또다시 PackNet 을 사용한 논문을 들고 왔습니다. 원래 계획은 VIT 다음 논문을 가져올려했는데 노선을 바꾸고 현재 KITTI dataset에서 SOTA를 보여주고 있는 PackNet-SAN을 들고 왔습니다. 여태까지는 Self-supervised 혹은 Semi-supervised 방식을 depth estimation 방법론들을 들고왔었지만 이 논문은 Supervised 방식이며 Sparse한 Lidar 정보를 학습에 추가하여 Dense한 Depth map을 생성할 수 있도록하고 매우 좋은 성능 향상을 보입니다.
———————-
- Introduction
Monocular depth estimation 에서는 GT를 LiDAR 와 Stereo matching 혹은 SfM을 이용해 구한 Dense Map를 사용하며 각각 장단점이 있습니다. 그 중 LiDAR는 Sparse Depth를 예측하지만 정확한 센서 데이터를 제공하는 장점이 있습니다. 이 논문에서는 이러한 LiDAR의 장점을 더욱 부각하여 RGB 로부터 더욱 정확한 Depth를 예측하는 Network를 제안합니다.
LiDAR 를 활용할 수 있는 상황에서 더욱 정확한 Dense Depth Map을 예측할 수 있는 방식을 제안합니다. 아래 그림과 같이 LiDAR 정보를 활용할 수 있는 Sparse Auxiliary Networks(SANs)를 제안합니다. 이 네트워크는 Sparse Data를 활용할 수 있는 제안하는 Sparse Convolution으로 이뤄져있습니다.
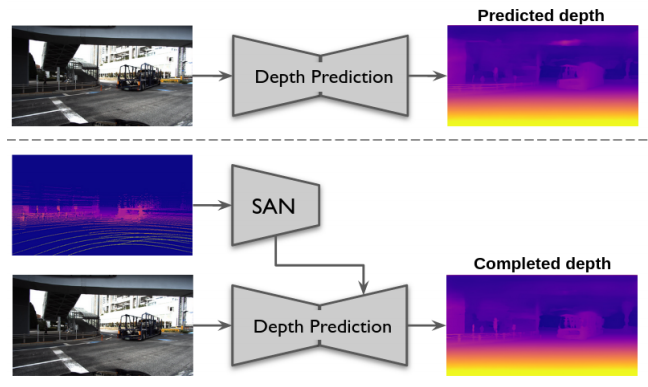
또한 이 방식을 통해 KITTI, DDAD, NYUv2 에서 SOTA 성능을 보여줍니다.
2.Method
Training Loss
Predicted Depth와 LiDAR를 비교하는 Loss는 다음과 같습니다.
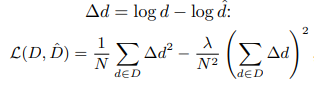
Log scale에서 비교하기 때문에 가까운 Depth 에 대해서 더욱 집중해서 봅니다. 이 로스는 Supervised 방식에서 많이 사용되고 있는 것 같습니다.
Sparse Auxiliary Networks (SANs)
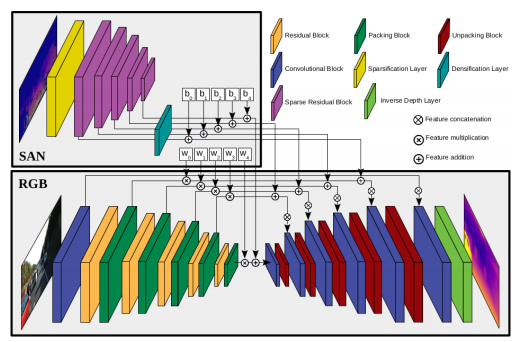
이 논문에서는 위 그림 처럼 LiDAR 정보를 기존 Generator에 넣는 방식으로 성능향상을 보였습니다. 이렇게 LiDAR 데이터를 CNN에 활용하기에는 문제가 있었습니다. 기존 CNN은 Dense data인 Image를 넣었기 때문에 문제가 없었지만 LiDAR는 Image 데이터에 비해서 필요한 데이터가 약 1퍼 정도로 굉장히 Sparse 하기 때문에 기존 CNN으로 그래도 사용하기에는 다음과 같은 문제가 있습니다. (1) 정보가 없는 영역에서 상당한 계산 능력이 낭비됩니다. (2) 공간적 종속성은 이러한 정보가 없는 영역의 쓸모없는 정보를 포함합니다. (3) 공유 필터는 여전히 전체 입력 깊이 맵에서 평균 그레디언트를 포함하여 영향을 끼칩니다.
위와 같은 문제를 극복하기 위해서 이 논문에서는 Sparse convolution architecture을 제안한다. 이때 제안하는 아키텍쳐는 [1]에서 제안된 Convolution을 사용하는 것에 집중했다고 합니다. 간단히 설명하자면, sparse tensor S가 있을때 그것을 다음과 같이 분리할 수 있습니다.
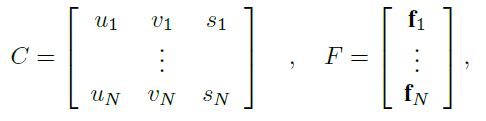
이떄 un,vn은 각 픽셀의 위치 좌표이며 sn은 batch에서 sample index라고 합니다. 이떄 fn은 각 좌표에 해당하는 feature 값이라고 합니다. Sparse Depth D를 Sparse tensor S로 치환하여 대입하면 다음과 같습니다.
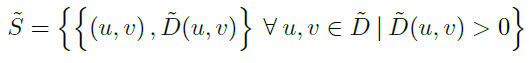
이렇게 Sparse Depth를 다음과 같이 변경하여 C’과 F’을 만들면 Sparse Tensor를 Dense한 Tensor로 변경할 수 있습니다. 이렇게 Sparse한 Tensor의 형태를 Dense한 형태로 변경하는 Sparse Convolution을 이용해서 Depth information을 잘 추정할수 있도록 제안된 Block은 아래그림과 같습니다.
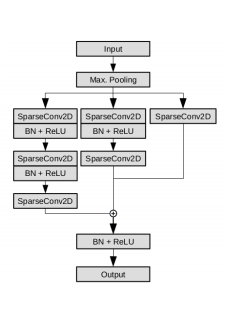
Sparse Convolution을 태울 수록 더욱 촘촘한 공간의 정보를 포함하므로 3개의 parallel 한 branch가 각기 다른 깊이의 공간정보를 포함해서 더욱 강인한 공간 정보를 가져갈 수 있다고 합니다. 이 block을 이용해서 추출한 Sparse한 Depth 정보를 RGB2Depth 모델에 전달해주게 돼서 Depth 예측에 높은 성능향상을 도웁니다.
3. Result
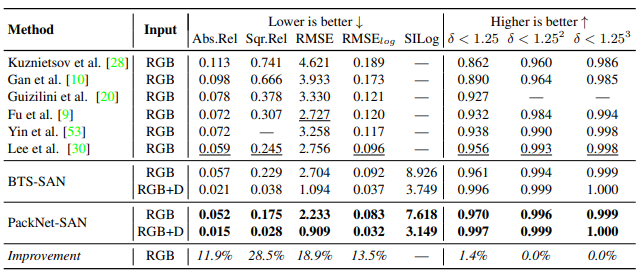
KITTI 데이터셋에서 성능 평가 입니다. BTS와 PackNet에 SAN모듈을 적용했을떄 성능 향상을 보면 확실히 인풋으로 LiDAR를 줘서 그런지 말도 안되는 성능을 보여줍니다.
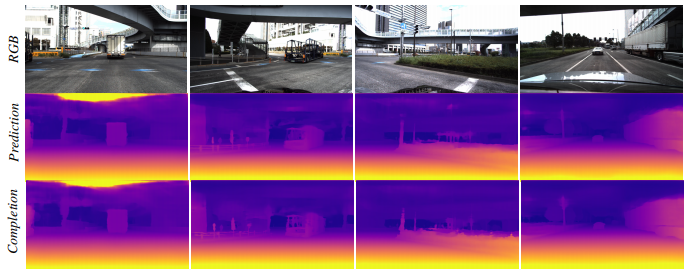
——————–
[1] Choy, Christopher, JunYoung Gwak, and Silvio Savarese. “4d spatio-temporal convnets: Minkowski convolutional neural networks.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.
Input이 들어가고 max pooling을 통해서 3개의 branch로 나뉘는 데 나뉘는 기준은 무엇인가요?
나뉘어서 들어가는 것이 아니고 동일한 입력을 다른 branch들을 통해서 다른 정보를 얻는 것이라 생각하시면 됩니다 .
그동안 Semi-superviesed 혹은 Unsupervised 기반 depth estimation 방법론에 대해 많이 리뷰하셨는데, 왜 노선을 틀어 supervised 기반 논문 리뷰를 하신건지 궁금하네요 허허
Sparse convolution architecture 부분을 설명하는 부분에서 fn은 각 좌표에 해당하는 feature 값이라고 하였으나 제가 잘 이해가 가지 않아 정확히 그 feature 가 무엇인지 자세하게 설명해주시면 감사하겠습니다.
Depth estimation이 어떤 식으로 발전되고 있는지 궁금하기도 하고 너무 두개에 갇혀있는 것 같아서 Supervised를 읽고 리뷰해보았습니다.
아마 feature는 tensor의 값 자체를 의미 하는 것이라 생각합니다. un과 vn이 위치를 나타내고 그에 해당하는 tensor의 값이라 생각됩니다.