이번에 리뷰할 논문은 segmentation을 이용하여 depth estimation을 더 잘 해보자는 논문입니다.
연속적 이미지를 이용한 self-supervised monocular depth estimation은 occlusion으로 인해 photometric error에 영향을 줄 수도 있고, ego-motion이 없어 프레임간의 차이가 부족하면 구조 유추를 할 수 없으며 움직이는 물체(차, 사람 등)는 정적 환경이라는 가정에 위배된다는 문제가 있다. 앞의 두가지 문제점은 monodepth2논문에서 제안된 minimum reprojection loss 방법과 auto-masking 기술을 이용하였다.
이 논문에서 제안하는 Self-supervised semantically guided depth estimation (SGDepth)은 세가지 문제 중 세번째 문제인 static-world로 가정된 상황에 위배되는 움직이는 dynamic-class(=DC)를 위한 방법을 제안한다.
- 지도학습 방식의 semantic-segmentation과 self-supervised 방식의 depth estimation의 각 task별 네트워크 head의 cross-domain 학습
- 움직이는 DC 객체가 photometric loss를 오염시키지 않도록 하기 위한 semantic masking 방법
- DC 객체가 움직이지 않는 프레임을 탐지하여 DC객체의 depth를 학습하는 방법
움직이는 DC 객체에 대한 문제를 해결하기 위해서는 픽셀 단위의 인식이 필요하므로 segmentation 기술을 이용하고, depth estimation과 semantic segmentation을 각각의 decoder를 이용해 최적화한다. 이때 <Unsupervised Domain Adaptation by Backpropagation>에서 제안된 cross-domain 학습이 가능한 gradient scaling을 이용하고 이는 각 task별 decoder의 최적의 가중치와 개념을 다른 task로 일반화 할 수 있는 가능성을 만든다.
다른 연구와는 다르게 이 연구는 DC객체로 image projection model을 확장하지 않고 DC 객체에 해당하는 픽셀을 loss로부터 배제한다. 하지만 학습을 아예 하지 않으면 성능이 하락하므로 DC 객체가 움직이지 않는 경우를 탐지하는 방법을 제안하였고, 해당 프레임들(DC객체가 움직이지 않아 static world 상황을 위반하지 않는 경우)에서는 일반적인 방법으로 학습하고 객체가 움직일 경우에는 loss에서 제외한다.
Contribution
- self-supervised depth estimation과 supervised semantic-segmentation의 서로 도움이 되는 cross-domain학습을 task에 특화된 network head로 더 일반적인 setting으로 일반화한다.
- 새로운 semantically-masked photometric loss를 이용해 움직이는 객체에 대한 해결책을 제시한다.
- 움직이는 DC 객체를 감지해 학습시 loss 계산에서 제외시키고, 움직이지 않을 때 학습에 이용되도록 하는 새로운 방법을 제시한다.
Method
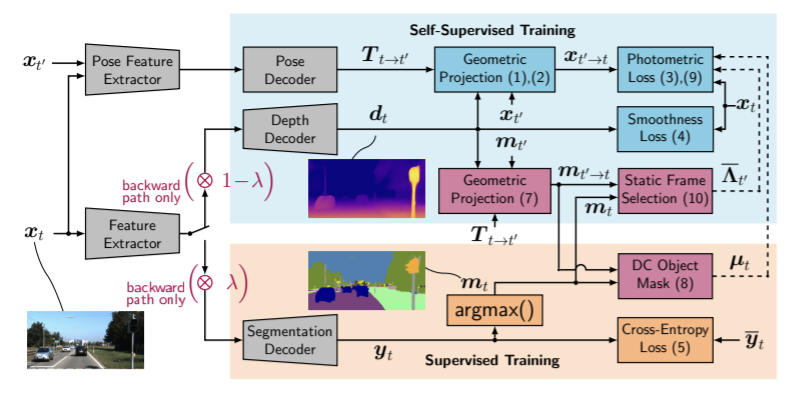
1. Self-supervised Monocular depth estimation
예측된 depth는 t+1로 부터 t 프레임으로의 warping을 위한 기하학적 특성으로 사용된다.
Inference setting
단일 RGB이미지(xt∈GHxWxC)를 입력으로 dense depth map (dt∈DHxW)을 출력으로한다. 이때 D=[dmin, dmax]
Test setting
학습에는 현재 프레임 xt으로 기하학적 와핑되는 앞/뒤 프레임 xt’ (t’∈Ţ‘={t-1,t+1})을 이용한다. 기하학적 변형은 카메라 내부 파라미터 K∈R3×3을 필요로 한다.
또한 pose decoder로부터 예측한 xt와 xt’의 두 연관된 pose, Tt→t’∈SE(3)가 필요하다. 이때 SE(3)은 가능한 모든 rotation과 translation의 세트로 정의된다. 그리고 변환 행렬 Tt→t’은 6자유도를 이용한다.
와핑된 이미지 xt’→t의 픽셀 좌표는 ut 로 변환은 다음 식으로 나타낼 수 있다.
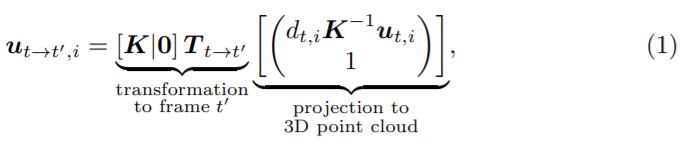
0은 3차원 영벡터이며 오른쪽 부터 3부분으로 해석할 수 있다. 우선 이미지xt의 픽셀 좌표 ut,i (i는 HW)는 3D공간으로 투영된 뒤 relative pose Tt→t’에 의해 이동되고, t’시간의 이미지로 재투영된다. ut→t’과 ut’는 일치하지 않으므로 와핑된 이미지 xt’→t는 bilinear sampling (bil(.))을 이용하여 계산된다.
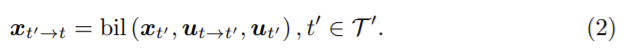
Minimum Reprojection Loss
photometric loss Jtph를 구하기 위해 ɑ=0.85로 하고 per-pixel minimum photometric loss를 이용하여 다음 식을 얻었다.
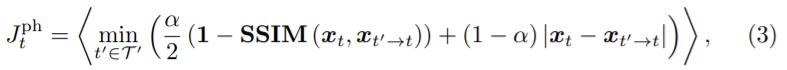
이때 SSIM(·) ∈ IH×W ,I = [0, 1]은 3×3의 이미지 패치로부터 계산된다.
Smoothness Loss
인접한 위치의 픽셀은 유사한 depth를 갖도록 하기 위해, ![]() 로 픽셀 단위로 정의된, mean-normalized inverse depth
로 픽셀 단위로 정의된, mean-normalized inverse depth ![]() 에 smoothness loss Jsm를 적용한다. 그리고 smoothness loss는 다음과 같이 정의된다.
에 smoothness loss Jsm를 적용한다. 그리고 smoothness loss는 다음과 같이 정의된다.
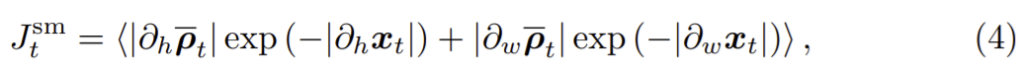
이때 ∂h와 ∂w는 각각 이미지의 높이와 폭 방향에 대한 각 픽셀 위치 ut,i에서 차이 값을 나타낸다.
2. Supervised Semantic Segmentation
픽셀 xt,i에 할당된 라벨 mt,i는 입력 이미지와 출력 score yt∈IHxWxS 로 비선형 매핑된다. 각 픽셀의 인덱스는 i, 클래스는 s일 때 각 요소pt,i,s의 출력 score인 yt는 픽셀 xt,i가 이후에 s클래스에 속할 확률로 생각 할 수 있다. segmentation mask mt∈S는 mt,i = argmaxs∈S yt,i,s로 얻을 수 있고 모든 픽셀에 한 class를 할당할 수 있다. gt와 이후 이후 클래스 확률 사이의 cross-entropy loss를 이용하여 가중치를 부여해 학습한다. 마지막에 모든 픽셀의 평균화하고, loss 함수는 다음으로 정의된다.
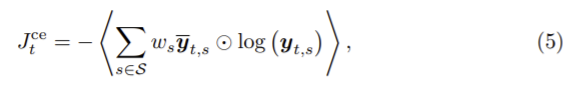
3. Semantic Guidance
이 논문에서 제안하는 semantic masking 방식을 이용해 움직이는 DC객체 문제 해결하기
Multi-Task Training Across Domains
단일 encoder와 2개의 decoder를 이용하고 이때 segmentation decoder는 source domain에서 지도학습(식 (5) 이용), depth의 decoder는 target domain에서 self-supervision으로 학습( 식 (3), (4) 이용)한다. 여기서 두 개별의 디코더에서 공동의 인코더로 어떻게 gradient를 propagate하는가? 이 논문은 gradient의 크기를 조정하는 방식을 이용한다. 그림 1의 gdepth와 gseg가 각 decoder에서 계산된 gradient라 하면 total gradient gtotal은 다음 식으로 계산되어 encoder로 역전파된다.
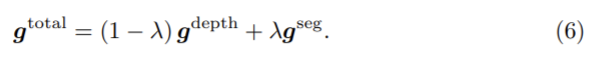
Masking Out All DC Objects

그림2의 (c)에서 확인할수 있듯 움직이는 DC객체는 photometric error를 오염시킨므로 움직이는 모든 DC 객체 뿐만 아니라 두 투영된 프레임으로 잘못 투영된 DC 객체들에 대해 마스킹하여 제외시키고 싶다. 따라서 투영된 semantic masks mt’→t는 다음 식으로 계산한다.
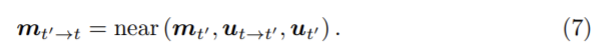
DC 객체를 SDC라 정의하고 DC 객체 마스크 µt∈{0,1}HxW는 i위치가 DC 3 프레임 중 하나가 객체의 부분이면 0으로 나머지는 1로 한다. 또한 식(3)을 변형하여 semantically masked photometric loss를 정의하면 다음과 같다.
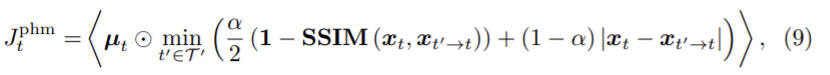
non-DC 픽셀만을 고려한다.
Detection Non-moving DC Objects

DC 객체를 완전 제외할 수 없으므로 객체들이 움직이지 않을 때만 학습한다. 따라서 DC 객체가 움직이는지 움직이지 않는 지 결정해야 하고 DC 객체가 움직이는 것으로 관찰될 경우 target 이미지 내의 semantic mask mt는 낮은 연관성을 가지므로 mt’→t와 mt의 동적 객체 class들의 합집합 분의 교집합을 측정한다.
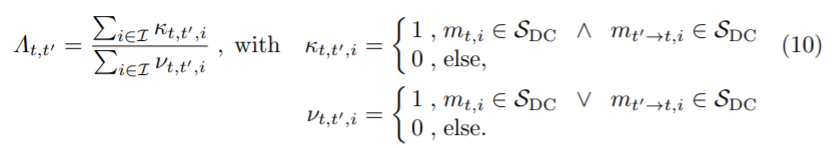
Λt,t∈[0,1]은 1일 경우 움직임이 없는 상태이고 0일 경우 움직이는 DC객체일 확률이 높은 것을 나타낸다. threshold θΛ ∈ [0, 1]로 정의된다.
Learning from Non-Moving DC Objects
각 epoch 이후 마다 이미지가 정적인지 동적인지 측정하여 Λt 바를 계산하고 임계값 θΛ을 선택한다. 최종 loss는 식(9)와 (3), smoothness loss (4), cross-entropy loss(5)를 결합하여 다음과 같은 식으로 얻을 수 있다.
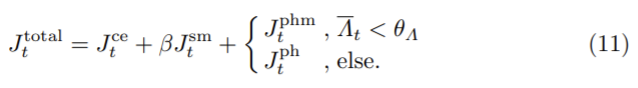
이때 Jtce는 segmenation domain에서 계산되었고 나머지는 depth 학습에 이용되는 이미지만을 계산했다.
Evaluation
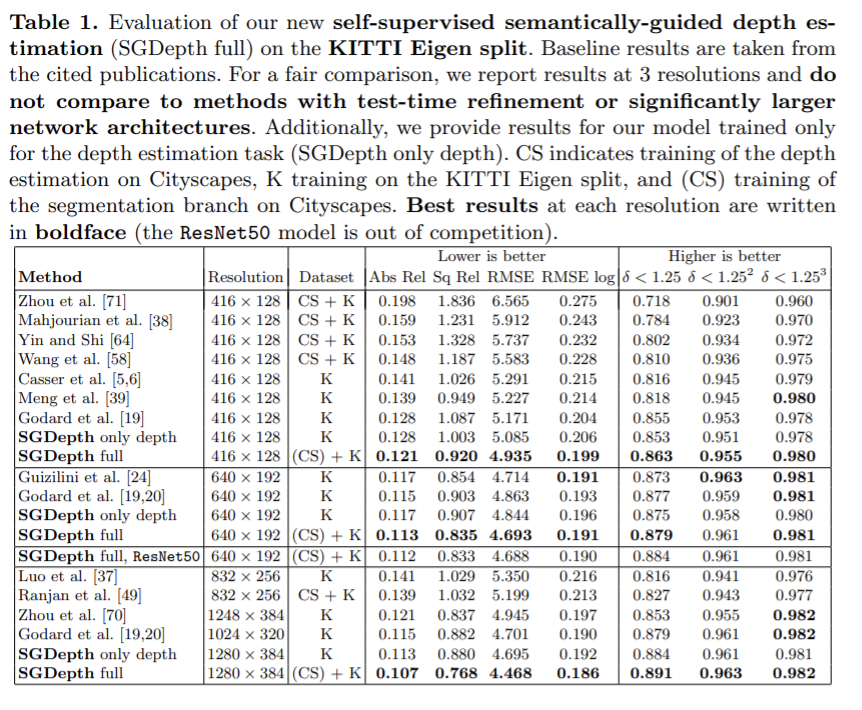
주요 평가는 Eigen split에서 수행되었다. 전체 SGDepth 접근 방법은 모든 baseling보다 좋다. 해상도가 높아질 수록 성능이 좋으므로 3가지 해상도에 대해 결과를 리포팅하였다. 또한 segmentation 없이 self-supervised depth estimation만 학습한 결과를 보았을 때 전체 SGDepth방식을 이용한 것이 성능이 좋다는 것을 보여준다.
다음 정성적 평가를 통해 논문의 방식이 DC객체들의 depth를 분명한 모양으로 잘 추정한 것을 확인할 수 있다. 게다가 신호등 같은 작은 객체를 잘 찾는 것을 확인할 수 있다.

Ablation Studies
다음은 Ablation study의 결과로 전체 SGDepth를 이용한 방식이 대체로 성능이 좋았다.


처음에 제목을 보았을 때 segmentation을 이용하여 움직이는 객체에 대해 새로운 loss를 추가하여 더 잘 배우도록 하는 방법일 줄 알았는 데 내용을 보니 움직일 때는 깊이를 추정하지 않도록 한다는 것이 의외라고 느껴졌습니다. 그리고 DC 객체가 움직이지 않을 때만 깊이를 학습한다고 하는데, threshold가 있더라도 도로에서는 주변 차량이나 사람은 정적인 상태나 동일한 속도로 움직일 가능성이 낮다고 생각되는 데 이러한 경우를 모두 학습에서 제외하면 학습시 학습에 데이터가 부족할 수도 있지 않을까 하는 생각이 들기도 합니다.