSiL_f는 Whitening과 Attention mechanism을 사용한 성능도 보여주었는데 ViSiL_sym과 ViSiL_v는 이에 대한 내용이 없어 질문 드립니다.
Whitening과 Attention mechanism이 ViSiL_sym과 ViSiL_v에 포함되어 있는 것일 까요?
네 질문해주신 부분을 다시 한번 논문에서 살펴보았는 데
ViSiL_v 와 ViSiL_sym결과에 whitening과 attention mechanisim을 적용했다 라는 직접적인 언급은 없었습니다.
일부러 Reporting을 하지 않은 것인지 , 포함했지만 언급을 안 한건지는 확실하게 대답을 드릴 수 없을 것 같습니다.