
이번 리뷰 역시… depth estimation 입니다.
Introduction
요약하자면 1. 기존의 방법론들은 성능이 좋았지만 pixel level에서의 depth 정확도는 좋지 못하다. 이를 해결하고자 2. distilled matting Laplacian loss를 적용하여 물체 경계면의 depth를 정확히 살리고자 한다. 덤으로 3. Neural Positional Encoding(NPE)를 통해 렌즈 왜곡 및 투영 왜곡 등의 고질적인 문제를 완화시키겠다. 4. 네트워크의 구조 변경 및 기존의 single-scale input and multi-scales outputs 입력 방식에서 multi-scales inputs and single-scale output 방식으로 변경시켰다.
로 보시면 될 것 같습니다.
Method
Stereoscopic Image Formation Model
해당 방법론은 self-supervised 방법론들 중 Stereo Image를 통하여 학습하는 방식입니다. 즉 네트워크는 현재 frame에서 앞, 뒤 frame 영상을 만들기 위한 disparity(inverse depth)를 추정하는 것이 아니라, 좌-우 영상을 warping하기 위한 disparity map을 추정하도록 학습하는 것이죠.
하지만 한가지 특이한 점이 있다면, 단순히 1채널의 Disparity Map을 추정하는 것이 아니라, Soft-max한 disparity probability logit volume \bold{D^{PR}_{L}}을 추정하게 됩니다.
이러한 disparity probability volume은 이 논문에서 처음 제안한 것이 아니고 자신들도 SOTA에 해당하는 방법론을 참조하였다고만 했기에 자세한 설명을 다루지는 않습니다만 대략 유추해보자면 기존의 방법론들은 보통 0~1 사이의 값을 가지는 1채널의 disparity map을 추론하는 반면 해당 방식은 다채널의 확률 맵을 만들어서 disparity map을 구하는 방식인듯 합니다만… 논문에서 참조했다는 방법론을 한번 읽어본 후 추후에 내용을 보충하고자 합니다.
아무튼간에 disparity volume을 사용한다는 점 외에는 기존의 monodepth1 방식과 유사하게 left to right disparity map, right to left disparity map을 통하여 image reconstruction 후 실제 target 영상과 비교하는 방식으로 학습이 진행됩니다.
Neural Positional Encoding
저자는 CNN의 local filter가 지역적 위치만을 공유하다보니, 네트워크는 local-specific feature를 학습하는데 어려움이 있다고 합니다. 이러한 local-specific feature란 무엇이냐 하면, lens 또는 projection을 통해 발생하는 왜곡들, 또는 땅과 하늘 지역 그리고 잠재적인 non-local relationship 등을 의미합니다.
여기서 특히 lens와 projection 왜곡은 잘 아시다시피 영상 가장자리에 존재하는 물체들의 외형을 길쭉하게 늘려버리는 현상으로, 영상의 중앙에 가면 갈수록 잘 발생하지 않는 현상을 의미합니다. 이러한 현상은 만일 두 물체가 동일한 거리에 있음에도 불구하고, 단지 영상의 가장자리와 센터에 놓였다는 이유 만으로 다르게 투영될 수 있으며, 이러한 물체의 상대적인 크기는 깊이 추정을 학습하는데 큰 영향을 끼칠 수 있다고 합니다.

왜냐하면, 네트워크는 원본 영상에서 학습하려는 패치의 위치를 이해하지 못하기 때문에(CNN의 local filter의 한계때문이죠?), 물체가 정말로 가까워서 크게 보이는건지, 렌즈 왜곡으로 인해서 크게 보이는건지를 알 수 없기 때문에 거리가 가깝다고 인식할 수 있는 것이죠.
저자는 네트워크가 학습하는 패치 영역이 영상의 가장자리에 가까워질 때 물체가 늘어난다는 것을 알려주기 위해서, neural positional encoding(NPE)를 제안합니다. 해당 NPE는 각각의 encoder stage마다 deep positional feature map을 concatenation함으로써 진행됩니다.
deep positional feature map \bold{F_{npe}}는 어떻게 만들까요? 저자는 pixel location(x, y)를 가지는 패치에 2개의 fc layer와 ELU activation을 거쳐서 만듭니다.
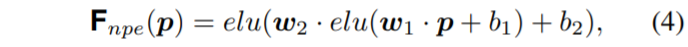
이는 수식(4)를 통해서 표현할 수 있으며, 이러한 수식(4)는 매우 간단하게도 1 x 1 컨볼루션 연산을 통해 코드상으로 구현할 수 있습니다.
Distilling the Matting Laplacian
해당 내용이 제안하는 방법론에서 가장 중요한 파트가 아닐까 싶습니다. 먼저 matting Laplacian은 고전적인 low-level computer vision에서 자주 사용되는 방식으로, 해당 방법론은 입력 영상을 픽셀 명도값을 기반으로 하여 샤프하게 세그먼트를 나누고자 합니다.
이러한 matting Laplacian을 통해 depth map의 경계면을 보다 sharp하게 refine하겠다는 것이 해당 방법론의 큰 목적이겠네요. 먼저 matting Laplacian distillation 과정은 아래 그림2와 같습니다.

입력 영상 \bold{I_{L}}과 이를 통해 초기에 추정된 depth 값 \bold{D'_{L0}}, 그리고 matted disparity는 \bold{D'_{LM0}}로 나타냅니다. 먼저 그림2-(c)를 살펴보시면 \bold{D'_{LM0}}은 매우 sharp한 것을 정성적으로 확인할 수 있습니다만, 많은 픽셀들이 잘못 label 되어있다고 이야기 합니다.
예를 들어서 왼쪽 편에 나무, 영상 중앙 쪽 자전거를 타는 사람, 전체적인 도로 depth등이 구분이 잘 되지 않고 background와 섞여들어간 모습이죠. 저자는 이를 복원해주기 위해 5 x 5 평균 필터를 적용하여 지역적으로 scaled matted disparity map \bold{D'_{LM}}을 생성합니다.
그 다음에는 아래 부등식과 같이 photometric과 left-right consistency를 통해 distillation mask \bold{M_{L}}를 생성하게 됩니다.
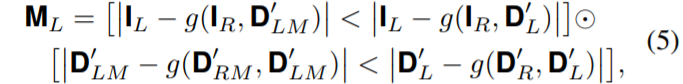
뭔가 복작복작해보이지만 별 내용 없습니다. g는 backward warping operation을 의미하며, \bold{D'_{R0}, D'_{RM}}은 각각 오른쪽 입력 영상에 대한 초기 disparity 값과 locally scaled matted disparity map(그림2-(d))을 의미합니다.
저 수식의 대략적 의미를 나타내자면, 먼저 위에 첫번째 라인은 photometric을 나타낸 것으로, g함수를 통해 오른쪽 영상에 대하여 각각 초기 disparity map과 locally scaled matted disparity map으로 warping 시킵니다. 이렇게 우측에서 좌측으로 warping된 영상들을 실제 왼쪽 영상 단순히 L1 비교를 하게 됩니다.
그리고나서, 저 부등호를 통해 두 warping 결과물과 왼쪽 영상간에 잔차값이 큰 픽셀들을 가져오게 되는데, 이는 초기 disparity map(\bold{D'_{L}})이 object boundary에서 sharp하지 못하기 때문에 해당 픽셀 영역들을 가져오시는 거라고 보시면 될 것 같습니다.
그리고 수식(5)에서 아래 두번째 라인은 left-right consistency를 살피는 것으로, \bold{D'_{RM}, D'_{R}}을 각각 warping하였을 때 Left와 동일해지도록 하는 것이겠죠?
요약하자면, 저자는 네트워크를 통해서 생성하는 초기 disparity map이 locally scaled matted disparity map처럼 object의 경계면도 정확히 구분지어서 추정되도록 학습시키고 싶은 것이며, 이를 위해서 수식(5)와 같은 부등식을 통해 \bold{D'_{LM}}과 다른 픽셀들을 선별하는 distillation mask \bold{M_{L}}를 설계한 것입니다.
Network Architecture
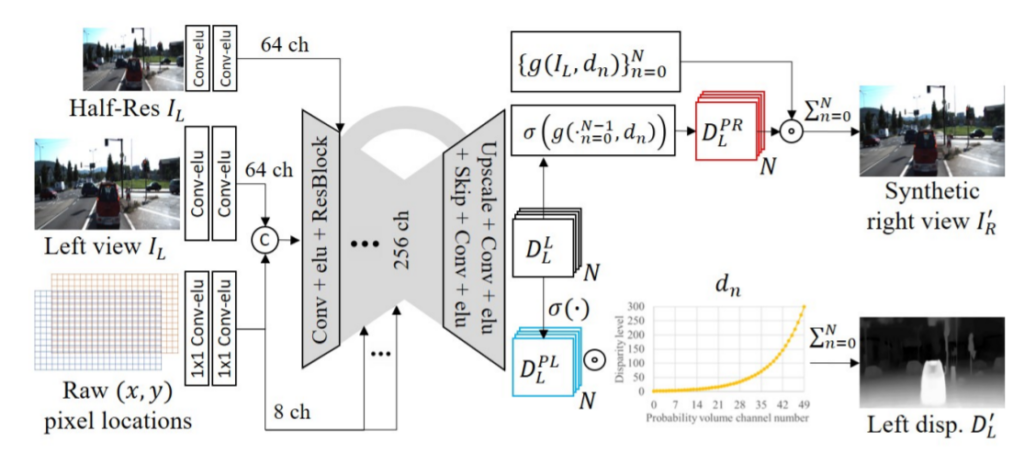
전체 파이프라인은 그림3과 같습니다. 일단 서브섹션으로 설명드린 NPE는 처음 입력과 각각의 encoder stage에서 concatenate가 진행되는 모습입니다.
그리고 기존의 다른 방법론들은 single-scale input , multi-scales outputs 방식으로 모델을 학습시키는 반면, 해당 방법론은 multi-scales inputs, single-scale output으로 모델을 학습시켰다고 합니다. 즉 입력 영상에 대해 bilinear interpolation을 적용하여 2번째 encoder stage 입력에 concat하였습니다.
그 후에 single-scale disparity logit volume을 추론하여 view synthesis 및 single-view depth estimation에 활용합니다.
제안하는 PLADE-Net은 투 스테이지로 학습합니다. 먼저 첫번째는 기존의 stereo input 기반 self-supervised 방법론들처럼 view synthesis를 학습하는 방식으로 그림3에서는 위쪽 파이프라인이라고 생각하시면 될 것 같습니다.
그 다음 두번째 스테이지에서는 위에서 설명한 distilled matting Laplacian loss외에도 deep correlation loss와 첫번째 stage에서 사용한 loss들을 통해 fine tuning합니다.
deep correlation loss는 간략히 설명하면 사전학습된 VGG19에서 비롯된 3번째 max-pool layer를 추출하는 것으로 실제 입력 영상과 추정된 disparity map을 각각 태운 후 k x k 윈도우로 auto-correlation 연산을 수행하여 비교하는 것을 의미합니다.
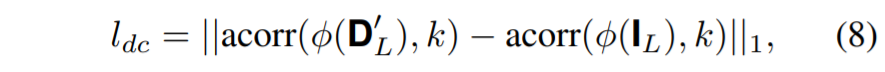
Distilled matting Laplacian loss는 다음과 같습니다.

초기 disparity map에 locally scaled matting disparity map을 서로 빼준다음, 그 중에 수식(5)의 조건들을 다 만족한 픽셀들만을 loss로 활용한다는 의미입니다.
Experiments
다음은 KITTI 데이터셋에 대하여 제안하는 방법론의 Ablation study입니다.
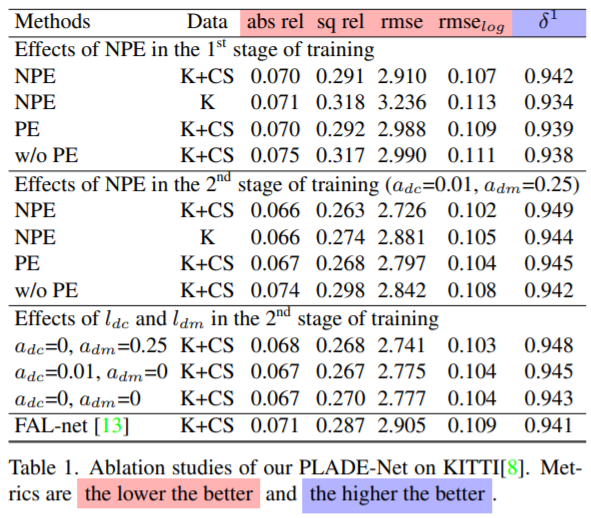
일단 저자가 제안하는 NPE는 얼마나 효과적인가? 에 대해서 먼저 살펴봅시다. PE는 단순히 pixel location을 encoder stage에 concat하였을 때 결과를 나타낸 것으로, PE를 사용하지 않을 때 대비 미세하게 성능이 오르는 것을 확인할 수 있습니다.
저자는 자신들이 제안하는 NPE를 사용하였을 때 PE보다 더 크게 성능이 오른다고 말은 하지만, 음… PE를 전혀 사용하지 않았을 때 보다는 성능이 크게 오르긴 하더라도, PE와 비교하였을 때는 막 드라마틱하다고는 볼 수 없겠네요.
하지만 이러한 PE가 2번째 stage를 학습시킬 때는 반드시 필요한 존재라는 것을 확인할 수 있습니다. NPE 또는 PE 모두를 적용하지 않았을 때 2stage learning에서 큰 성능 향상이 발생하지 않기 때문이죠.
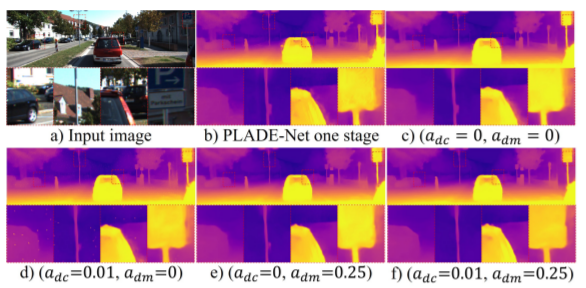
위에는 2stage 학습 시 distilled matting Laplacian loss를 적용했을 때와 안했을 때를 비교한 결과입니다. dm을 적용하지 않은 결과들(b, c, d)의 경우 표지판 주변 경계면이 뚜렷하게 생성되지 않는 모습을 확인할 수 있으며 dm을 사용한 경우(e) 이 현상이 많이 줄어든 모습입니다.
그리고 저자는 자신이 제안한 dm loss를 사용하지 않았음에도 불구하고 FAL-Net보다 더 좋은 성능을 보이는 것에 대하여 자신들이 설계한 모델 구조(multi-scales inputs) 및 NPE가 효과적이라고 주장합니다.
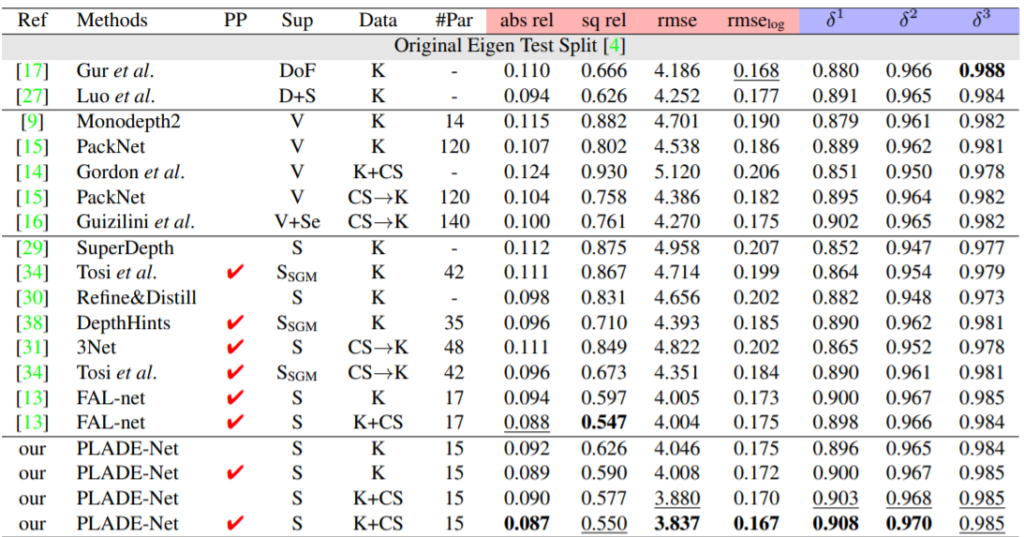
다음은 다른 방법론들과의 정량적 비교 표입니다.
다음은 정성적 결과입니다.
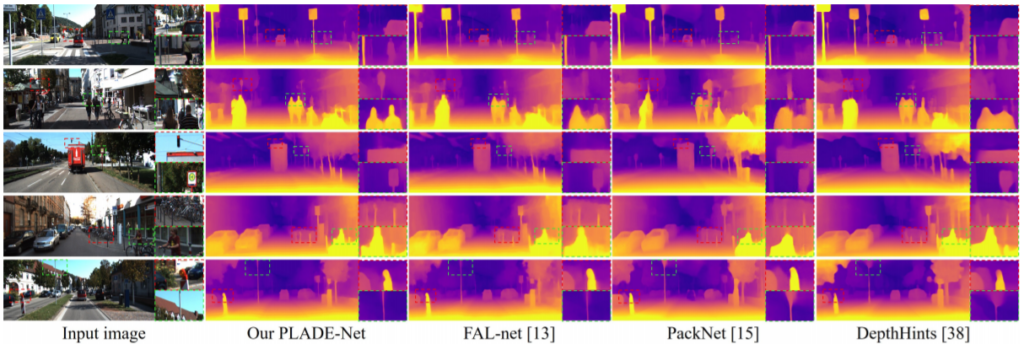
PackNet은 video 즉 앞, 뒤 인접한 프레임을 통해서 학습하는 방식이므로 사실 스테레오 기반의 방법론 대비 성능이 낮을 수 밖에 없습니다. 하지만 FAL-net, DepthHints 방법론들과 같이 stereo 방법론들과 비교하였을 때도 PLADE-Net이 모다 선명한 결과물들을 보여주고 있음을 확인할 수 있습니다.
특히 사람에 대해서 어깨와 얼굴이 정확히 구분되는 모습을 통해 matting Laplacian loss의 효과가 잘 적용된 것이 아닐까 싶네요.
한줄평
깊이 추정을 할 때 물체의 경계면에 대해서 어떻게 강조를 주면 좋을까 고민을 많이 하던 중에 막연하게 image matting이라는 분야의 기술을 접목해봐도 좋지 않을까? 싶었는데 이미 이러한 방식으로 접근한 논문이 있었더군요. 하지만 제안하는 방법론은 matting Laplacian을 통해 distilled mask를 만드려는 과정이 다소 번거롭고 이 때문에 two stage로 학습하는 것으로 보입니다. matting을 통해 depth boundary 성능이 향상되는 것은 보았으니 deep learning 기반의 image matting 방법론을 적용할 수 있는지 검토해봐도 좋을 듯 합니다.
완전 저희가 생각했던 방법하고 동일한줄 알고 식겁했는데 그래도 아니라니… 뭔가 그 저자도 저희와 유사한 생각으로 먼저 실험을 망했을 수 도 있을 것 같다는 느낌이….