안녕하세요 이번주 x-review 주제는 평소에 다루지 않았던 주제를 가지고 왔습니다. 해당 리뷰를 작성하게된 이유는 이번 하계 논문 주제로 Domain Adaptation(DA)을 다루기로 했기 때문입니다. DA 에서도 엄청나게 유명한 논문인 DANN으로 이미 블로그, 관련동영상 등 공개된 소스들이 참 많습니다. 제가 쓴 리뷰는 김지원연구원의 추천을받아 해당 블로그글을 참고하고 작성하였습니다.
음 우선 DA는 처음인데 제가 이해한선에서 DA 에 대해서 먼저 소개하겠습니다. 아마 많은 연구원들이 DA를 들어보았고, 일부는 처음들어보았을 수도 있다고 생각합니다. 처음 들어본 분들이 제 글을 읽는다고 가정하고 좀 자세히 설명해드리겠습니다.
우선 DA는 도메인이 서로 다르나 완전히 다르지는 않을때 사용하는 방법론입니다. 이렇게만 들으면 좀 정의가 모호한데 예시를 생각해보면 이해가 빠릅니다.
영화리뷰가 긍정적인지 부정적인지 자동으로 판단하는 모델을 설계하였다고 해봅시다. 이 모델을 그대로 사용해서 상품리뷰가 긍정적인지 부정적인지 판단하는데 활용하였다면 과연 제대로 작동할까요? 이와 같은 경우가 바로 도메인은 다르나 분포가 비슷한 task에 해당합니다. 이처럼 DA는 train과 test의 분포가 약간 다르나 Prensence of shift가 존재할 때 사용가능합니다. 말이 좀 어렵게 들리는데 위의 예시를 다시 생각해보면 쉽게 이해할 수 있습니다. 위에서 영화리뷰만을 학습하고, 상품리뷰로 test를 하였을때, 도메인이 달라졌으나 분포는 비슷하므로 Presence of shift가 존재합니다. 위와 같은 경우에 사용할 수 있는 것이 바로 DA 입니다. 즉, 기존에 알던 지식인 영화리뷰를 활용해서 새로운 문제를 해결하는 것입니다. 그리고 이렇게 기존의 지식을 활용하는 것을 knowledge transfer이라고 하며 DA의 핵심 컨셉입니다.
사실 DA컨셉은 1900년대 후반부터 있던 방법론 입니다. 과거에는 linear 한 feature에 대한 representation만이 다루어졌는가하면 현재에는 non-linear한 feature 도 다룰 수 있을만큼 학문이 발전을 이루어 왔습니다. 그 대표적인게 linear한 레이어를 쌓아서 non-linear를 해결한 바로 DNN기반 feature representation 입니다.
그렇다면 해당 논문에서 소개하는 DA기법은 왜 유명하고 기존의 DA 기법들과 무엇이 다를까요? 이러한 배경적인 지식이 있는 상태에서 해당 질문에 대한 답변을 생각하며 읽으면 좀 더 도움이 되리라고 생각합니다.
먼저 기존의 DA 방법론들은 fixed feature representation 하는 방식을 사용하였으며 대표적으로 두갈래로 나뉩니다,
1.source 도메인을 reweighing하여 target 도메인과 비슷하게 만드는 방식을 사용
2. 소스도메인 ——–(Feature space transformation)———-> 타겟도메인
그러나 이러한 방식은 feature representation 자체를 바꾼다기보다는 feature representation을 이미 뽑은 상태에서 해당 값을 바꾼다는 점에서 한계가 있었습니다. 이번에 소개드리는 논문인 DANN 에서는 feature representation 값 자체를 바꾸기 때문에 기존의 방법들과는 차별성이 있습니다.
또한, DANN에서는 deep feature learning과 DA 과정이 한개의 학습과정안에서 진행됩니다. 기존의 방법론들에서는 feature representation값을 구한 후 이를 이용하여 또다른 연산이 필요했기 때문에, DANN이 큰 이점을 가집니다.
DANN에서는 이 밖에도 GAN 에서 소개된 컨셉을 활용한다는 장점이 있습니다. 사실상 위에서 말한 장점들이 가능했던 이유도 GAN 에서 사용한 discriminator를 사용했기 때문입니다. 논문에서 이렇게 contribution들을 나열하여 주장하는데 사실 contribution 들끼리 좀 중복되는 느낌은 있는거 같습니다. 아무튼 discriminator를 학습할때 사용하고, 해당 discriminator는 feature representation의 도메인이 target 인지 source인지 분별하는 역할을 합니다. 이때, DA을 위해 해당 discriminator가 분별을 잘 못하는 방향으로 학습을 합니다. 즉, source 인지 target인지 잘 분별을 못한다는 소리이므로, 도메인간의 gap이 줄어들게 됩니다.
일단 여기까지가 해당 논문인 DANN 의 기본 컨셉과 나오기까지의 배경입니다. 여기까진 내용이 어렵지 않았으나, 이후 내용은 수식적으로나 이론적으로나 어려운 내용들이 많이 포함됩니다. 차근차근 풀어가봅시다.
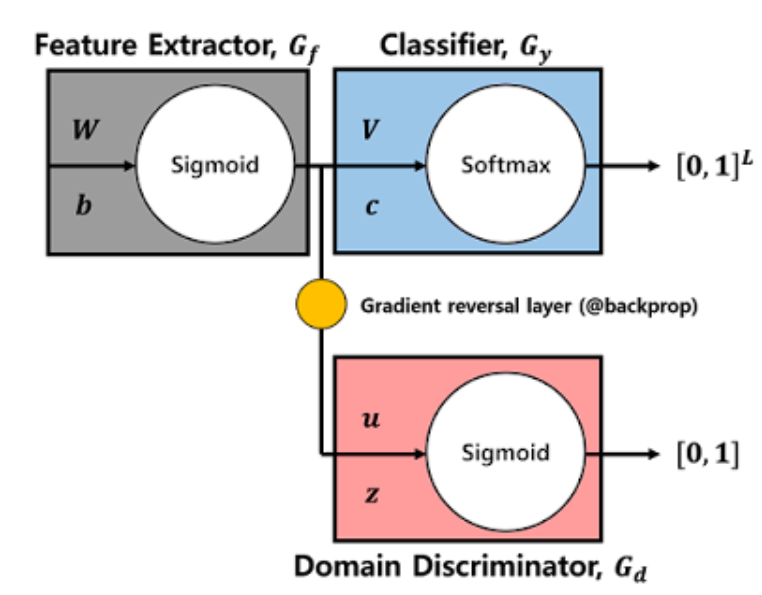
먼저 DANN의 전체적인 파이프라인입니다. 크게 복잡하지 않으며 직관적입니다. 특이점이라면 Domain Discriminator가 사용되었단 거고 해당 판별자는 도메인이 source인지 target 인지 판별하는 역할을 합니다. 그리고 해당 판별자가 판별을 잘못하는 방향으로 학습시키기위해 Gradient reversal layer를 사용합니다. 즉, 기존 인공지능 문제들에서는 loss를 minimize하는 방식으로 학습을 했다면 Gradient reversal layer를 사용하여 maximize하는 방식으로 학습을 하게됩니다.
위에서 보시면 아시겠지만, 아키텍쳐가 생각보다 간단하며, 기존에 존재하는 모델들에 갖다 붙혀 쓰기 좋다는 장점을 가집니다. 논문에서 말하기를 SGD와 backpropagation 기법이 들어가는 인공지능 모델이면 Any model에나 적용 가능하다고 하는데 정말 좋은 장점인거 같습니다.
비록 아키텍쳐는 간단하지만 이론적인 내용이나 수식은 그리 간단하지 않은데 지금부터 중간중간 헷갈릴 수 있는 용어에 대해서 정의해가며 차근차근 이해해봅시다.
Domain Divergence: 도메인의 발산? 이라고 해석이되는데 무슨 뜻일까요? 이는 source도메인과 target 도메인간의 괴리감이라고 생각하시면 될거 같습니다. 즉, source 도메인과 target 도메인간의 차이가 심할수록 Domain divergence값이 커지게 됩니다.
DA의 궁극적인 목표는 source 로부터 지식을 쌓아서 knowledge tranfer를 하여 target 도메인에서도 좋은 결과를 내는 것 입니다. 즉, 다른말로하면 Target Error를 줄이는 것이 최종 목표입니다.
이때 Target Error 는 Source Error와 Domain Divergence의 합으로 나타낼 수 있습니다.
Target Error = Source Error + Domain Divergence
말이 어려운데 위에서 정의한 내용들을 생각하면 이해할 수 있습니다. 말로풀어 설명하면, DA 의 궁극적인 목표인 Target Error 를 줄이기 위해서는 먼저 사전지식을 쌓기위해 학습하는 Source에서의 Error가 적어야합니다. 그리고 도메인간의 차이인 Domain Divergence가 적어야합니다.
말로 풀어쓴 컨셉은 이러한데 이를 수식화 하여 나열하였으며, 실제 논문에서 다루는 수식은 그리 간단하지 않습니다. 예를들어 저 위에서 Domain divergence로 논문에서는 H-divergence라는 divergence를 사용합니다. 이제 이러한 디테일에 대해서 차근차근 알아가봅시다.
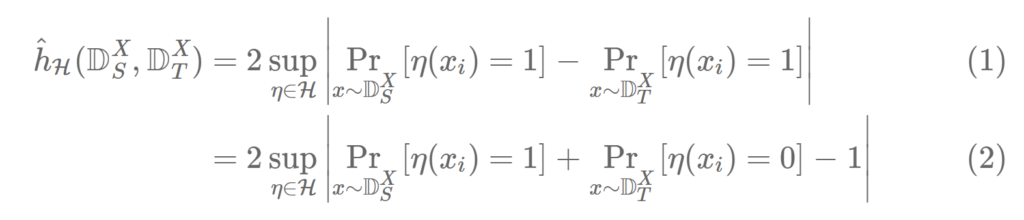
수식이 좀 복잡해보이는데 우선 notation 부터 설명해드리겠습니다. 먼저 좌항은 H-divergence라고 해당 논문에서 정의한 용어이며, h^틸다_H는 Source 도메인과 Target Domain의 x를 인풋으로 가지는 함수입니다.
sup는 상한치라는 뜻이고, 에타는 classifier를 뜻하며 H라는 스페이스의 원소입니다. Pr은 target risk값 입니다.
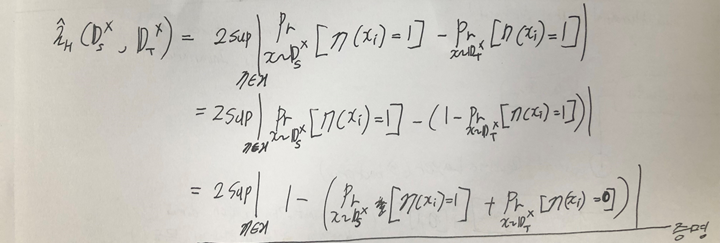
음… 수식기로 일일히 쓰기 번거로워서 펜으로 작성하였는데 시간여유가 될 때 나중에 수식기로 입력하여 바꾸어 두겠습니다. 아래 3가지 사실을 생각하며 위의 수식을 이해하려하면 이해할 수 있을거라고 생각합니다.
- 위의 값에서 Pr[*] 항이 도메인이 source도메인일때는 0이면 맞춘것이고, target일때는 못맞춘 것 입니다.
2. 확률에서는 “맞춘확률 = 1 – 못맞춘확률” 과 같은 식이 성립합니다.
3. 절댓값 안에는 -를 곱해도 결과가 동일합니다.
결과론적으로 H-divergence는 2*max(1-도메인을 못맞출확률) 값이 되게 됩니다. 그리고 이는 다른말로 2*max(도메인을 맞출 확률) 이라고 할 수 있습니다.
아까 위에서 DA의 궁극적인 목표는 Target Error를 최소화 시키는 것이고,
Target Error = Source Error + Domain Divergence 로 정의된다고 했습니다.
우리는 이제 Domain Divergence인 H-divergence값을 알며 Target Error를 줄이기 위해서는 H-divergence 또한 줄여야 한다고 인지하고 있습니다. 즉, DANN에서는 H-divergence인 2*max(도메인을 맞출 확률)을 최소화 시키는 방향으로 학습을 하게됩니다.
DANN을 제대로 이해하려면 Statistical Learning Theory를 이해해야합니다.
Statistical Learning Theory에서 아래와 같은 수식이 정의되고 사용됩니다,
True Minimum risk의 upper bound = empirical risk + model complexity
이를 풀어서 설명해보겠습니다.
구하고자 하나 알 수 없는 값의 계산할 수 있는 한계 = 경험적 risk + 모델 복잡도
그리고 이러한 개념을 DANN와 매핑시켜보면
True H-divergence = Empirical estimate + model complexity가 됩니다.
위와 같은 수식을 고려할 때, DANN 에서 에타로 정의하여 사용하는 classifier의 개수를 무한대로 높이면 empirical risk는 감소하지만, 모델복잡도는 증가하게 됩니다. 즉 모델복잡도와 classifier space의 capacity 사이에는 trade-off 관계에 있다는 소리입니다.
말이 좀 어려운거 같아서 정리해보겠습니다. 수많은 classifier를 사용하여 도메인간의 차이가 있는지 보고 그중에 가장 도메인간의 차이가 없는 classifier를 사용한다고 해봅시다. 그렇다면, 많은 classifier를 시도해볼수록 empirical risk는 감소하게 되지만 모델복잡도는 더 증가하게 됩니다. 따라서, 어느정도의 empirical risk를 허용하고, 모델복잡도를 줄이는 전략이 필요합니다.
위에서 설명한 내용을 정리하자면, 좋은 DA모델은 작은 True H-divergence와 Empirical classification error를 갖습니다. 이는 사실 맨 위에서한 내용을 좀 더 어려운 말로 적은것 뿐입니다.
Target Error = Source Error + Domain Divergence 라는 수식 기억하시나요?
이때, 좋은 DA모델을 만들려면(Target Error를 줄이려면) Source error는 낮고(Empirical classification error는 낮고) 도메인간의 갭(True H-divergence)은 작아야 합니다.
즉, 결론적으로 Target Error = Source Error + Domain Divergence 라는 수식에 귀결되는데 빙빙둘러 어려운말로 했을뿐입니다.
마지막으로 한가지 더 살펴봅시다. 해당 논문을 이해하기 위해서는 필수라고 생각하여 가지고 왔습니다.
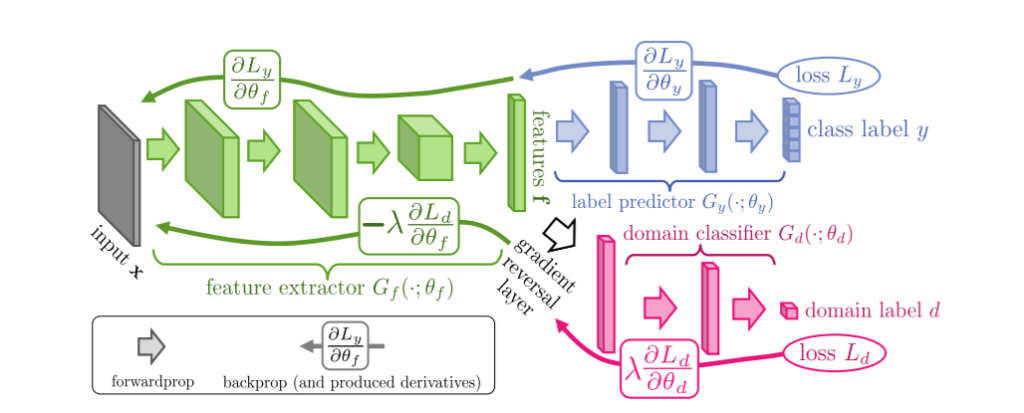
과연 Gradient Reversal Layer가 무엇일까요? gradient를 거슬러 올라간다?… 좀 생소한 개념인데요.
위의 그림에서 직관적으로 표현해줍니다. 먼저, 아시다시피 backpropagation은 loss함수가 있을때 각각의 레이어에서의 weight와 bias값으로 cost function을 편미분하여 구한 gradient에 learning rate를 곱한 값을 기존 weight및 bias에서 빼주어 weight를 업데이트 해나가는 과정을 의미합니다. 그리고 해당 편미분값을 chain rule 계산을 통해 구할 수 있습니다. Gradient Reversal lalyer에서는 Gradient를 구하고, 구한 gradient에 -1을 곱하는 방식으로 gradient방향을 역방향으로 하여 weight및 bias를 업데이트합니다.
즉, domain discriminator는 도메인 판별을 잘하는 방향이아닌 못하는 방향으로 학습이됩니다.
리뷰를 마치며~
개인적으로 매우매우매우 흥미로운 논문이네요. 왜 DA가 최근 화두인지 알거 같습니다. 최근 DA방법론들도 기회가 되면 리뷰 해보겠습니다.
해당 리뷰는 블로그및 논문을 참고하여 이해한 내용을 바탕으로 작성한 글이며, PR 리뷰영상은 아직 시청하지 못했습니다. PR영상을 보고 제가 이해했던 내용과 비교하며 좀 더 깊게 이해한 후 내일 세미나 발표주제로 가지고 가보겠습니다. 긴글 읽어주셔서 감사합니다.
좋은 리뷰 감사합니다 해당논문의 DA loss는 그냥 일반적인 classification loss인가요?
음… 결론적으로보면 그렇다고 볼 수도 있는데요. 컨셉적인면으로보면 H-divergence가 근사화된 값 입니다. 제가 본 파이토치 코드에서는 Cross Entropy 에서 softmax부분이 빠진 NLLloss를 사용햇습니다.
좋은 리뷰 감사드립니다. 참 세상에 똑똑한 사람들이 많은 것 같습니다. 정말 흥미로운 아이디어 인 것 같습니다.
궁금한점은 논문에서 말하기를 SGD와 backpropagation 기법이 들어가는 인공지능 모델이면 다 사용이 가능하다는 내용이 살짝 헷갈려서 그러는 데
결국 DANN의 framework를 MLP 든 , CNN이든 RNN이든 이런것들로 설계해도 잘 작동한다는 의미로 받아들이면 될까요?
네 맞습니다. 어찌됐든, SGD로 optimize 할 수 있는 경우에는 해당 방법론이 적용이 가능합니다. 그래서 최근 Domain Adaptation으로 논문이 쏟아지고 잇는 것 이구요.
제가 리뷰한 논문에서도 DANN과의 성능을 비교하여 궁금했는데, 다소 어려워보여 도전하기 쉽지 않은 논문을 쉽게 설명해주셔서 감사합니다.
특히 Domain Divergence 에 관한 수식은 처음에 봤을 때 이해가 되지 않았는데, 덕분에 한결 이해가 된 것 같습니다.
다만 한 가지 궁금한 점으로는 용어에 대한 질문입니다. 블로그 내용을 비롯하여 제가 리뷰한 논문에서도 empirical risk 라는 용어를 종종 보곤 했는데 왜 empirical 이라는 단어를 쓸까요?
H 스페이스에 있는 classifier의 개수가 유한할때는 계산이 가능하지만, 무한일때는 계산이 불가능합니다. 우리가 실질적으로 알고싶은 H-divergence값은 이 Classifier의 개수가 무한일때인데 계산할 수 없습니다. 비록 정확한 값은 알 수 없지만, upper bound는 statistical learning theory에 의해서 empirical risk와 model complexity 의 합으로 나타낼 수 있습니다. 그리고 H-divergence에서의 empirical risk는 유한한 개수의 classifier를 가질때의 H-divergence가 됩니다.