오늘 소개드릴 objectron은 3D object detection 데이터셋으로 mediapipe에서 mobile real-time 3D object detection 을 위해 학습 데이터로 사용한 데이터입니다.
오늘 리뷰는 크게 1. 3D object detection을 위해 왜 Video를 사용했는가, 2. 데이터셋은 어떻게 가공되었는가 로 진행하겠습니다.
1. 3D object detection을 위해 왜 Video를 사용했는가


3D object detection을 위해 기존에 데이터 벤치마크를 먼저 소개하며 objectron의 특이점을 찾아보자. 먼저 BOP challenge는 2017년 부터 진행한 6D Object Pose Estimation Challenge 이다. BOP challenge의 데이터셋들은 occlusion이 있으며 매우 정돈되거나 자연스럽지 못한 배경으로 촬영되었다. 또한 Pascal VOC나 ObjectNet3D와 같은 이미지 기반의 데이터셋들은 2D-to-3D alignment 과정을 거쳐 9가 아닌 6-DOF로 어노테이션을 제공하며 카메라의 내부 파라미터를 알 수 없다(여기서 9는 6DOF + 3 “물체의 실제 크기” 를 의미하는 바로 해석하였다). 따라서 물체의 원 크기를 알 수 없다. Depth 카메라나 LIDAR 정보를 제공하는 scene dataset들은 단순 거리는 제공할 수 있으나, 3D pose 정보를 제공할 수 없다. 마지막으로 합성 데이터는 real world 반영 능력을 알 수 없다는 한계가 있다. objectron은 1920X1080 resolution의 large scale을 가진, high-resolution, wild (real world) 데이터이다. 실제로 데이터셋의 품질을 위해 5개 이하의 제한된 품종의 휴대폰으로 촬영하였다고 한다. 물론 위의 특성들은 이미지가 아닌 비디오기 때문에 갖을 수 있는 특성들은 아니다. 비디오가 object detection task를 위해 갖는 가장 큰 장점은 multiple view를 제공한다는 점이다. 이를 통해 물체에 대한 geometric 성질을 더욱 풍부하게 나타낼 수 있다. 또한 비디오는 real word에서 occlution을 피할 수 있는 하나의 도구가 될것이다. 비디오는 다양한 view를 제공한다는 점에서 자연스러운 augmentation을 포함한 데이터로 종종 해석되며, 이러한 특징 덕에 contrastive learning이나 어떤 촬영된 물체의 이해 (ex 기하학적 성질의 이해)를 돕는데 사용될 수 있다. 해당 데이터셋은 real world에서 object centric으로 촬영된 비디오와 함께 camera poses, sparse point-clouds, surface planes 을 제공한다.
2. 데이터셋은 어떻게 가공되었는가

데이터셋은 10개의 다른 국가에서 촬영되었다. 9개의 분류를 가진 (bikes, books, bottles, cameras, cereal boxes, chairs, cups, laptops, shoes) 물품을 두고 카메라가 물체의 주변을 움직이며 10초 정도로 촬영되었으며, 17,095개의 물체를 촬영하였으며 공개하지 않는 evaluation set을 제외한 14,819개의 물체에 대한 3D bounding box(object’s orientation, translation, size relative to the camera pose 정보)와 물체의 실제 크기를 원복할 수 있는 meta data(camera poses, sparse point-clouds, surface planes)를 제공한다. meta data는 AR session을 통해 촬영되었으며 pinhold camera를 가정하여 calibration과정을 통한 카메라의 내부, 외부 파라미터를 모든 프레임에 대해 제공한다. 모든 데이터셋은 특정 기종의 휴대폰 후면 카메라로 촬영되었으며 1920X1080 resolution에 30fps로 촬영되었다. 촬영된 모든 물체는 non-rigid object라도 멈추어 촬영되었으며, 빠른 이동으로 인한 blurry 현상을 예방하기 위해 천천히 움직이며 촬영되었다.

어노테이션은 위와 같은 tool로 진행되었으며 촬영된 연속 비디오와 3D word map을 갖이 제공한다. 작업자가 3D word map에 작업하면 작업한 박스가 camera pose 정보를 이용하여 좌측 영상에 투영되어 나타난다.
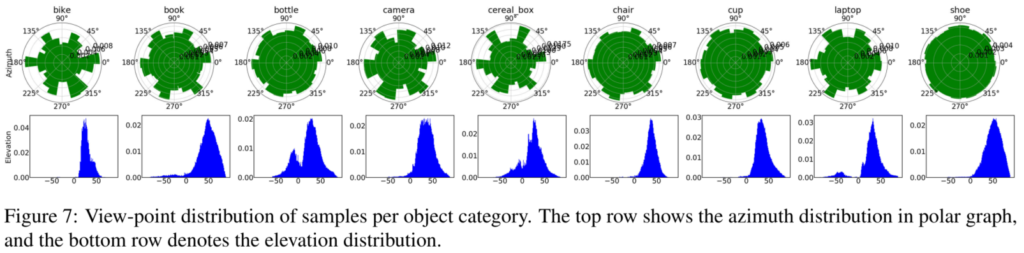
다음은 데이터셋의 촬영 각도와 고도 분포를 나타내며, 촬영자들이 물체를 촬영하기 위해 물체를 비교적 아래에 놓고 물체 주변을 움직여 45 정도로 편향되었지만, 각도의 분포는 편향되지 않아 다양성을 갖음을 알수 있다.
3. 마무리